Python 官方文档:入门教程 => 点击学习
小编给大家分享一下python中算法的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!1. 算法的设计要求算法分析的主要目标是从运行时间和内存空间消耗等方面
小编给大家分享一下python中算法的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
算法分析的主要目标是从运行时间和内存空间消耗等方面比较算法。
一个好的算法首先应该是“正确”的,其对于每个输入实例均能终止并给出正确的结果,能够正确解决给定的计算问题。此外,还需要考虑以下方面:
高效性:执行算法所需要的时间;
低存储量:执行算法所耗费的存储空间,其中主要考虑辅助存储空间;
可读性:算法应易于理解,易于编码,易于调试等等。
一个算法同时可以满足存储空间小、运行时间短、其它性能也好是很难做到的,很多情况下,我们不得不对性能进行取舍,在实际选择算法时,我们通常遵循以下原则:
若该程序使用次数较少,则力求算法简明易懂;
对于反复多次使用的程序,应尽可能选用快速的算法;
若待解决的问题数据量极大,机器的存储空间较小,则相应算法主要考虑如何节省空间。
算法效率分析根据算法执行所需的时间进行分析和比较,这也称为算法的执行时间或运行时间。要衡量算法的执行时间,一个方法就是做基准分析,这是一种事后统计的方法,其使用绝对的时间单位来记录程序计算出结果所消耗的实际时间。在 Python 中,可以使用 time 模块的 time 函数记录程序的开始时间和结束时间,然后计算差值,就可以得到以秒为单位的算法执行时间。
以计算斐波那契数列第 n 项为例(斐波那契数列从第3项开始,每一项都等于前两项之和),在计算斐波那契数列第 n 项前后调用 time 函数,计算执行时间:
import timedef fibo(n): start = time.time() a, b = 1, 1 if n > 2: for i in range(n-2): a, b = b, a + b end = time.time() running = end-start return b, runningfor i in range(5): results = fibo(100000) print('It takes {:.8f} seconds to calculate the 10000th item of Fibonacci sequence'.fORMat(results[1]))代码执行结果如下:
It takes 0.08275080 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08277822 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08176851 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08178067 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08081150 seconds to calculate the 10000th item of Fibonacci sequence
但是这种方法计算的是执行算法的实际时间,有两个明显的缺陷:1) 必须先运行依据算法编制的程序;2) 依赖于特定的计算机、编译器与编程语言等软硬件环境,容易掩盖算法本身的优劣。因此,我们希望找到一个独立于程序或计算机的指标,以用来比较不同实现下的算法。
为了摆脱与计算机硬件、软件有关的因素,我们需要一种事前分析估算的方法。可以认为特定算法的“运行工作量”大小取决于问题的规模,或者说,它是问题规模的函数,这时我们就需要量化算法的操作或步骤。一个算法是由控制结构和基本操作构成的,因此可以将算法的执行时间描述成解决问题所需重复执行的基本操作数。需要注意的是,确定合适的基本操作取决于不同的算法。例如在计算斐波那契数列第 n 项时,赋值语句就是一个基本操作,而在计算矩阵乘法时,乘法运算则是其基本操作。
在上一节的 fibo 函数中,整个算法的执行时间与基本操作(赋值)重复执行的次数n 成正比,具体而言是 1 加上 n-2 个赋值语句,如果使用将其定义为函数可以表示为T(n)=n−1,其中 n为大于 2 的正整数。n常用于表示问题规模,我们可以使用问题规模 n的某个函数f(n) 表示算法中基本操作重复执行的次数,算法的时间量度可以表示如下:
T(n)=O(f(n))
随问题规模n的增大,T(n) 函数的某一部分会比其余部分增长得更快,算法间进行比较时这一起部分起决定性作用,T(n) 增长最快的部分也称为数量级函数。算法执行时间的增长率和 f(n) 的增长率相同,称作算法的渐近时间复杂度 (asymptotic time complexity),简称时间复杂度。数量级 (order of magnitude) 常被称作大O记法或大O表示法。
通过以上分析,我们可以将算法的渐近复杂度规则描述如下:
如果运行时间是一个多项式的和,那么仅保留增长速度最快的项,去掉其他各项;
如果剩下的项是个乘积,那么去掉所有常数。
假设某一算法的基本步骤数为T(n)=3n2+50n+2000,当 n nn 很小时 2000 对于函数的影响最大,但是随着n 的增长n2将逐渐变得更重要,以至于可以忽略其他两项以及n2的系数 3,因此可以说T(n) 的数量级是n2或写为O(n2)。
算法的性能有时不仅依赖问题的规模,还取决于算法的输入值,输入令算法运行最慢的情况称为最坏情况,输入令算法运行最快的情况称为最好情况,随机输入的情况下算法的性能介于两种极端情况之间,称为平均情况。
下表列出了一些常见的大O表示法实例:
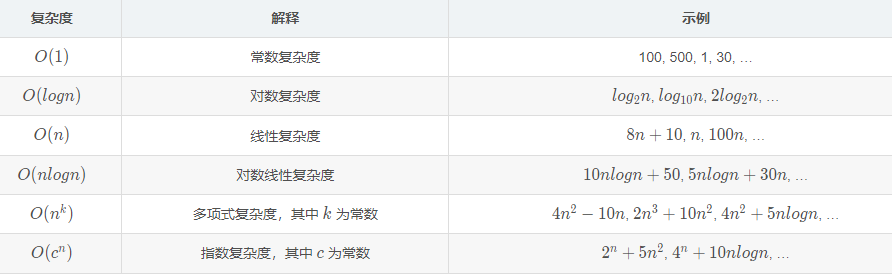
2.1 常数复杂度
常数复杂度表示,算法的渐进复杂度域输入的规模无关,例如求列表的长度等都属于常数复杂度。常数复杂度和代码中是否包含循环没有必然关系,例如循环打印 100 次 “Hello world”,这与输入规模并没有什么关系,因此其也是属于常数复杂度。
2.2 对数复杂度
对数复杂度表示函数的增长速度至少是输入规模的对数,当我们谈论对数复杂度时,我们并不关系对数的底数,这是由于可以使用换底公式,将原来底数的对数乘以一个常数转换为另一个底数:
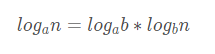
其中,a aa 和 b bb 均为常数。例如以下代码,将一个正整数转换为字符串:
def int_to_str(num): digits = "0123456789" result = '' if num == 0: result = '0' else: while num > 0: result = digits[num % 10] + result num = num // 10 return result上述代码中只包括一个循环,且没有调用其它函数,因此我们只需找出循环迭代次数——在 num 为 0 之前所需的整数除法的次数log10n。因此函数 int_to_str 的复杂度是O(logn)。
2.3 线性复杂度
线性复杂度在列表中等序列数据类型总十分常见,因为算法通常需要遍历处理序列中的每一个元素。例如将列表中的每个元素加上常数 10:
def add_constant(list_o): for i in range(len(list_o)): list_o[i] += 10这个函数的复杂度就与列表的长度成线性关系,也就是O(n)。
2.4 线性对数复杂度
线性对数复杂度是两项的乘积,每个项都依赖于输入的规模,例如将列表中每一项正整数转换为字符串。很多实用算法的复杂度都是对数线性的。
2.5 多项式复杂度
多项式复杂度的增长速度是输入规模的 k kk 次幂,其中最常见的是平方复杂度,例如求列表 list_a 和 list_b 的交集:
def intersect(list_a, list_b): # 第一部分 temp = [] for i in list_a: for j in list_b: if i == j: temp.append(i) break # 第二部分 result = [] for i in temp: if i not in result: result.append(i) return resultintersect 函数第一部分的复杂度显然是O(len(list_a))∗O(len(list_b)),第二部分代码用于去除第一部分得到结果列表中的重复元素,虽然其中仅包含一个循环语句,但是测试条件 if i not in result 需要检查 result 中的每个元素,因此第二部分的复杂度为O(len(temp))∗O(len(result)),tmp 和 result 的长度取决于 list_a 和 list_b 中长度较小的那个,根据渐进复杂度规则可以将其忽略。最终,intersect 函数的复杂度就是O(n2)。
2.6 指数复杂度
指数复杂度算法的解决时间随输入规模的指数增长。在以下示例中,由于 1 左移 num 位得到 end,因此 end 实际上等于2num,因此循环中计算了2num次加法,时间复杂度为O(2n)。
def calculate(num): result = 0 end = 1 << num for i in range(end): result += i return result为了直观的观察到各种复杂度的增长情况,使用统计图来对比各种复杂度算法的运行时间增长速度。
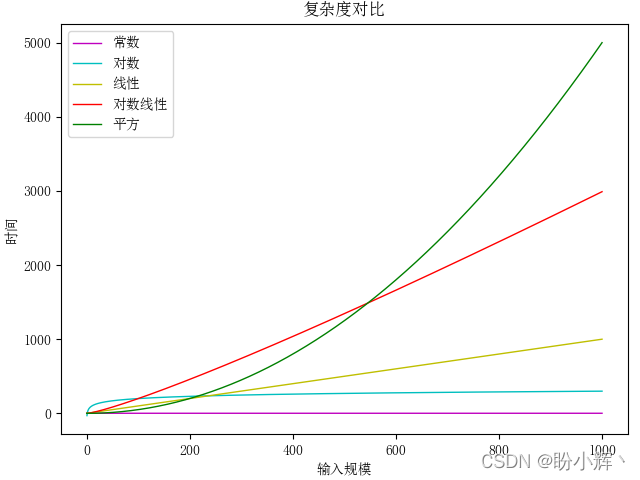
从上图可以看出,对数复杂度随问题规模的增长,运行时间的增长很小,几乎和常数复杂度算法一样优秀,通常只有当输入规模很大时才能直观的看出两者之间的差别,而线性复杂度和对数复杂度的区别在输入规模很小时就非常明显了。
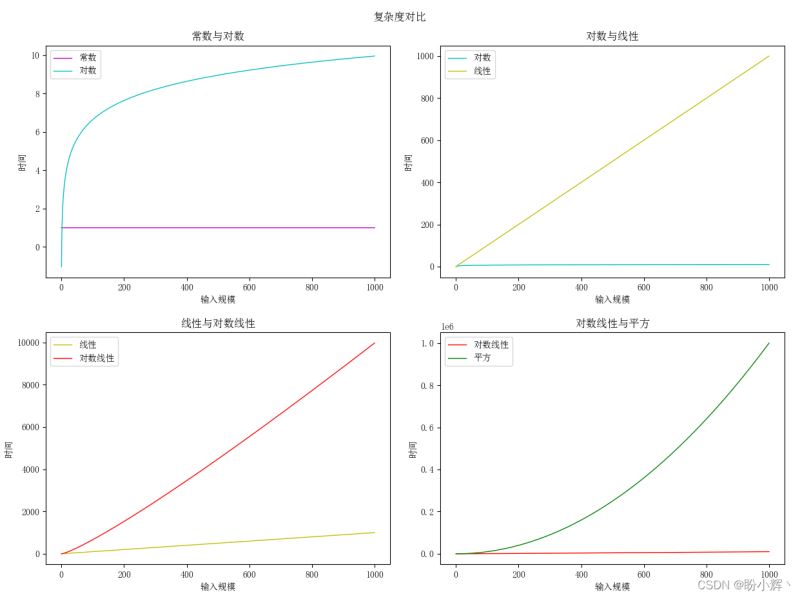
虽然O(logn) 的增长速度很慢,但是在线性乘法因子的加持下,其增长速率高于线性复杂度,但与平方复杂度的增长速度相比,就不值一提了,因此在实际情况下,具有O(nlogn) 复杂度的算法执行速度还是很快的。而指数复杂度除了对那些规模特别小的输入,其运行时间都是不现实的,即使立方复杂度和其相比都相形见绌。
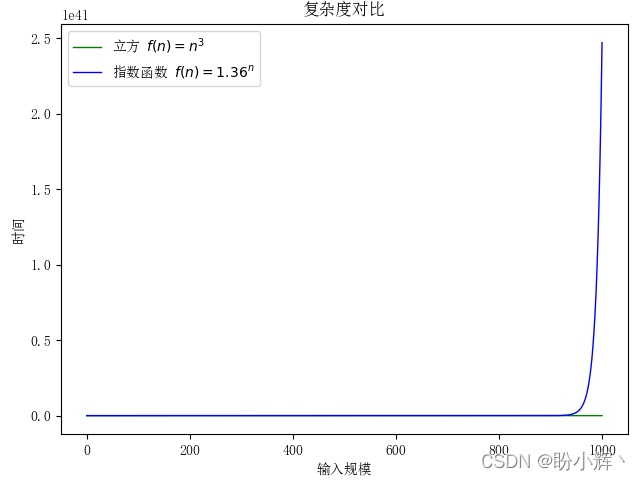
在以上内容中讨论的都是代码的时间复杂度。这是由于,与时间复杂度相比,要想感觉到空间复杂度 (space complexity) 的影响比较困难。对于用户来说,程序运行完成需要 1 分钟还是 10 分钟是明显能够感觉到的,但程序使用的内存是 1 兆字节还是 10 兆字节则无法直观觉察。这也就是时间复杂度通常比空间复杂度更受关注的原因。通常只有当运行程序所需的存储空间超过了计算机内存时,空间复杂度才会受到关注。
类似于算法的时间复杂度,空间复杂度作为算法所需存储空间的量度,可以表示为:
S(n)=O(f(n))
一个程序的执行除了需要存储空间来寄存本身所用指令、常数变量和输入数据外,也需要一些辅助空间用于存储数据处理的中间数据。若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析除输入和程序之外的额外空间,否则应同时考虑输入本身所需空间。若额外空间相对于输入数据量来说是常数,则称此算法为原地工作。
由于在之后的学习中,我们需要经常使用列表和字典作为构建其他数据结构的基石,因此了解这些数据结构操作的时间复杂度是必要的。
Python 列表常见操作的时间复杂度如下表所示:
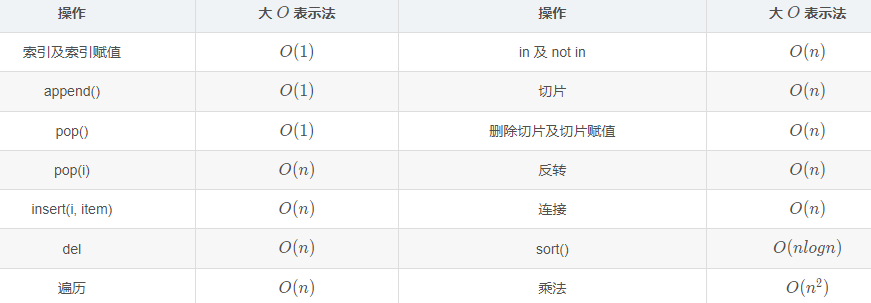
在列表中虽然 append() 操作和 insert() 操作都是向列表中添加一个元素,不同的是 append() 向列表末尾追加一个元素,而 insert() 在指定位置处插入元素,其后的元素都要向后移一位,因此它们的时间复杂度也不相同。
为了获取执行时间,这里使用 timeit 模块,该模块能够在一致的环境中执行函数。要使用 timeit 模块,首先需要创建一个 Timer 对象,其接受两个参数:第 1 个参数是要为之计时的 Python 语句;第 2 个参数是建立测试的 Python 语句。timeit 模块会统计多次执行语句要用多久,默认情况下,timeit 会执行 100 万次语句,并在完成后返回一个浮点数格式的秒数,可以给 timeit 传入参数 number,以指定语句的执行次数。
import timeitimport randomappend_timeit = timeit.Timer('x.append(1)', 'from __main__ import x')insert_timeit = timeit.Timer('x.insert(0, 1)', 'from __main__ import x')for i in range(10000, 2000000, 20000): x = list(range(i)) # 测试函数运行 1000 次所花的时间 append_time = append_timeit.timeit(number=1000) x = list(range(i)) # 测试函数运行 1000 次所花的时间 insert_time = insert_timeit.timeit(number=1000) print("{}, {}, {}".format(i, append_time, insert_time))在上例中,计时的语句是对 append 和 insert 操作的调用。建立测试的语句是初始化代码或构建环境导入语句,是执行代码的准备工作,示例中的 from __main__ import x 将 x 从 __main__ 命名空间导入到 timeit 设置计时的命名空间,用于在测试中使用列表对象 x,这么是为了在一个干净的环境中运行计时测试,以免某些变量以某种意外的方式干扰函数的性能。
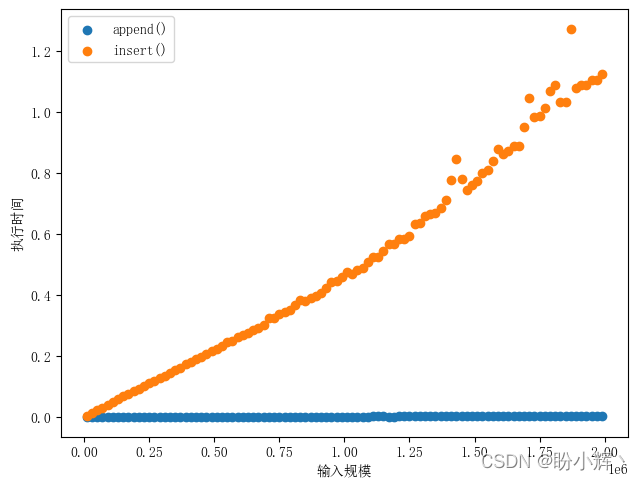
从上图中可以看出,列表越长,insert 操作的耗时也随之变长,而 append 操作的耗时很稳定,符合O(n)和O(1) 的特征。
Python 字典常见操作的时间复杂度如下表所示:

对比两表可以发现,即使是同一操作使用不同数据结构其复杂度也是不同的,例如包含操作 in。为了验证它们之间的不同,编写以下程序进行实验:
import timeitimport randomfor i in range(10000, 1000000, 20000): t = timeit.Timer('random.randrange({}) in x'.format(i), 'from __main__ import random, x') x = list(range(i)) list_time = t.timeit(number=1000) x = {j: j for j in range(i)} dict_time = t.timeit(number=1000) print("{}, {}, {}".format(i, list_time, dict_time))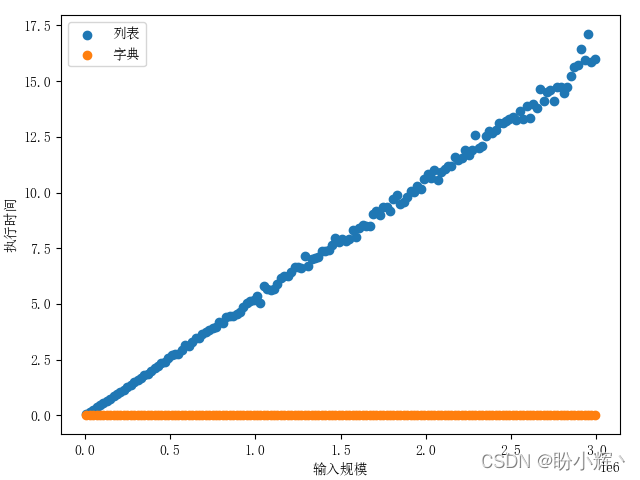
从上图可以看出,随着规模的增长,对于字典而言,包含操作的耗时始终是基本恒定的,而对于列表而言,其包含操作的耗时呈线性增长。
以上是“Python中算法的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注编程网Python频道!
--结束END--
本文标题: Python中算法的示例分析
本文链接: https://lsjlt.com/news/302949.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0