Python 官方文档:入门教程 => 点击学习
轻松玩转AI路径: 从Python开始 [链接] 数据科学 [链接] 机器学习 [链接] 深度学习——神经网络 [链接] 从Python开始 Python3入门 [链接] Python3进阶 [链接] Pytho
轻松玩转AI路径:
从Python开始
Python3进阶 目录:
实际案例:

解决方案:

1)列表解析:过滤掉列表中的负数
# 方法1:循环遍历
data = [-1,2,3,-4,5]
res = []
for x in data:
if x>= 0:
res.append(x)
print(res)
# 方法2:列表解析
# 利用内置函数filter生成器对象(一次性)
fORM random import randint
# 创建一个元素有十个的 -10~10 之间的随机列表
l = [randint(-10, 10) for _ in range(10)]
res = [x for x in l if x >= 0] # (更优)
# 或:
res = list(filter(lambda x: x >= 0, l))2)字典解析:筛选出字典中值高于90的项
form random import randint
d = {'student%d' % i: randint(50, 100) for i in range(1, 21)}
g = {for k, v in d.items() if v >= 90}
# 或:
g = dist(filter(lambda item: item[1] >= 90, d.items()))3)集合解析:筛选出集合中能被3整除的元素
form random import randint
s = {randint(0, 20) for _ in range(20)}
g = {x for x in s if x % 3 == 0}实际案例:

解决方案:
方案1:定义一系列数值常量或枚举类型
方案2:使用标准库中 collections.namedtuple 命名元组 替代内置 tuple
方案1:
# 方法1:数值常量
NAMEM, AGE, SEX, EMaiL = range(4)
def xxx_func(student):
if student[AGE] < 18:
pass
if student[SEX] == 'male':
pass
...
student = ('Jim', 16, 'male', 'jim8721@gmail.com')
xxx_func(student)
# 方法2:枚举类型
s = ('Jim', 16, 'male', 'jim8721@gmail.com')
from enum import IntEnum
class StudentEnum(IntEnum):
NAME = 0
AGE = 1
SEX = 2
EMAIL = 3
s[StudentEnum.NAME] # 返回:'Jim'方案2:
from collections import namedtuple
# 创建命名元组类
Student = namedtuple('Student', ['name', 'age', 'sex', 'email'])
# 实例化。元组。
s2 = Student('Jim', 16, 'male', 'jim8721@gmail.com')
s2.name # 返回:'Jim'实际案例:

解决方案:
将字典中的各项转化为元组,使用内置函数 sorted 排序。
方案1:将字典中的项转化为(值, 键)元组。(列表解析或 zip)
from random import randint
d = {k: randint(60, 100) for k in 'abcdefgh'}
l = [(v, k) for k, v in d.items()]
sorted(l, reverse=True)
# 或:
list(zip(d.values(), d.keys()))方案2:传递 sorted 函数的 key 参数
from random import randint
d = {k: randint(60, 100) for k in 'abcdefgh'}
p = sorted(d.items(), key=lambda item: item[1], reverse=True)
# list(enumerate(p, 1))
for i,(k, v) in enumerate(p, 1):
d[k] = (i, v)
# 或:
{k:(i, v) for i, (k, v) in enumerate(p, 1)}实际案例:

解决方案:
例1方案1:将序列转换为字典 {元素 : 频度},根据字典中的值排序。
# 方法1:
from random import randint
data = [randint(0, 20) for _ in range(30)]
d = dict.fromkeys(data, 0)
for x in data:
d[x] += 1
sorted([(v,k) for k,v in d.items()], reverse=True)[:3]
# 或:
sorted(((v,k) for k,v in d.items()), reverse=True)[:3]
# 方法2: 使用堆 (更优)
import heapq
heapq.nlargest(3, ((v,k) for k,v in d.items())) # 取最大
# heapq.nsmallest() # 取最小例1方案2:使用标准库 collections 中的 Counter 对象。
from collections import Counter
data = [randint(0, 20) for _ in range(30)]
d = dict.fromkeys(data, 0)
for x in data:
d[x] += 1
c = Counter(data)
c.most_common(3)例2方案:
txt = open('example.txt').read() # 读取一个含单词文件
import re
Word_list = re.split('\W+', txt)
c2 = Counter(word_list)
c2.most_common(10)实际案例:

解决方案:
方案1:列表式
from random import randin, sample
# 假设8个球员名字分别为'abcdefgh'
d1 = {k: randint(1, 4) for k in sample('abcdefgh', randint(3, 6))}
d2 = {k: randint(1, 4) for k in sample('abcdefgh', randint(3, 6))}
d3 = {k: randint(1, 4) for k in sample('abcdefgh', randint(3, 6))}
dl = [d1, d2, d3]
[k for k in dl[0] if all(map(lambda d: k in d, dl[1:]))]方案2:利用集合(set)的交集操作(更优)
step1:使用字典的 keys() 方法,得到一个字典 keys 的集合。
step2:使用 map 函数,得到每个字典 keys 的集合。
step3:使用 reduce 函数,取所有字典的 keys 集合的交集。
from random import randin, sample
from functools import reduce
# 假设8个选手名字分别为'abcdefgh'
d1 = {k: randint(1, 4) for k in sample('abcdefgh', randint(3, 6))}
d2 = {k: randint(1, 4) for k in sample('abcdefgh', randint(3, 6))}
d3 = {k: randint(1, 4) for k in sample('abcdefgh', randint(3, 6))}
dl = [d1, d2, d3]
reduce(lambda a, b:a & b, map(dict.keys, dl))实际案例:

解决方案:
使用标准库 collections 中的 OrderedDict
以 OrderedDict 替代内置字典 Dict,依次将选手成绩存入 OrderedDict。
from collections import OrderedDict
form random import shuffle
# 假设8个选手名字分别为'abcdefgh'
players = list('abcdefgh')
players(players) # 随机化
od = OrderedDict()
# 创建名次
for i, p in enumerate(players, 1):
od[p] = i
#def query_by_name(d, name):
# return d[name]
#query_by_name(od, 'c')
from itertools import islice
def query_by_order(d, a, b=None):
a -= 1
if b is None:
b = a + 1
return list(islice(od, a, b))
query_by_order(od, 4)
query_by_order(od, 3, 6)实际案例:

解决方案:
使用容量为 n 的队列存储历史记录
使用标准库 collections 中的 deque,它是一个双端循环队列。
使用 pickle 模块将历史记录存储到硬盘,以便下次启动使用。


from random import randint
from collections import deque # 双端循环队列
import pickle
def guess(n, k):
if n == k:
print('猜对了,这个数字是%d' % k)
return True
if n < k:
print('猜大了,比 %d小' % k)
elif n > k:
print('猜小了,比 %d大' % k)
return False
def main():
n = randint(1, 100)
i = 1
hq = deque([], 5) # 创建历史记录队列
while True:
line = input('[%d] 请输入一个数字: ' % i)
if line.isdigit():
k = int(line)
hq.append(k)
i += 1
if guess(n, k):
break
elif line == 'quit':
break
elif line == 'hq':
print(list(hq)) # 查看历史记录
# 将历史记录存储到硬盘
pickle.dump(hq, open('save.pkl', 'wb'))
if __name__ == '__main__':
main()
# 打开历史记录
pickle.load(open('save.pkl', 'rb'))实际案例:

解决方案:
方法1:连续使用 str.split() 方法,每次只能处理一种分隔符号。
s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
[ss.split('|') for ss in s.split(';')] # 二维列表
# 或:
list(map(lambda ss: ss.split('|'), s.split(';'))) # 二维列表
# 变成一维列表
t = []
list(map(t.extend, [ss.split('|') for ss in s.split(';')]))
t
# 或:
sum([ss.split('|') for ss in s.split(';')] ,[])s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
def my_split(s, seps):
res = [s]
for sep in seps:
t = []
list(map(lambda ss: t.extend(ss.split(sep)), res))
res = t
return res
my_split(s, ',;|\t')或:
s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
from functools import reduce
reduce(lambda 1, sep: sum(map(lambda ss: ss.split(sep), 1), []), ',;|\t', [s])
# 或:
my_split = lambda s, seps: reduce(lambda 1, sep: sum(map(lambda ss: ss.split(sep), 1), []), seps, [s])
my_split(s, ',;|\t')方法2:使用正则表达式的 re.split() 方法。(推荐)
s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
import re
re.split('[,;|\t]+', s)实际案例:

文件权限:
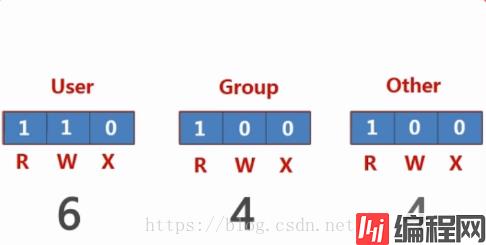
解决方案:
使用 str.startswith() 和 str.endswith() 方法。
(注意:多个匹配时参数使用元组)
# 假设当前目录下有文件:a.c、b.py、c.jave、d.sh、e.cpp、h.asm
import os
d = os.listdir('.') # 读取当前目录下的所有文件名
s = os.stat('b.py') # 查看权限
oct(s.st_mode) # 返回:'0o100644'。八进制的文件权限
oct(s.st_mode | 0o100) # 返回:'0o100744'
os.chmod('b.py', s.st_mode | 0o100) # 修改权限# 假设当前目录下有文件:a.c、b.py、c.jave、d.sh、e.cpp、h.asm
import os
import stat
for fn in os.listdir():
if fn.endswith(('.py', '.sh'))
fs = os.stat(fn)
os.chmod(fn, fs.st_mode | stat.S_IXUSR)实际案例:

解决方案:
使用正则表达式 re.sub() 方法做字符串替换,利用正则表达式的捕获组,捕获每个部分内容,在替换字符串中调整各个捕获组的顺序。
f = open('./xxx.log')
log = f.read()
improt re
re.sub(r'(\d{4})-(\d{2})-(\d{2})', r'\2/\3/\1', log)
# 或:
re.sub(r'(?P<d>\d{4})-(?P<m>\d{2})-(?P<y>\d{2})', r'\g<m>/\g<d>/\g<y>', log)实际案例:

解决方案:
方法:1:迭代列表,连续使用 ‘+’ 操作拼接每一个字符串。
l = ["<0112>", "<32>", "<1024x768>", "<60>", "<1>", "<100.0>", "<500.0>"]
s = ''
for x in l:
s += x
s
# 或:
from functools import reduce
reduce(str.__add__, l)方法2:使用 str.join() 方法,更加快速的拼接列表中所有字符串。(更优)
l = ["<0112>", "<32>", "<1024x768>", "<60>", "<1>", "<100.0>", "<500.0>"]
''.join(l)实际案例:

解决方案:
方法1:使用字符串的 str.ljust(), str.rjust(), str.center() 进行 左,右,居中对齐。
s = 'abc'
print(s.ljust(10)) # 'abc '
print(s.rjust(10, '*'))
print(s.center(10, '*'))方法2:使用 format() 方法,传递类似 ‘<20’, ‘>20’, ‘^20’ 参数完成 左,右,居中对齐。
s = 123
print(s.format(s, '<10')) # '123 '
print(s.format(-s, '>+10')) # '- 123'
print(s.format(s, '*^10')) # '***123****'
print(s.format(s, '0=+10')) # '+000000123'
print(s.format(-s, '0=+10')) # '-000000123'
# 等同于:
s.__format__('>10')d = {'lodDist':100.0, 'SmallCull':0.04, 'DistCull':500.0, 'trilinear':40, 'farclip':477}
w = max(map(len, d.keys()))
for k,v in d.items():
print(k.ljust(w), ':', v)实际案例:

解决方法:
方法1:字符串 strip(), lstrip(), rstrip() 方法去掉字符串两端,左端,右端的字符。
s = ' nick2008@gmail.com '
s.strip() # 去掉两端空白
s.lstrip() # 去掉左边空白
s.rstrip() # 去掉右边空白
s = '=-=nick2008@gmail.com=+'
s.strip('=+-')方法2:删除单个固定位置的字符,可以使用 切片 + 拼接 的方式。
s2 = 'abc:1234'
s2[:3] + s2[4:]方法3:字符串的 replace() 方法或正则表达式 re.sub() 删除任意子串。
s3 = ' abc xyz '
s3.replace(' ', '')
s3 = ' \t abc \t xyz \n '
import re
re.sub('[ \t\n]+', '', s3)
# 或
re.sub('\s+', '', s3)方法4:字符串的 translate() 方法,可以同时删除多种不同字符。
s = 'abc1234xyz'
s.translate({ord('a'): 'X', ord('b'): 'Y'}) # 替换
s.translate(s.maketrans('abcxyz', 'XYZABC')) # 替换
s.translate({ord('a'): None}) # 删除import unicodedata
s4.translate(dict.fromkeys([ord(c) for c in s4 if unicodedata.combining(c)]))实际案例:

解决方案:
from collections import Iterable, Iterator
l = [1, 2, 3, 4, 5]
for x in l:
print(x)
# isinstance(l, Iterable) # 查看是否是迭代器(可迭代对象)
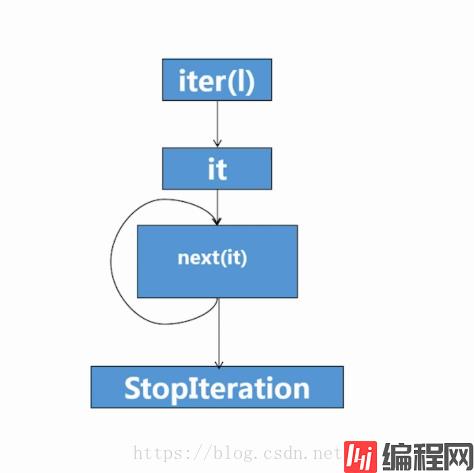
# isinstance(l, Iterator) # 查看是否是生成器for 循环机制是内含:iter(), next()
step1:实现一个迭代器对象 Weatherlterator,_next_ 方法每次返回一个城市的气温。
step2:实现一个可迭代对象 Weatherlterable,_iter_ 方法返回一个 Weatherlterator 对象。
url = 'Http://wthrcdn.etouch.cn/weather_mini?city=' + '北京'
import requests
r = requests.get(url)
r.JSON()from collections import Iterable, Iterator
import requests
class WeatherIterator(Iterator):
def __init__(self, caties):
self.caties = caties
self.index = 0
def __next__(self):
if self.index == len(self.caties):
raise StopIteration
city = self.caties[self.index]
self.index += 1
return self.get_weather(city)
def get_weather(self, city):
url = 'http://wthrcdn.etouch.cn/weather_mini?city=' + city
r = requests.get(url)
data = r.json()['data']['forecast'][0]
return city, data['high'], data['low']
class WeatherIterable(Iterable):
def __init__(self, cities):
self.cities = cities
def __iter__(self):
return WeatherIterator(self.cities)
def show(w):
for x in w:
print(x)
WeatherIterable(['北京', '上海', '广州'])
show(w)实际案例:

解决方法:
将该类的 _iter_ 方法实现成生成器函数,每次 yield 返回一个素数。
from collections import Iterable
class PrimeNumbers(Iterable):
def __init__(self, a, b):
self.a = a
self.b = b
def __iter__(self):
for k in range(self.a, self.b + 1):
if is_prime(k):
yield k
def is_prime(self, k):
#if k < 2:
# return False
#[2, k-1]
#for x in range(2, k):
# if k % x == 0:
# return False
#return True
# 以上等同于:
return False if k < 2 else all(map(lambda x: k % x, range(2, k)))
pn = PrimeNumbers(1, 30)
for n in pn:
print(n)实际案例:

解决方案:
实现反向迭代协议的 _reversed_ 方法,它返回一个反向迭代器。
from decimal import Decimal # 解决数字精准性问题
class FloatRange:
def __init__(self, a, b, step):
self.a = Decimal(str(a))
self.b = Decimal(str(b))
self.step = Decimal(str(step))
def __iter__(self):
t = self.a
while t <= self.b:
yield float(t)
t += self.step
def __reversed__(self):
t = self.b
while t >= self.a:
yield float(t)
t -= self.step
fr = FloatRange(3.0, 4.0, 0.2)
# 正向迭代
for x in fr:
print(x)
# 反向迭代
for x in reversed(fr):
print(x)实际案例:

解决方案:
使用 itertools.islice,它能返回一个迭代对象切片的生成器。
f = open('/var/log/dpkg.log.1')
from itertools import islice
#for line in islice(f, 100-1, 300):
# print(line)
# 或:
print(list(islice(f, 100, 300, 1)))
# 等同于:
def my_islice(iterable, start, end, step=1):
tmp = 0
for i, x in enumerate(iterable):
if i >= end:
break
if i >= start:
if tmp == 0:
tmp = step
yield x
tmp -= 1
print(list(my_islice(f,100, 300, 1)))实际案例:

解决方案:
1.并行:使用内置函数 zip,它能将多个可迭代对象合并,每次迭代返回一个元组。
from random import randint
chinese = [randint(60, 100) for _ in range(20)]
math = [randint(60, 100) for _ in range(20)]
english = [randint(60, 100) for _ in range(20)]
#list(map(lambda *args: args, chinese, math, english))
# 或:
list(zip(chinese, math, english))2.串行:使用标准库中的 itertools.chain,它能将多个可迭代对象连接。
from itertools import chain # 迭代链
c1 = [randin(60, 100) for _ in range(20)]
c2 = [randin(60, 100) for _ in range(20)]
c3 = [randin(60, 100) for _ in range(20)]
c4 = [randin(60, 100) for _ in range(20)]
len([x for x in chain(c1,c2,c3,c4) if x > 90])s = 'abc;123|xyz;678|fweuow\tjzka'
from functools import reduce
list(reduce(lambda it_s, sep: chain(*map(lambda ss: ss.split(sep), it_s)), ';|\t', [s]))实际案例:

解决方案:

# python2
s = u'我爱Python' # <type 'unicode'>
f = open('a.txt', 'w')
f.write(s.encode('utf8'))
f.flush()
f = open('a.txt')
txt = f.read() # <type 'str'>
txt.decode('utf8')# python3
s = '我爱python' # <type 'str'>
f = open('b.txt', 'wt', encoding='utf8')
f.write(s)
f.flush()
f = open('b.txt', encoding='utf8')
f.read()实际案例:

解决方案:
open 函数想以二进制模式打开文件,指定 mode 参数为 ‘b’。
二进制数据可以用 readinto,读入到提前分配好的 buffer 中。
解析二进制数据可以使用标准库中的 struct 模块的 unpack 方法。

f = open('demo.wav', 'rb')
info = f.read(44) # <class 'bytes'>
import struct
struct.unpack('h', info[22:24]) # h 2字节
struct.unpack('i', info[24:28]) # i 4字节
info.find(b'data')import struct
f = open('demo.wav', 'rb')
def find_subchunk(f, name):
f.seek(12) # 指定指针位置
while True:
chunk_name = f.read(4)
chunk_size, = struct.unpack('i', f.read(4))
if chunk_name == name:
return f.tell(), chunk_size
f.seek(chunk_size, 1)
offset, size = find_subchunk(f, b'data')
import numpy as np
buf = np.zeros(size//2, dtype=np.short)
f.readinto(buf)
buf //= 8
f2 = open('out.wav', 'wb')
f.seek(0)
info = f.read(offset)
f2.write(info)
buf.tofile(f2)
f2.close()实际案例:

解决方案:
全缓冲:open 函数的 buffering 设置为大于 1 的 整数n(n为缓冲区大小)
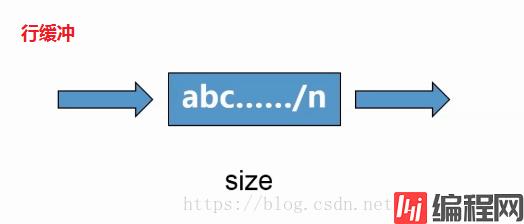
行缓冲:open 函数的 buffering 设置为 1
无缓冲:open 函数的 buffering 设置为 0
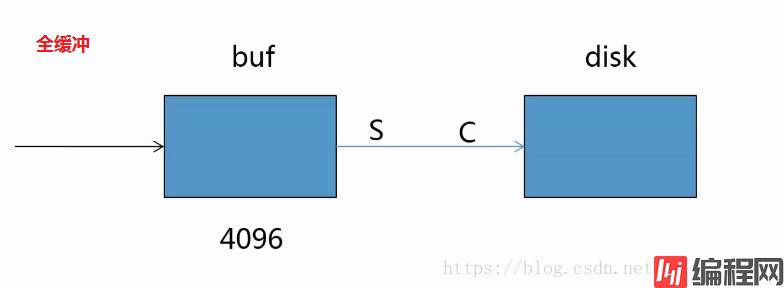
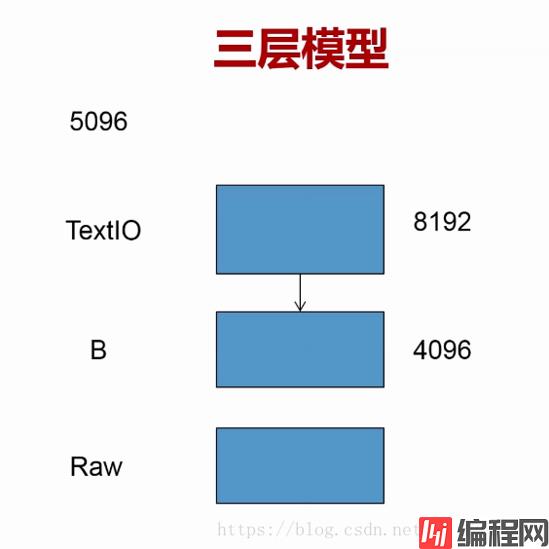
# 全缓冲
f = open('a.bin', 'rb')
f.write(b'+' * (4096))
f.write('-')
f2 = open('a.txt', 'w')
f2.write('+' * 5096)
f2.write('*' * (8192-5096))
f2.write('-')
# 设置缓冲大小
f = open('a.bin', 'wb', buffering=8192)
f.write(b'+' * 4097)
f.write(b'-' * 4097)
# 设置无缓冲
f = open('a.bin', 'wb', buffering=0)
# 或无缓冲写入
f.raw.write(b'abc')
# 设置行缓冲
f = open('a.bin', 'wb', buffering=1)# 行缓冲
f3 = open('/dev/pts/2', 'w') # pts 文件默认行缓冲
f3.write('abc')
f3.write('efg')
f3.write('\n')实际案例:

解决方法:
使用标准库中 mmap.mmap() 函数,将文件映射到进程的内存地址空间。
import mmap
m = mmap.mmap(f.flieno(), 0)import mmap
f = open('/dev/fb0', 'r+b')
size = 8294400
m = mmap.mmap(f.flieno(), size)
m[:size//2] = b'\xff\xff\xff\x00' * (size // 4 // 2)
m.close()
f.close()实际案例:

解决方法:
系统调用:标准库 os 模块中的系统调用 stat 获取文件状态。
import os
os.stat('a.txt') # 文件状态
s = os.stat('a.txt') # 文件权限等信息
fd = os.open('b.py', os.O_RDONLY) # 第二个参数是指定权限。得到文件描述符。
os.read(fd, 10) # 读取 10个字节
实际案例:

解决方法:
使用标准库中的 TemporaryFile 以及 NamedTemporaryFile。
from tempfile import TemporaryFile, NamedTemporaryFile
tf = TemporaryFile() # 创建带名字临时文件对象
# 参数 delete=False 则关闭时不删除
#tf = NamedTemporaryFile() # 创建没有名字临时文件对象
tf.write(b'*' * 1024 * 1024 * 1024) # 创建 1G 数据
tf.close() # 关闭时删除注:资料整理来源于:https://www.imooc.com/
--结束END--
本文标题: 轻松玩转AI(从Python开始之Pyt
本文链接: https://lsjlt.com/news/185719.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0