1.1数据库存储引擎 1.1.1存储引擎介绍 数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,
![Mysql数据库教程(二)[云图智联]](/upload/202205/01/fvbnrbkyq4t.jpg)
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎
因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(Table Type,即存储和操作此表的类型)。
InnoDB 是 mysql 上第一个提供外键约束的数据存储引擎,除了提供事务处理外,InnoDB 还支持行锁,提供和 oracle 一样的一致性的不加锁读取,能增加并发读的用户数量并提高性能,不会增加锁的数量。InnoDB 的设计目标是处理大容量数据时最大化性能,它的 CPU 利用率是其他所有基于磁盘的关系数据库引擎中最有效率的。
InnoDB是默认的数据库存储引擎,他的主要特点有:
(1)可以通过自动增长列,方法是auto_increment。
(2)支持事务。默认的事务隔离级别为可重复度,通过mvcC(并发版本控制)来实现的。
(3)使用的锁粒度为行级锁,可以支持更高的并发;
(4)支持外键约束;外键约束其实降低了表的查询速度,但是增加了表之间的耦合度。
(5)配合一些热备工具可以支持在线热备份;
(6)在InnoDB中存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度;
(7)对于InnoDB类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织。数据和索引放在一块,都位于B+数的叶子节点上;
当然InnoDB的存储表和索引也有下面两种形式:
(1)使用共享表空间存储:所有的表和索引存放在同一个表空间中。
(2)使用多表空间存储:表结构放在frm文件,数据和索引放在IBD文件中。分区表的话,每个分区对应单独的IBD文件,分区表的定义可以查看我的其他文章。使用分区表的好处在于提升查询效率。
对于InnoDB来说,最大的特点在于支持事务。但是这是以损失效率来换取的。
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在WEB、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物和外键。
每个MyISAM在磁盘上存储成3个文件,其中文件名和表名都相同,但是扩展名分别为:
frm和MYI可以存放在不同的目录下。MYI文件用来存储索引,但仅保存记录所在页的指针,索引的结构是B+树结构。下面这张图就是MYI文件保存的机制:
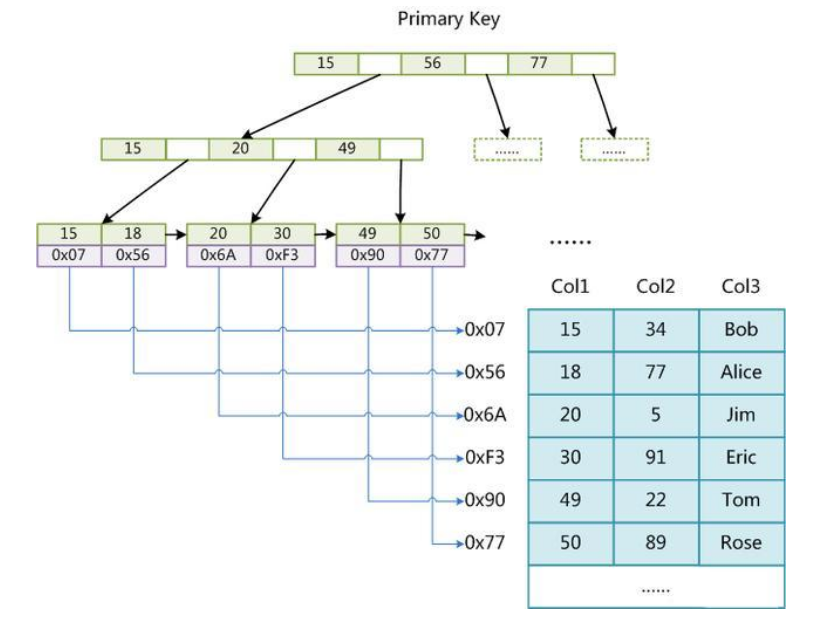
从这张图可以发现,这个存储引擎通过MYI的B+树结构来查找记录页,再根据记录页查找记录。并且支持全文索引、B树索引和数据压缩。
这种方式的优点在于存储速度非常快,容易发生缓存,而且表发生损坏后也容易修复。缺点是占空间。这也是默认的存储格式。
优点是节省空间,但是一旦出错恢复起来比较麻烦。
上面说到支持数据压缩,说明肯定也支持这个格式。在数据文件发生错误时候,可以使用check table工具来检查,而且还可以使用repair table工具来恢复。
有一个重要的特点那就是不支持事务,但是这也意味着他的存储速度更快,如果你的读写操作允许有错误数据的话,只是追求速度,可以选择这个存储引擎。
语法:
SHOW VARIABLES LIKE ‘storage_engine%’;
语法:
default-storage-engine= InnoDB //可以修改为其他存储引擎在创建表的同时进行设置存储引擎:
CREATE TABLE 表名(
#省略代码
)ENGINE=存储引擎;
一般除了表结构定义文件以外,还有用于存储数据的ibdata1文件。

1、单条数据插入:
INSERT INTO 表名 [(字段名列表)] VALUES (值列表);
例如:
INSERT INTO `student`(`loginPwd`,`studentName`,`gradeId`,`phone`,`bornDate`) VALUES("111","小明",1,"15000001111","1999-9-9");注意:
1) 字段名是可选的,如省略则依次插入所有字段
2) 多个列表和多个值之间使用逗号分隔
3) 值列表和字段名列表一一对应
4) 如插入的是表中部分数据,字段名列表必填
2、多条数据插入
INSERT INTO 新表(字段名列表) VALUES(值列表1),(值列表2),……,(值列表n);
例如:
INSERT INTO `subject`(`subjectName`,`classhour`,`gradeID`) VALUES("Logic Java",110,1),("html",120,1),("Java OOP",130,2);注意:为避免表结构发生变化引发的错误,建议插入数据时写明具体字段名!
CREATE TABLE 新表(SELECT 字段1,字段2…… FROM 原表);
例如:
CREATE TABLE `phoneList`( SELECT `studentName`,`phone` FROM `student`);注意:如新表已存在,将会报错!
UPDATE 表名 SET 字段1=值1,字段2=值2,…,字段n=值n [WHERE 条件];
例如:
UPDATE student SET sex = ‘男’;//未指定条件修改所有数据
UPDATE student SET address = ‘上海市’ WHERE address = ‘北京市’; //将北京市修改为上海市DELETE FROM 表名 [WHERE条件];
或
TRUNCATE TABLE 表名;
例如:
DELETE FROM student WHERE studentName = ‘小明’; //删除学生为小明的学生信息
TRUNCATE TABLE student; //清空当前表数据注意: TRUNCATE语句删除后将重置自增列,表结构及其字段、约束、索引保持不变,执行速度比DELETE语句快
查询就是产生一个虚拟表看到的是表形式显示的结果,但结果并不真正存储每次执行查询只是从数据表中提取数据,并按照表的形式显示出来。
平时在生活中大家使用的最多的无非就是像百度,谷歌这些搜索引擎了,那么这些搜索的结果也可以说是通过关键字进行查询,那么在查询语句中一般也会涉及到这些内容,精确匹配和模糊匹配。
SELECT <列名|表达式|函数|常量>
FROM <表名>
[WHERE <查询条件表达式>]
[ORDER BY <排序的列名>[ASC或DESC]];
例如:
SELECT `studentNo`,`studentName`,`phone`,`address`,`bornDate`
FROM `student`
WHERE `gradeId` = 1
ORDER BY `studentNo`; //查询学生的学号、姓名、电话、地址、生日 并且年级为1的学生信息 并根据学号进行排序下面,我们就来详细讲解一下查询语句:
1)查询全部行和列
SELECT * FROM 表名;
例如:
SELECT * FROM `student`; 2)查询部分列
SELECT 字段,字段1,字段2
FROM 表名
WHERE 字段名=值;
例如:
SELECT `studentNo`,`studentName`,`address`
FROM `student`
WHERE `address`=‘河南新乡’;注意:在查询时 where 语句为查询的条件,可以配合MySQL中的逻辑运算符进行使用。
3)模糊查询
SELECT * FROM 表名 where 字段名 like 值% ; // 开头为‘值’开头,结尾可以为任意结果
SELECT * FROM 表名 where 字段名 like %值 ; // 开头可以为任意结果,结尾为‘值’结尾
SELECT * FROM 表名 where 字段名 like %值% ; // 包含‘值’的内容
SELECT * FROM 表名 where 字段名 like _值% ; // 一个任意字符和‘值’开头,任意值为结尾
SELECT * FROM 表名 where 字段名 like %值_ ; // 任意开头,‘值’后面结尾为一个任意值4)查询空行
SELECT 字段名 FROM 表名 WHERE 字段名 IS NULL;
例如:
SELECT `studentName` FROM `student` WHERE `email` IS NULL;// 查询email为空的学生名字| 函数名 | 作用 |
|---|---|
| AVG() | 返回某字段的平均值 |
| COUNT() | 返回某字段的行数 |
| MAX() | 返回某字段的最大值 |
| MIN() | 返回某字段的最小值 |
| SUM() | 返回某字段的和 |
| 函 数 名 | 作 用 | 举 例 |
|---|---|---|
| CONCAT(str1, str1...strn) | 字符串连接 | SELECT CONCAT("My","S","QL"); 返回:MySQL |
| INSERT(str, pos,len, newstr) | 字符串替换 | SELECT INSERT( "这是SQL Server数据库", 3,10,"MySQL"); 返回:这是MySQL数据库 |
| LOWER(str) | 将字符串转为小写 | SELECT LOWER("MySQL"); 返回:mysql |
| UPPER(str) | 将字符串转为大写 | SELECT UPPER("MySQL"); 返回:MYSQL |
| SUBSTRING (str,num,len) | 字符串截取 | SELECT SUBSTRING( "JavaMySQLOracle",5,5); 返回:MySQL |
| 函数名 | 作用 | 举例**(结果与当前时间有关)** |
|---|---|---|
| CURDATE() | 获取当前日期 | SELECT CURDATE(); 返回:2016-08-08 |
| CURTIME() | 获取当前时间 | SELECT CURTIME(); 返回:19:19:26 |
| NOW() | 获取当前日期和时间 | SELECT NOW(); 返回:2016-08-08 19:19:26 |
| WEEK(date) | 返回日期date为一年中的第几周 | SELECT WEEK(NOW()); 返回:26 |
| YEAR(date) | 返回日期date的年份 | SELECT YEAR(NOW()); 返回:2016 |
| HOUR(time) | 返回时间time的小时值 | SELECT HOUR(NOW()); 返回:9 |
| MINUTE(time) | 返回时间time的分钟值 | SELECT MINUTE(NOW()); 返回:43 |
| DATEDIFF(date1,date2) | 返回日期参数date1和date2之间相隔的天数 | SELECT DATEDIFF(NOW(), "2008-8-8"); 返回:2881 |
| ADDDATE(date,n) | 计算日期参数date加上n天后的日期 | SELECT ADDDATE(NOW(),5); 返回:2016-09-02 09:37:07 |
| 函数名 | 作 用 | 举 例 |
|---|---|---|
| CEIL(x) | 返回大于或等于数值x的最小整数 | SELECT CEIL(2.3) 返回:3 |
| FLOOR(x) | 返回小于或等于数值x的最大整数 | SELECT FLOOR(2.3) 返回:2 |
| RAND() | 返回0~1间的随机数 | SELECT RAND() 返回:0.5525468583708134 |
SELECT <字段名列表>
FROM <表名或视图>
[WHERE <查询条件>]
[GROUP BY <分组的字段名>]
[ORDER BY <排序的列名>[ASC(默认) 或 DESC]]
[LIMIT [位置偏移量,]行数];
例如:
SELECT `studentName` AS 学生姓名
FROM `student`
WHERE `sex` = `女`
ORDER BY studentNo DESC; // 查询出性别为女的学生姓名并根据学号进行降序排序 MySQL查询语句中使用LIMIT子句限制结果集
SELECT <字段名列表>
FROM <表名或视图>
[WHERE <查询条件>]
[GROUP BY <分组的字段名>]
[ORDER BY <排序的列名>[ASC 或 DESC]]
[LIMIT [位置偏移量,]行数];
例如:
SELECT *
FROM `student`
WHERE `gradeId` = 1
ORDER BY studentNo
LIMIT 4; // 查询年级为1的学生信息并且根据学号进行升序分组的前4条
LIMIT 0,4; // 表示从第1条开始,显示4条
LIMIT 4,4; // 表示从第5条开始,显示4条(就是第5~8条)
LIMIT 5,4; // 表示从第6条开始,显示4条(就是7~10条)注意: 使用LIMIT子句时,注意第1条记录的位置是0!
子查询是一个嵌套在 SELECT、INSERT、UPDATE 或 DELETE 语句或其他子查询中的查询,可以将子查询理解为将多个操作合并在一起得出结果。
子查询在WHERE语句中的一般用法:
SELECT … FROM 表1 WHERE 字段1 比较运算符(子查询)
例如:
SELECT *
FROM `student`
WHERE `bornDate` >
(SELECT `bornDate` FROM `student` WHERE `studentName`="张三"); //查询生日大于张三生日的学生信息
(常用的比较运算符 > < >= <= =)一般常用IN替换等于(=)的子查询 ,并且IN后面的子查询可以返回多条记录
SELECT studentName
FROM student
WHERE studentNo IN(1001,1002); //查询学生学号为1001,1002的学生姓名除了上述情况外,也可以将查询结果当作子查询的条件。
SELECT studentName
FROM student
WHERE studentNo IN(
select studentNo from student where bornDate >
(SELECT `bornDate` FROM `student` WHERE `studentName`="张三")
); //查询大于张三生日的学生学号的学生姓名NOT IN 的用法和 IN子查询相反,取IN的反义
SELECT studentName
FROM student
WHERE studentNo NOT IN(
select studentNo from student where bornDate >
(SELECT `bornDate` FROM `student` WHERE `studentName`="张三")
); //查询除了大于张三生日的学生学号的学生姓名
--结束END--
本文标题: Mysql数据库教程(二)[云图智联]
本文链接: https://lsjlt.com/news/7103.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0