Python 官方文档:入门教程 => 点击学习
在python的爬虫学习中,我们的url经常出现中文的问题,我们想要访问的url就需要对url进行拼接,变成浏览器可以识别的url在Python中已经有了这样的模块了,这就是urlencodeurlencode需要对中文和关键字组成一对字典
在python的爬虫学习中,我们的url经常出现中文的问题,
我们想要访问的url就需要对url进行拼接,变成浏览器可以识别的url
在Python中已经有了这样的模块了,这就是urlencode
urlencode需要对中文和关键字组成一对字典,然后解析成我们的url
在python2中是
urllib.urlencode(keyWord)
在Python中是
urllib.parse.urlencode(keyword)
查看一下代码:
python2
import urllib
import urllib2
#例如我们需要在百度上输入个关键字哈士奇进行查询,但是哈士奇是中文的,我们需要对哈士奇进行编码
keyword = {"wd":"哈士奇"}
head_url = "Http://www.baidu.com/s"
headers = {
"User-Agent":"Mozilla/5.0 (windows NT 10.0; WOW64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
wd = urllib.urlencode(keyword)
url = head_url +"?"+ wd
req = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(req)
html = response.read()
print(url)
print(html.count('哈士奇'))结果如下: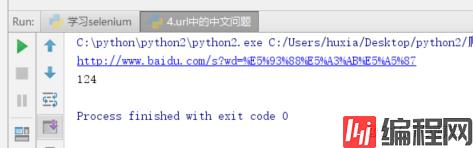
在python3中:
# -*- coding: utf-8 -*-
# File : url中出现的中文问题.py
# Author: HuXianyong
# Date : 2018-09-13 17:39
from urllib import request
import urllib
#例如我们需要在百度上输入个关键字哈士奇进行查询,但是哈士奇是中文的,我们需要对哈士奇进行编码
keyword = {"wd":"哈士奇"}
head_url = "http://www.baidu.com/s"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
wd = urllib.parse.urlencode(keyword)
url = head_url +"?"+ wd
req = request.Request(url,headers=headers)
response = request.urlopen(req)
html = response.read()
print(html.decode().count("哈士奇"))
print(url)结果如下: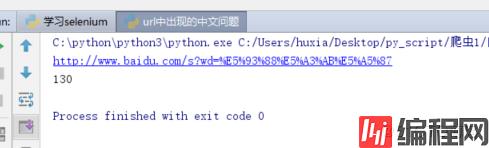
如果需要吧转换的字符变成中文
可以用unquota
如下:
python2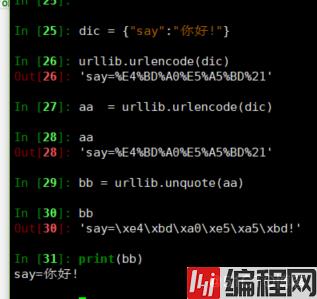
In [25]: dic = {"say":"你好!"}
In [26]: urllib.urlencode(dic)
Out[26]: 'say=%E4%BD%A0%E5%A5%BD%21'
In [27]: aa = urllib.urlencode(dic)
In [28]: aa
Out[28]: 'say=%E4%BD%A0%E5%A5%BD%21'
In [29]: bb = urllib.unquote(aa)
In [30]: bb
Out[30]: 'say=\xe4\xbd\xa0\xe5\xa5\xbd!'
In [31]: print(bb)
say=你好!
python3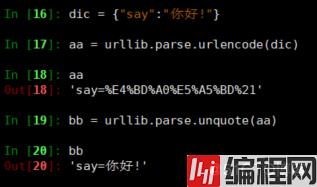
In [16]: dic = {"say":"你好!"}
In [17]: aa = urllib.parse.urlencode(dic)
In [18]: aa
Out[18]: 'say=%E4%BD%A0%E5%A5%BD%21'
In [19]: bb = urllib.parse.unquote(aa)
In [20]: bb
Out[20]: 'say=你好!'
但是如果我们的是post请求数据需要加在data里面这样就还需要对data做处理,不然会报字符串的错:
TypeError: POST data should be bytes or an iterable of bytes. It cannot be of type str.这样的解决方法是需要加上个编码data = urllib.parse.urlencode(fORMData).encode(encoding="UTF8")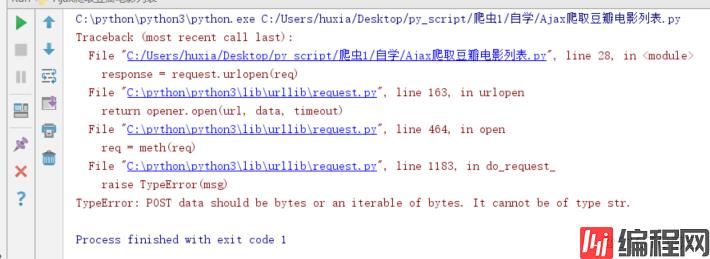
代码如下:
# -*- coding: utf-8 -*-
# File : ajax爬取豆瓣电影列表.py
# Author: HuXianyong
# Date : 2018-09-14 14:35
import urllib
from urllib import request
url = "https://movie.douban.com/j/new_search_subjects?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
formData = {
"sort": "S",
"range": "0,10",
"tags": "电影,魔幻",
"start": "0",
"genres": "剧情"
}
data = urllib.parse.urlencode(formData).encode(encoding="UTF8")
req = request.Request(url=url,data=data,headers=headers)
response = request.urlopen(req)
move_info = response.read().decode()
print(response.read().decode())--结束END--
本文标题: python爬虫之url中的中文问题
本文链接: https://lsjlt.com/news/189707.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0