Oracle Redo and Undo 《 Oracle Core Essential Internals for DBAs and Developers 》 在我看来,Orac
Oracle Redo and Undo
《 Oracle Core Essential Internals for DBAs and Developers 》

在我看来,Oracle 最重要的特性,是 Oracle 6 版本出现的 change vector , 描述数据块改变的机制,也是Redo 和 undo 的核心。
but in my opinion the single most important feature of Oracle is one that first appeared in version 6: the change vector, a mechanism for describing changes to data blocks, the heart of redo and undo.
一 Basic Data Change 基础数据改变
Oracle 有趣的一个特点是会记录两次数据,第一次是将最近的数据写入到 data files( 为了提高效率,最新的数据记录在内存中,批量刷新到 data files) ,第二次是将数据写入到 redo log files( 用来描述如何重建 data files)
One of the strangest features of an Oracle database is that it records your data twice. One copy of the data exists in a set of data files which hold something that is nearly the latest, up-to-date version of your data (although the newest version of some of the data will be in memory, waiting to be copied to disc); the other copy of the data exists as a set of instructions—the redo log files—telling you how to re-create the content of the data files from scratch.
1.1 The Approach 方法
在数据库更改时,你发出了更改数据的命令,Oracle并不是马上在data file(如果数据在内存中,去data buffer cache查找数据)里找到对应的数据,然后去修改对应的数据。而是通过如下四个关键步骤来完成数据的修改:
1.创建如何修改数据的描述。
2.创建如何回退数据的描述。
3.创建如何产生回退数据描述的描述。
4.修改数据。
Under the Oracle approach to data change, when you issue an instruction to change an item of data, Oracle doesn’t just go to a data file (or the in-memory copy if the item happens to be buffered), find the item, and change it. Instead, Oracle works through four critical steps to make the change happen.
Stripped to the bare minimum of detail, these are
1. Create a description of how to change the data item.
2. Create a description of how to re-create the original data item if needed.
3. Create a description of how to create the description of how to re-create the original data item.
4. Change the data item.
其中第三步看上去不好理解,下面换一种方式描述这四个步骤:
1.创建生成data block对应的Redo change vector 。
2.创建Undo record,在Undo表空间生成Undo Block,用于数据回退。
3.创建生成undo record对应的Redo change vector 。
4.修改数据 。
The tongue-twisting nature of the third step gives you some idea of how convoluted the mechanism is, but all will become clear. With the substitution of a few technical labels in these steps, here’s another way of describing the actions of changing a data block:
1. Create a redo change vector describing the change to the data block.
2. Create an undo record for insertion into an undo block in the undo tablespace.
3. Create a redo change vector describing the change to the undo block.
4. Change the data block.
具体技术细节、执行顺序和Oracle版本、事务的性质、执行变更命令前各数据块的状态等有关。
The exact sequence of steps and the various technicalities around the edges vary depending on the version of Oracle, the nature of the transaction, how much work has been done so far in the transaction, what the states of the various database blocks were before you executed the instruction, whether or not you’re looking at the first change of a transaction, and so on.
1.2 An Example 例:
从一个最简单的数据更改示例开始,更新OLTP事务中间的一行,该事务已经更新了一组分散的行。事实上,在历史(以及最普遍的)案例中,步骤的顺序与我在前一节中列出的顺序不同。
I’m going to start with the simplest example of a data change, which you might expect to see as you updated a single row in the middle of an OLTP transaction that had already updated a scattered set of rows. In fact, the order of the steps in the historic (and most general) case is not the order I’ve listed in the preceding section.
这些步骤实际上是按照3、1、2、4的顺序进行的,在修改undo block和data block之前,将这两个重做更改向量组合成一个重做更改记录并复制到redo log (buffer)中。这意味着更准确的版本是:
The steps actually go in the order 3, 1, 2, 4, and the two redo change vectors are combined into a single redo change record and copied into the redo log (buffer) before the undo block and data block are modified (in that order). This means a slightly more accurate version of my list of actions would be:
1.创建生成undo record对应的Redo change vector (描述undo block的改变)。
2.创建生成data block对应的Redo change vector (描述redo block的改变)。
3.创建生成undo record和data block的Redo change vector 合并成一个Redo record写入log buffer(便于重做等)。
4.创建Undo record写入Undo block(便于事务回退等)。
5.更改数据。
1. Create a redo change vector describing how to insert an undo record into an undo block.
2. Create a redo change vector for the data block change.
3. Combine the redo change vectors into a redo record and write it to the log buffer.
4. Insert the undo record into the undo block.
5. Change the data block.
下面是一个小示例,取自一个运行Oracle 9.2.0.8的系统(在上一个版本中,很容易创建该机制的最一般示例)。
Here’s a little sample, taken from a system running Oracle 9.2.0.8 (the last version in which it’s easy to create the most generic example of the mechanism).
我们将执行一个update语句,通过在两个表块之间来回跳转来更新五行,并在更新前后将各种信息位转储到流程跟踪文件中。
We’re going to execute an update statement that updates five rows by jumping back and forth between two table blocks, dumping various bits of information into our process trace file before and after the update.
我需要使我的更新有点复杂,因为我希望示例尽可能简单,同时避免一些特殊情况。
I need to make my update a little bit complicated because I want the example to be as simple as possible while avoiding a few “special case” details.
我编写的代码将更新表的第一个块中的第三、第四和第五行 数据 , 并且在每更新一条后 更新第二个块中的一行 ( core_demo_02.sql ),它会更改每个记录的第三列(varchar2类型的字段),将其由xxxxxx(小写6个字符)更改为YYYYYYYYYY(大写10个字符)。
The code I’ve written will update the third, fourth, and fifth rows in the first block of a table but will update a row in the second block of the table between each of these three updates (see core_demo_02.sql in the code library on www.apress.com), and it’ll change the third column of each row—a varchar2() column—from xxxxxx (lowercase, six characters) to YYYYYYYYYY (uppercase, ten characters).
https://GitHub.com/Apress/oracle-core-esntl-internals-for-dbas-devs
--- 使用 core_demo_02.sql 脚本如下:
---core_demo_02.sql
---1 准备
start setenv
set timing off
execute dbms_random.seed ( 0 )
drop table t1 ;
begin
execute immediate 'purge recyclebin';
exception
when others then
null;
end;
begin
dbms_stats.set_system_stats ( 'MBRC' , 8 );
dbms_stats.set_system_stats ( 'MREADTIM' , 26 );
dbms_stats.set_system_stats ( 'SREADTIM' , 12 );
dbms_stats.set_system_stats ( 'CPUSPEED' , 800 );
exception
when others then
null ;
end ;
begin
execute immediate 'begin dbms_stats.delete_system_stats; end;' ;
exception
when others then
null ;
end ;
begin
execute immediate 'alter session set "_optimizer_cost_model"=io' ;
exception
when others then
null ;
end ;
/
---2 创建表和索引
create table t1
as
select
2 * rownum - 1 id ,
rownum n1 ,
cast ( 'xxxxxx' as varchar2 ( 10 )) v1 ,
rpad ( '0' , 100 , '0' ) padding
from
all_objects
where
rownum <= 60
uNIOn all
select
2 * rownum id ,
rownum n1 ,
cast ( 'xxxxxx' as varchar2 ( 10 )) v1 ,
rpad ( '0' , 100 , '0' ) padding
from
all_objects
where
rownum <= 60
;
create index t1_i1 on t1 ( id );
---3 收集统计信息
begin
dbms_stats.gather_table_stats ( ownname => user ,
tabname => 'T1' ,
method_opt => 'for all columns size 1' );
end ;
---4 查看表占用的块情况,和每一个块有多少条数据 每一个块都有60条记录
select
dbms_rowid.rowid_block_number ( rowid ) block_number ,
count (*) rows_per_block
from
t1
group by
dbms_rowid.rowid_block_number ( rowid )
order by
block_number
;
BLOCK_NUMBER ROWS_PER_BLOCK
------------ --------------
114153 60
114154 60
---5 转储数据块
alter system switch logfile ;
execute dbms_lock.sleep ( 2 )
spool core_demo_02.lst
---dump_seg存储过程需要执行c_dump_seg.sql生成
---Https://github.com/Apress/oracle-core-esntl-internals-for-dbas-devs/blob/master/ch_03/c_dump_seg.sql
execute dump_seg ( 't1' )
---6 更新数据
update
t1
set
v1 = 'YYYYYYYYYY'
where
id between 5 and 9
;
---7 转储更新块之后的数据块和undo块
alter system checkpoint ;
execute dump_seg ( 't1' )
---dump_undo_block存储过程
---https://github.com/Apress/oracle-core-esntl-internals-for-dbas-devs/blob/master/ch_02/c_dump_undo_block.sql
execute dump_undo_block
---8 转储redo块
rollback ;
commit ;
---dump_log存储过程
---https://github.com/Apress/oracle-core-esntl-internals-for-dbas-devs/blob/master/ch_02/c_dump_log.sql
execute dump_log
spool off
[oracle@cjcos trace]$ pwd
/u01/app/oracle/diag/rdbms/cjcdb/cjcdb/trace
[oracle@cjcos trace]$ vim cjcdb_ora_21778.trc

下面是更新前后块中第五行的转储信息:
Here’s a symbolic dump of the fifth row in the block before and after the update:
更新前 第三列(col 2)长度是6,数据是78(x的16进制ASCII码是78)
tab 0, row 4, @0x1d3f
tl: 117 fb: --H-FL-- lb: 0x0 cc: 4
col 0: [ 2] c1 0a
col 1: [ 2] c1 06
col 2: [ 6] 78 78 78 78 78 78
col 3: [100]
30 30 30 30 30 30 30 30 … 30 30 30 30 30 (for 100 characters)
更新后 第三列(col 2)长度是10,数据是59(Y的16进制ASCII码是59)
tab 0, row 4, @0x2a7
tl: 121 fb: --H-FL-- lb: 0x2 cc: 4
col 0: [ 2] c1 0a
col 1: [ 2] c1 06
col 2: [10] 59 59 59 59 59 59 59 59 59 59
col 3: [100]
30 30 30 30 30 30 30 30 … 30 30 30 30 30 (for 100 characters)
我们可以看到第三列(col2)长度变成了10,是10个59(Y的十六进制ASCII码是59),同时行地址由@0x1d3f变成了@0x2a7,说明这一行的空间容不下新增的数据,换了新地址。
As you can see, the third column (col 2:) of the table has changed from a string of 78s (x) to a longer string of 59s (Y). Since the update increased the length of the row, Oracle had to copy it into the block’s free space to make the change, which is why its starting byte position has moved from @0x1d3f to @0x2a7. It is still row 4 (the fifth row) in the block, though; if we were to check the block’s row directory, we would see that the fifth entry has been updated to point to this new row location.
同时,我们能看到lb(lock byte)由0x0变成了0x2,表明这条记录被该块事务槽列表中的第二个事务槽所标识的事务锁定。事务槽可以在块首部看到。我们将在第三章更深入地讨论它。
I dumped the block before committing the change, which is why you can see that the lock byte (lb:) has changed from 0x0 to 0x2—the row is locked by a transaction identified by the second slot in the block’s interested transaction list (ITL). We will be discussing ITLs in more depth in Chapter 3.
我们来看看不同的变化向量。首先,从current redo log file转储中,我们可以检查变化矢量,描述我们对表做了什么:
So let’s look at the various change vectors. First, from a symbolic dump of the current redo log file, we can examine the change vector describing what we did to the table:
TYP:0 CLS: 1 AFN:11 DBA:0x02c0018a SCN:0x0000.03ee485a SEQ: 2 OP:11.5
KTB Redo
op: 0x02 ver: 0x01
op: C uba: 0x0080009a.09d4.0f
KDO Op code: URP row dependencies Disabled
xtype: XA bdba: 0x02c0018a hdba: 0x02c00189
itli: 2 ispac: 0 maxfr: 4863
tabn: 0 slot: 4(0x4) flag: 0x2c lock: 2 ckix: 16
ncol: 4 nnew: 1 size: 4
col 2: [10] 59 59 59 59 59 59 59 59 59 59
可以看到,第五行URP(更新行块),第六行告诉我们正在更新块的块地址(bdba)和对象的段头块(hdba)
I’ll pick out just the most significant bits of this change vector. You can see that the Op code: in line 5 is URP (update row piece). Line 6 tells us the block address of the block we are updating (bdba:) and the segment header block for that object (hdba:).
在第7行,我们看到执行这个更新的事务使用的是ITL条目2 (itli:),它是对tabn: 0 slot: 4的更新(第一个表中的第5行;请记住,集群中的块可以容纳来自许多表的数据,因此每个块必须包含一个列表,用于标识块中有行的表)。
In line 7 we see that the transaction doing this update is using ITL entry 2 (itli:), which confirms
what we saw in the block dump: it’s an update to tabn: 0 slot: 4 (fifth row in the first table; remember that blocks in a cluster can hold data from many tables, so each block has to include a list identifying the tables that have rows in the block).
最后,在最后两行中,我们看到该行有四列(ncol:),其中我们更改了一列(nnew:),将行长度(size:)增加了4个字节,并且我们将第2列更改为YYYYYYYYYY。
Finally, in the last two lines, we see that the row has four columns (ncol:), of which we are changing one (nnew:), increasing the row length (size:) by 4 bytes, and that we are changing column 2 to YYYYYYYYYY.
接下来我们需要看到的是如何 撤销我们的变更 。这将以undo record撤销记录的形式出现,从相关的undo block块中转储。在第3章中将介绍寻找正确的undo block的方法。下面的文本显示了来自块转储的相关记录:
The next thing we need to see is a description of how to put back the old data. This appears in the form of an undo record, dumped from the relevant undo block. The methods for finding the correct undo block will be covered in Chapter 3. The following text shows the relevant record from the symbolic block dump:
*-----------------------------
* Rec #0xf slt: 0x1a objn: 45810(0x0000b2f2) objd: 45810 tblspc: 12(0x0000000c)
* Layer: 11 (Row) opc: 1 rci 0x0e
Undo type: Regular undo Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000
*-----------------------------
KDO undo record:
KTB Redo
op: 0x02 ver: 0x01
op: C uba: 0x0080009a.09d4.0d
KDO Op code: URP row dependencies Disabled
xtype: XA bdba: 0x02c0018a hdba: 0x02c00189
itli: 2 ispac: 0 maxfr: 4863
tabn: 0 slot: 4(0x4) flag: 0x2c lock: 0 ckix: 16
ncol: 4 nnew: 1 size: -4
col 2: [ 6] 78 78 78 78 78 78
再次,我将忽略一些细节,只是指出这个undo记录的重要组成部分(对我们来说) , 我们看到的行大小减少4个字节,第2列是xxxxxx。
Again, I’m going to ignore a number of details and simply point out that the significant part of this undo record (for our purposes) appears in the last five lines and comes close to repeating the content of the redo change vector, except that we see the row size decreasing by 4 bytes as column 2 becomes xxxxxx.
但是这是一个undo记录,写在undo块中,存储在其中一个数据文件的undo表空间中,而且,正如我前面指出的,Oracle保存所有内容的两个副本,一个在数据文件中,一个在重做日志文件中。因为我们已经将一些内容放入了数据文件中(即使它在undo表空间中),所以我们需要创建一个关于我们所做事情的描述,并将该描述写入重做日志文件中。我们需要另一个重做改变矢量,它是这样的:
But this is an undo record, written into an undo block and stored in the undo tablespace in one of the data files, and, as I pointed out earlier, Oracle keeps two copies of everything, one in the data files and one in the redo log files. Since we’ve put something into a data file (even though it’s in the undo tablespace), we need to create a description of what we’ve done and write that description into the redo log file. We need another redo change vector, which looks like this:
TYP:0 CLS:36 AFN:2 DBA:0x0080009a SCN:0x0000.03ee485a SEQ: 4 OP:5.1
ktudb redo: siz: 92 spc: 6786 flg: 0x0022 seq: 0x09d4 rec: 0x0f
xid: 0x000a.01a.0000255b
ktubu redo: slt: 26 rci: 14 opc: 11.1 objn: 45810 objd: 45810 tsn: 12
Undo type: Regular undo Undo type: Last buffer split: No
Tablespace Undo: No
0x00000000
KDO undo record:
KTB Redo
op: 0x02 ver: 0x01
op: C uba: 0x0080009a.09d4.0d
KDO Op code: URP row dependencies Disabled
xtype: XA bdba: 0x02c0018a hdba: 0x02c00189
itli: 2 ispac: 0 maxfr: 4863
tabn: 0 slot: 4(0x4) flag: 0x2c lock: 0 ckix: 16
ncol: 4 nnew: 1 size: -4
col 2: [ 6] 78 78 78 78 78 78
重做更改向量的下半部分看起来非常像撤消记录,这并不奇怪,因为它毕竟是我们希望放入撤消块的内容的描述。
The bottom half of the redo change vector looks remarkably like the undo record, which shouldn’t be a surprise as it is, after all, a description of what we want to put into the undo block.
重做改变向量的上半部分告诉我们下半部分去了哪里,并包含了一些关于它要 写入 块的块头信息。
The top half of the redo change vector tells us where the bottom half goes, and includes some information about the block header information of the block it’s going into.
最重要的细节,就我们的目的而言,是 第一行的 DBA(数据块地址),该标识块0 x0080009a:如果你知道Oracle块在十六进制数字,你就会认识到这是 2号数据文件 154 号 块(新创建的数据库中撤消表空间的文件号)。
The most significant detail, for our purposes, is the DBA: (data block address) in line 1, which identifies block 0x0080009a: if you know your Oracle block numbers in hex, you’ll recognize that this is block 154 of data file 2 (the file number of the undo tablespace in a newly created database).
1.3 Debriefing 总结
那么,到目前为止,我们取得了什么进展?当我们更改一个数据块时,Oracle会在undo块中插入一个undo记录,告诉我们如何逆转这个更改。但是,对于数据库中发生的每一个块更改,Oracle都会创建一个redo change向量来描述如何进行更改,并且在进行更改之前创建这些向量。历史上,它在创建“正向”更改向量之前创建了撤销更改向量,因此,我前面描述的事件序列(参见图2-1)如下:
So where have we got to so far? When we change a data block, Oracle inserts an undo record into an undo block to tell us how to reverse that change. But for every change that happens to a block in the database, Oracle creates a redo change vector describing how to make that change, and it creates the vectors before it makes the changes. Historically, it created the undo change vector before it created the “forward” change vector, hence, the following sequence of events (see Figure 2-1) that I described earlier occurs:
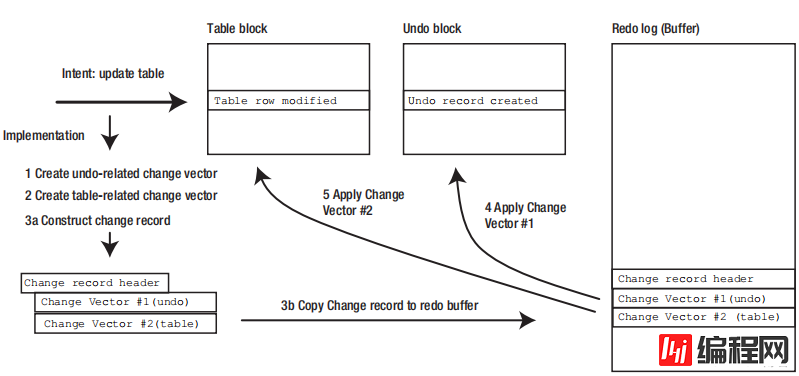
图2 - 1。在事务中间进行 小 更新的事件序列
1.为撤销记录创建更改向量。
2.为数据块创建更改向量。
3.合并更改向量并将重做记录写入重做日志(缓冲区)。
4.将undo记录插入undo块中。
5.对数据块进行更改。
Figure 2-1. Sequence of events for a small update in the middle of a transaction
1. Create the change vector for the undo record.
2. Create the change vector for the data block.
3. Combine the change vectors and write the redo record into the redo log (buffer).
4. Insert the undo record into the undo block.
5. Make the change to the data block.
当你看到这里的前两个步骤,当然,没有理由相信我把它们按正确的顺序排列。我所描述或抛弃的任何东西都不能说明这些行为一定是按这个顺序发生的。但有一个小细节我现在可以告诉你,我省略了转储的改变向量,部分是因为 从Oracle 10g以后情况会有不同 ,另一部分是因为如果你一开始就以错误的顺序思考,对活动的描述会更容易理解。
When you look at the first two steps here, of course, there’s no reason to believe that I’ve got them in the right order. Nothing I’ve described or dumped shows that the actions must be happening in that order. But there is one little detail I can now show you that I omitted from the dumps of the change vectors, partly because things are different from 10g onwards and partly because the description of the activity is easier to comprehend if you first think about it in the wrong order.
到目前为止,我已经向你们展示了我们的两个变化矢量作为单独的实体;如果我向你展示了这些变化矢量进入重做日志的完整图片,你就会看到它们是如何组合成一个重做记录的:
So far I’ve shown you our two change vectors only as individual entities; if I had shown you the complete picture of the way these change vectors went into the redo log, you would have seen how they were combined into a single redo record:
REDO RECORD - Thread:1 RBA: 0x00036f.00000005.008c LEN: 0x00f8 VLD: 0x01
SCN: 0x0000.03ee485a SUBSCN: 1 03/13/2011 17:43:01
CHANGE #1 TYP:0 CLS:36 AFN:2 DBA:0x0080009a SCN:0x0000.03ee485a SEQ: 4 OP:5.1
…
CHANGE #2 TYP:0 CLS: 1 AFN:11 DBA:0x02c0018a SCN:0x0000.03ee485a SEQ: 2 OP:11.5
…
在重做日志中,更改向量是成对出现的,撤销记录的更改向量出现在相应的正向更改的更改向量之前。
It is a common (though far from universal) pattern in the redo log that change vectors come in matching pairs, with the change vector for an undo record appearing before the change vector for the corresponding forward change.
在查看前面的重做记录的基本内容时,值得注意的是第一行中的LEN:—这是重做记录的长度:0x00f8 = 248字节。
While we’re looking at the bare bones of the preceding redo record, it’s worth noting the LEN: figure in the first line—this is the length of the redo record: 0x00f8 = 248 bytes.
我们所做的只是在一行中将xxxxxx更改为yyyyyyyy,这将花费我们248字节的日志信息。
All we did was change xxxxxx to YYYYYYYYYY in one row and it cost us 248 bytes of logging information.
实际上,考虑到最终结果,这似乎是一个非常昂贵的操作:我们必须生成两个重做更改向量并更新两个数据库块来进行一个很小的更改,这看起来是我们需要执行的步骤的四倍。我们希望所有这些额外的工作都能得到合理的回报。
In fact, it seems to have been a very expensive operation given the net result: we had to generate two redo change vectors and update two database blocks to make a tiny little change, which looks like four times as many steps as we need to do. Let’s hope we get a decent payback for all that extra work.
1.4 Summary of Observations 总结
在继续之前,我们可以总结一下我们的观察结果如下:在数据文件中,我们对自己的数据所做的每一个更改都与Oracle创建的undo记录相匹配(这也是对数据文件的更改);与此同时,Oracle在redo日志中放入了如何进行更改和如何进行自身更改的描述。
Before we continue, we can summarize our observations as follows: in the data files, every change we make to our own data is matched by Oracle with the creation of an undo record (which is also a change to a data file); at the same time Oracle puts into the redo log a description of how to make our change and how to make its own change.
您可能会注意到,由于数据可以“就地”更改,因此我们可以创建“无限”(即。,任意大)对单行数据的更改,但是如果不增加undo表空间的数据文件,显然不能记录无限多的undo记录;如果不不断添加更多的redo日志文件,也不能在redo日志中记录无限多的更改。为了简单起见,我们将推迟无限更改的问题,暂时假装我们可以记录尽可能多的撤消和重做记录。
You might note that since data can be changed “in place,” we could make an “infinite” (i.e.,
arbitrarily large) number of changes to our single row of data, but we clearly can’t record an infinite number of undo records without growing the data files of the undo tablespace, nor can we record an infinite number of changes in the redo log without constantly adding more redo log files. For the sake of simplicity, we’ll postpone the issue of infinite changes and simply pretend for the moment that we can record as many undo and redo records as we need.
二:ACID
尽管我们在本章中不会讨论事务,但值得一提的是事务系统的ACID原则,以及Oracle如何实现undo和redo,从而使Oracle能够满足这些需求。表2-1列出了ACID。
Although we’re not going to look at transactions in this chapter, it is, at this point, worth mentioning the ACID requirements of a transactional system and how Oracle’s implementation of undo and redo gives Oracle the capability of meeting those requirements.
Table 2-1. The ACID Requirements

下面的列表详细介绍了表2-1中的各项内容:
The following list goes into more detail about each of the requirements in Table 2-1:
原子性:当我们进行变更数据时,我们创建一个undo记录描述如何回退修改的数据。这意味着当我们在交易过程中,如果另一个用户试图查看我们修改过的任何数据,可以指示他使用撤消记录以查看该数据的旧版本,从而使我们的工作不可见直到我们决定发布(提交)它的那一刻。我们可以保证对方用户要么什么都看不到,要么什么都看到。
Atomicity: As we make a change, we create an undo record that describes how to
reverse the change. This means that when we are in the middle of a transaction,
another user trying to view any data we have modified can be instructed to use the
undo records to see an older version of that data, thus making our work invisible
until the moment we decide to publish (commit) it. We can ensure that the other
user either sees nothing of what we’ve done or sees everything.
一致性:这个要求实际上是关于定义合法状态的约束的数据库。
我们可以认为undo records撤销记录的存在意味着 其他用户被阻止查看事务的增量情况,因此无法看到事务通过临时的非一致性状态到另一个一致性状态,他们看到的要么是开始事务之前的状态,要么是事务完成后的状态,不会看到事务的中间状态。
Consistency: This requirement is really about constraints defining the legal states
of the database; but we could also argue that the presence of undo records means
that other users can be blocked from seeing the incremental application of our
transaction and therefore cannot see the database moving from one legal state to
another by way of a temporarily illegal state—what they see is either the old state
or the new state and nothing in between. (The internal code, of course, can see all
the intermediate states—and take advantage of being able to see them—but the
end-user code never sees inconsistent data.)
隔离 性 :我们可以再次看到,undo records撤消记录的可用性阻止了其他用户看到我们如何更改数据,直到我们决定事务已经完成并提交 事务 。实际上,我们做得更好:undo records撤消的可用性意味着其他用户不必在他们的事务的整个持续期间看到我们的事务的影响,即使我们在他们的事务的开始和结束之间开始和结束我们的事务。 (这不是Oracle中的默认隔离级别,但它是可用的隔离级别;请参阅“隔离级别”)当然,当两个用户试图同时更改相同的数据时,我们确实会遇到令人困惑的情况;在有限时间的事务里,完美的隔离是不可能的。
Isolation: Yet again we can see that the availability of undo records stops other
users from seeing how we are changing the data until the moment we decide that
our transaction is complete and commit it. In fact, we do better than that: the
availability of undo means that other users need not see the effects of our
transactions for the entire duration of their transactions, even if we start and end
our transaction between the start and end of their transaction. (This is not the
default isolation level in Oracle, but it is an available isolation level; see the
“Isolation Levels” sidebar.) Of course, we do run into confusing situations when
two users try to change the same data at the same time; perfect isolation is not
possible in a world where transactions have to take a finite amount of time.
持久性: 此特性归功于 redo log重做日志。 如何确保已完成的事务在系统故障后仍然存在?最直接的策略是在磁盘发生变化或“完成”事务的最后一步时,继续向磁盘写入任何更改。如果没有重做日志,这可能意味着在更改数据时要写入大量随机数据块。想象一下,将10行插入到包含三个索引的order_lines表中;这可能需要31个随机分布的磁盘写来对1个表块和30个索引块进行持久的更改。但是Oracle有redo重做机制,不需要在更改时写入整个数据块,而是准备一个小的更改描述,31个小的描述可能只会在需要确保有整个事务的永久记录时(相对而言)写入到日志文件的末尾。
Durability: This is the requirement that highlights the benefit of the redo log. How
do you ensure that a completed transaction will survive a system failure? The
obvious strategy is to keep writing any changes to disc, either as they happen or as
the final step that “completes” the transaction. If you didn’t have the redo log, this
could mean writing a lot of random data blocks to disc as you change them.
Imagine inserting ten rows into an order_lines table with three indexes; this could
require 31 randomly distributed disk writes to make changes to 1 table block and
30 index blocks durable. But Oracle has the redo mechanism. Instead of writing an
entire data block as you change it, you prepare a small description of the change,
and 31 small descriptions could end up as just one (relatively) small write to the
end of the log file when you need to make sure that you’ve got a permanent record
of the entire transaction. (We’ll discuss in Chapter 6 what happens to the 31
changed data blocks, and the associated undo blocks, and how recovery might
take place.)
2.1 ISOLATION LEVELS 隔离级别
Oracle提供了三种不同的隔离级别:read committed (默认), read only, 和serializable作为差异的简要说明,请考虑以下场景:表t1有1条数据,表t2和t1有相同的表结构,我们有两个会话按照下面顺序执行:
Oracle offers three isolation levels: read committed (the default), read only, and serializable. As a brief sketch of the differences, consider the following scenario: table t1 holds one row, and table t2 is identical to t1 in structure. We have two sessions that go through the following steps in order:
1. Session 1: select from t1;
2. Session 2: insert into t1 select * from t1;
3. Session 2: commit;
4. Session 1: select from t1;
5. Session 1: insert into t2 select * from t1;
如果会话1的隔离级别是read committed,将会在第一次查询到1条数据,第二次查询到2条数据,最后插入两条数据。
如果会话1的隔离级别是 read only ,将会在第一次查询到1条数据,第二次查询到1条数据,插入数据时报错 “ORA-01456: may not perform insert/delete/update operation inside a READ ONLY transaction.” 。
如果会话1的隔离级别是 serializable ,将会在第一次查询到1条数据,第二次查询到1条数据,最后插入1条数据。
If session 1 is operating at isolation level read committed, it will select one row on the first select, select two rows on the second select, and insert two rows.
If session 1 is operating at isolation level read only, it will select one row on the first select, select one row on the second select, and fail with Oracle error “ORA-01456: may not perform insert/delete/update operation inside a READ ONLY transaction.”
If session 1 is operating at isolation level serializable, it will select one row on the first select, select one row on the second select, and insert one row.
REDO 和 UNDO 机制不仅实现ACID的基本要求,而且在性能和可恢复性方面也具有优势。
在讨论 持久性 时 已经 介绍了redo 重做 对 性能 带来的 好处 ,如果您想要一个有关UNDO撤消的性能优势的示例,请考虑隔离-如果您的用户需要同时更新数据,那么如何运行需要几分钟才能完成的报告?在缺少UNDO撤消机制的情况下,您必须在允许错误结果和锁定更改数据两种情况之间进行选择。这是您必须与其他数据库产品一起做出的选择。UNDO撤销机制允许非常程度的并发,因为根据Oracle的营销宣传,“读者不会阻塞写,写也不会阻塞读者。”
就可恢复性而言(我们将在第6章中更详细地检查可恢复性),如果我们记录对数据库所做更改的完整列表,那么原则上,我们可以从一个全新的数据库开始,然后简单地重新应用每个更改描述来复制原始数据库的最新副本。实际上,当然,我们不(通常)从一个新的数据库开始;而是对数据文件进行定期备份,这样我们只需要重播生成的总重做的一小部分,就可以更新副本数据库。
Not only are the mechanisms for undo and redo sufficient to implement the basic requirements of ACID, they also offer advantages in performance and recoverability.
The performance benefit of redo has already been covered in the comments on durability; if you want an example of the performance benefits of undo, think about isolation—how can you run a report that takes minutes to complete if you have users who need to update data at the same time? In the absence of something like the undo mechanism, you would have to choose between allowing wrong results and locking out everyone who wants to change the data. This is a choice that you have to make with some other database products. The undo mechanism allows for an extraordinary degree of concurrency because, per Oracle’s marketing sound bite, “readers don’t block writers, writers don’t block readers.”
就可恢复性而言(我们将在第6章中更详细地检查可恢复性),如果我们记录下我们对数据库所做的全部更改,那么我们可以从一个全新的数据库开始,然后简单地重新应用每个更改描述来复制原始数据库的最新副本 。当然,实际上我们(通常)不会从一个新数据库开始;相反,我们采取数据文件的常规备份副本,这样我们只需要重播重做的一小部分就可以使副本数据库保持最新。
As far as recoverability is concerned (and we will examine recoverability in more detail in Chapter 6), if we record a complete list of changes we have made to the database, then we could, in principle, start with a brand-new database and simply reapply every single change description to reproduce an upto-date copy of the original database. Practically, of course, we don’t (usually) start with a new database; instead we take regular backup copies of the data files so that we need only replay a small fraction of the total redo generated to bring the copy database up to date.
三: Redo Simplicity --- Redo的简单性
我们处理redo的方法很简单:就是不断地生成redo records的stream,并以最快的速度将它们写入到redo log。最初进入共享内存的一个区域,称为 redo log buffer 重做日志缓冲区。之后在从 redo log buffer 写入到磁盘,即online redo log files。在线重做日志文件的数量是有限的,因此我们必须以循环方式不断地重用它们。
The way we handle redo is quite simple: we just keep generating a continuous stream of redo records and pumping them as fast as we can into the redo log, initially into an area of shared memory known as the redo log buffer. Eventually, of course, Oracle has to deal with writing the buffer to disk and, for operational reasons, actually writes the “continuous” stream to a small set of predefined files—the online redo log files. The number of online redo log files is limited, so we have to reuse them constantly in a round-robin fashion.
为了让online redo log files里的信息保存更长时间,大多数系统会对online redo log files保留1个或多个副本,即归档日志。但是,就redo而言,采用写入忘记机制,一旦 redo record 写入到 redo log (buffer) ,我们(通常)不希望实例重新读取它。这种“写和忘记”的方法使重做成为一种非常简单的机制。
To protect the information stored in the online redo log files over a longer time period, most systems are configured to make a copy, or possibly many copies, of each file as it becomes full before allowing Oracle to reuse it: the copies are referred to as the archived redo log files. As far as redo is concerned, though, it’s essentially write it and forget it—once a redo record has gone into the redo log (buffer), we don’t (normally) expect the instance to reread it. At the basic level, this “write and forget” approach makes redo a very simple mechanism.
注意:
虽然我们只希望对online redo log files进行写和忘记,但是还有一些特殊情况需要读取online redo log files,例如检查内存坏块、从磁盘恢复坏块等,还有一些特性需要读取online redo log files,例如: Log Miner, Streams , asynchronous Change Data Capture 等。近年来还有一些新的特性需要读取online redo log files,如standby database,我们将在第六章讨论这些特性。
Note
Although we don’t usually expect to do anything with the online redo log files except write them and forget them, there is a special case where a session can read the online redo log files when it discovers the inmemory version of a block to be corrupt and attempts to recover from the disk copy of the block. Of course, some
features, such as Log Miner, Streams, and asynchronous Change Data Capture, have been created in recent years to take advantage of the redo log files, and some of the newer mechanisms for dealing with Standby databases have become real-time and are bound into the process that writes the online redo. We will look at such features in Chapter 6.
然后,还有一个复杂的问题,将 redo record 写入到 redo log buffer 过程会出现性能瓶颈。在10g版本之前,oracle会将每个会话下数据改变产生的 redo record (包含一对重做更改向量)写入到 redo log buffer 。但是单个会话在短时间内可能会发生很多变化,也可能有多个会话同时并发操作,但是要访问的redo log buffer只有一个。
There is, however, one complication. There is a critical bottleneck in redo generation, the moment when a redo record has to be copied into the redo log buffer. Prior to 10g, Oracle would insert a redo record (typically consisting of just one pair of redo change vectors) into the redo log buffer for each change a session made to user data. But a single session might make many changes in a very short period of time, and there could be many sessions operating concurrently—and there’s only one redo log buffer that everyone wants to access.
为了解决这个问题,创建一种机制来控制对共享内存每个部分的访问,Oracle使用redo allocation latch来保护 redo log buffer 的使用。当要给进程需要使用log buffer里的部分空间时,需要先去申请获取 redo allocation latch ,一旦获取到对于的latch,就可以把相关信息写入到buffer。这样就避免了多个进程重写log buffer相同块的风险。但是如果有大量的进程申请获取redo allocation latch ,会消耗大量资源(主要时CPU用来 latch spin),或者在第一次spin失败后,离开队列,进入 sleep time 。
It’s relatively easy to create a mechanism to control access to a piece of shared memory, and Oracle’s use of the redo allocation latch to protect the redo log buffer is fairly well known. A process that needs some space in the log buffer tries to acquire (get) the redo allocation latch, and once it has exclusive ownership of that latch, it can reserve some space in the buffer for the information it wants to write into the buffer. This avoids the threat of having multiple processes overwrite the same piece of memory in the log buffer, but if there are lots of processes constantly competing for the redo allocation latch, then the level of competition could end up “invisibly” consuming lots of resources (typically CPU spent on latch spinning) or even lots of sleep time as sessions take themselves off the run queue after failing to get the latch on the first spin.
在Oracle老版本中,当数据库空闲时,redo生成的会很少, “one change = one record = one allocation” 策略对大多数系统时够用的,当随着系统更庞大更繁忙,需要处理更大的并发请求(特别对于OLTP系统),需要更加优化的策略,因此在10g新策略里出现了一种结合私有重做private redo和内存撤消 in-memory undo 的新机制。
In older versions of Oracle, when the databases were less busy and the volume of redo generated was much lower, the “one change = one record = one allocation” strategy was good enough for most systems, but as systems became larger, the requirement for dealing with large numbers of concurrent allocations (particularly for OLTP systems) demanded a more scalable strategy. So a new mechanism combining private redo and in-memory undo appeared in 10g.
事实上,流程可以遍历整个事务,生成其所有更改向量change vectors,并将它们存储在一对私有重做日志缓冲区 private redo log buffers 中。当事务完成时,进程将所有私有存储的重做复制到公共重做日志缓冲区中,此时传统的日志缓冲区处理接管。这意味着一个进程仅在事务结束后获取一次公共重做分配锁存器 public redo allocation latch ,而不是在每个更改中获得一次。
In effect, a process can work its way through an entire transaction, generating all its change vectors and storing them in a pair of private redo log buffers. When the transaction completes, the process copies all the privately stored redo into the public redo log buffer, at which point the traditional log buffer processing takes over. This means that a process acquires the public redo allocation latch only once per transaction, rather than once per change.
注意
在Oracle9.2中优化了相关策略,使用log_parallelism参数控制多个log buffers,在CPU少于16时可以忽略这个参数。在Oracle 10g,如果CPU>=2,那么至少由两个 public log buffers(redo threads) 。
Note
As a step toward improved scalability, Oracle 9.2 introduced the option for multiple log buffers with the log_parallelism parameter, but this option was kept fairly quiet and the general suggestion was that you didn’t need to know about it unless you had at least 16 CPUs. In 10g you get at least two public log buffers (redo threads) if you have more than one CPU.
有许多细节(和限制)需要提到,但是在讨论任何复杂性之前,让我们先注意一下它是如何 通过 动态性能视图 获取信息 。我使用了core_demo_02中的脚本。删除转储命令,并将其替换为调用来获取v$latch和v$sesstat的快照(参见core_demo_02b)。代码库中的sql)。我还修改了SQL以更新50行而不是5行,以便更清楚地显示工作负载的差异 。下面的结果分别来自运行相同测试的9i和10g系统。首先是9i的结果:
There are a number of details (and restrictions) that need to be mentioned, but before we go into any of the complexities, let’s just take a note of how this changes some of the instance activity reported in the dynamic performance views. I’ve taken the script in core_demo_02.sql, removed the dump commands, and replaced them with calls to take snapshots of v$latch and v$sesstat (see core_demo_02b.sql in the code library). I’ve also modified the SQL to update 50 rows instead of 5 rows so that differences in workload stand out more clearly. The following results come from a 9i and a 10g system, respectively, running the same test. First the 9i results:
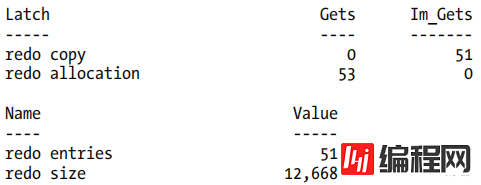
特别要注意,在9i输出中,我们已经执行了51次重做复制和重做分配锁存,并且创建了51个重做条目。与10g的结果相比较:
Note particularly in the 9i output that we have hit the redo copy and redo allocation latches 51 times each (with a couple of extra gets on the allocation latch from another process), and have created 51 redo entries. Compare this with the 10g results:
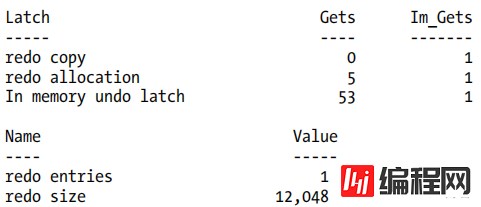
在10g版本,我们的会话之仅申请了一次 redo copy latch , redo allocation latch 上活动稍微多一些,我们可以看到生成的Redo size比9i版本测试的略小。这些结果在提交之后出现。如果我们在提交之前生成相同的快照,我们将看不到任何 redo entries (0 redo size),内存中的撤销锁存器将下降到51,重做分配锁存器将是1,而不是5。
In 10g, our session has hit the redo copy latch just once, and there has been just a little more activity on the redo allocation latch. We can also see that we have generated a single redo entry with a size that is slightly smaller than the total redo size from the 9i test. These results appear after the commit; if we took the same snapshot before the commit, we would see no redo entries (and a zero redo size), the gets on the In memory undo latch would drop to 51, and the gets on the redo allocation latch would be 1, rather than 5.
因此,在一个关键点 上 的活动和竞争威胁明显减少。在不利的方面,我们可以看到10g,测试过程中,击中了被称为内存撤销锁存器的新锁存器 In memory undo latch 53次,这使它看起来好像我们只是把争用问题从一个地方移到了另一个地方。我们把那个想法记下来,以后再 思考。
So there’s clearly a notable reduction in the activity and the threat of contention at a critical location. On the downside, we can see that 10g has, however, hit that new latch called the In memory undo latch 53 times in the course of our test, which makes it look as if we may simply have moved a contention problem from one place to another. We’ll take a note of that idea for later examination.
我们可以从数据库的不同地方了解发生了什么。我们可以检查v$latch_children来理解为什么闩锁活动的变化不是一个新的威胁。我们可以检查重做日志文件,看看一个大的重做条目是什么样子的。我们可以找到一些动态性能对象(x$kcrfstrand和x$ktifp),它们将帮助我们深入了解各种活动如何链接在一起 。
There are various places we can look in the database to understand what has happened. We can examine v$latch_children to understand why the change in latch activity isn’t a new threat. We can examine the redo log file to see what the one large redo entry looks like. And we can find a couple of dynamic performance objects (x$kcrfstrand and x$ktifp) that will help us to gain an insight into the way in which various pieces of activity link together.
增强结构时基于两组内存结构。一个(称为x$kcrfstrand, private redo )处理“向前”更改向量,另一个集合(称为x$ktifp,内存中的撤销池 in-memory undo pool )处理撤销更改向量。私有 private redo 重做结构碰巧包含关于 “public” redo log buffer(s) 的信息,因此,如果在查询时看到两个不同的信息模式,不要担心。
The enhanced infrastructure is based on two sets of memory structures. One set (called
x$kcrfstrand, the private redo) handles “forward” change vectors, and the other set (called x$ktifp, the in-memory undo pool) handles the undo change vectors. The private redo structure also happens to hold information about the traditional “public” redo log buffer(s), so don’t be worried if you see two different patterns of information when you query it.
x$ktifp( in-memory undo )中的池的数量取决于保存事务数组的大小(v$transaction),它是由参数事务设置的(但可以由参数 sessions 或参数 processes 派生)。本质上,池的数量默认为 transactions / 10,每个池由它自己的“ In memory undo latch ”管理。
The number of pools in x$ktifp (in-memory undo) is dependent on the size of the array that holds transaction details (v$transaction), which is set by parameter transactions (but may be derived from parameter sessions or parameter processes). Essentially, the number of pools defaults to transactions / 10 and each pool is covered by its own “In memory undo latch” latch.
对于x$ktifp中的每个条目,x$kcrfstrand中都有一个对应的私有重做条目 private redo entry ,并且,正如我前面提到的,还有一些额外的条目是针对传统的“公共”重做线程 “public” redo threads 的。公共重做线程的数量 public redo threads 由cpu_count参数决定,似乎是上限(1 + cpu_count / 16)。x$kcrfstrand中的每个条目都由它自己的重做分配锁存器控制,每个公共重做线程都由每个CPU一个重做复制锁存器 redo copy latch 控制(我们将在第6章中讨论这些锁存器的作用)
For each entry in x$ktifp there is a corresponding private redo entry in x$kcrfstrand, and, as I mentioned earlier, there are then a few extra entries which are for the traditional “public” redo threads. The number of public redo threads is dictated by the cpu_count parameter, and seems to be ceiling(1 + cpu_count / 16). Each entry in x$kcrfstrand is covered by its own redo allocation latch, and each public redo thread is additionally covered by one redo copy latch per CPU (we’ll be examining the role of these latches in Chapter 6).
如果我们回到原来的测试,只更新表中的5行和2个块,Oracle仍然会按照相同的顺序访问行和缓存块,但不会打包成对的重做更改向量,将它们写入重做日志缓冲区并修改块,而是按如下操作:
If we go back to our original test, updating just five rows and two blocks in the table, Oracle would still go through the action of visiting the rows and cached blocks in the same order, but instead of packaging pairs of redo change vectors, writing them into the redo log buffer, and modifying the blocks, it would operate as follows:
1. 通过获取一对匹配的私有内存结构开始事务,一个来自x$ktifp,一个来自x$kcrfstrand。
2. 将每个受影响的块标记为“具有私有重做”(但不更改块)。
3.将每个撤消更改向量undo change vector写入选定的内存撤消池in-memory undo pool。
4. 将每个重做更改向量 redo change vector 写入选定的私有重做线程 private redo thread 。
5. 通过将两个单个redo change记录中来结束事务。
6. 将重做更改记录复制到重做日志中,并将更改应用到块中。
1. Start the transaction by acquiring a matching pair of the private memory structures , one from x$ktifp and one from x$kcrfstrand.
2. Flag each affected block as “has private redo” (but don’t change the block).
3. Write each undo change vector into the selected in-memory undo pool.
4. Write each redo change vector into the selected private redo thread.
5. End the transaction by concatenating the two structures into a single redo change record.
6. Copy the redo change record into the redo log and apply the changes to the blocks.
如果我们查看内存结构(参见core_imu_01)。就在我们从原始测试提交事务之前,我们看到了以下内容:
If we look at the memory structures (see core_imu_01.sql in the code depot) just before we commit the transaction from the original test, we see the following:

这表明,会话的私有内存区域允许大约64KB的“forward” changes,而“撤消”更改也是如此。对于64位的系统,这更接近于每个128KB。对5行的更新使用了来自这两个区域的大约4KB。
如果我在提交更改后转储重做日志文件,则这是我获得的重做记录(最低限度):
This show us that the private memory areas for a session allow roughly 64KB for “forward” changes, and the same again for “undo” changes. For a 64-bit system this would be closer to 128KB each. The update to five rows has used about 4KB from each of the two areas.
If I then dump the redo log file after committing my change, this (stripped to a bare minimum) is the one redo record that I get:

您将注意到撤消记录(LEN:)的长度是0x594 = 1428,它与我在运行这个特定测试时看到的重做大小统计值相匹配。这比内存结构中报告的4352和3920字节的总和要小得多,因此显然有很多额外的字节涉及到跟踪私有的撤销和重做——可能是缓冲区中的起始开销。
You’ll notice that the length of the undo record (LEN: ) is 0x594 = 1428, which matched the value of the redo size statistic I saw when I ran this particular test. This is significantly smaller than the sum of the 4352 and 3920 bytes reported as used in the in-memory structures, so there are clearly lots of extra bytes involved in tracking the private undo and redo—perhaps as starting overhead in the buffers.
如果您通读了12个单独的更改向量的标题,特别注意OP:代码,您将看到代码11.5有5个更改向量,代码5.1有5个更改向量。这是五个前向更改向量 forward change vectors ,后面是五个撤消块更改向量 undo block change vectors 。更改向量#2(代码5.2)是事务的开始,而更改向量#7(代码5.4)是所谓的提交记录,事务的结束。我们将在第3章中更详细地讨论这些更改向量,但是这里值得一提的是,虽然大多数更改向量仅在事务提交时应用于数据块,事务开始时的更改向量是一种重要的特殊情况,在事务开始时应用于撤消段头块。
If you read through the headers of the 12 separate change vectors, taking note particularly of the OP: code, you’ll see that we have five change vectors for code 11.5 followed by five for code 5.1. These are the five forward change vectors followed by the five undo block change vectors. Change vector #2 (code 5.2) is the start of transaction, and change vector #7 (code 5.4) is the so-called commit record , the end of transaction. We’ll be looking at those change vectors more closely in Chapter 3, but it’s worth mentioning at this point that while most of the change vectors are applied to data blocks only when the transaction commits, the change vector for the start of transaction is an important special case and is applied to the undo segment header block as the transaction starts.
因此,Oracle有一种机制来减少会话从(公共)重做日志缓冲区请求空间并将信息复制到该缓冲区的次数,从而提高了我们可以实现的并发级别……在一定程度上。但你可能会想,我们必须为这种好处付出代价——当然,我们确实付出了代价
So Oracle has a mechanism for reducing the number of times a session demands space from, and copies information into, the (public) redo log buffer, and that improves the level of concurrency we can achieve . . . up to a point. But you’re probably thinking that we have to pay for this benefit somewhere— and, of course, we do.
在前面,我们看到我们所做的每一个更改都会导致对内存撤销锁存器的访问。这是否意味着我们只是转移了闩锁活动的威胁,而不是真正缓解了它? Yes and no 。现在我们只命中一个锁存器(在内存中是撤消锁存器),而不是两个(重做分配 redo allocation 和重做复制 redo copy ),所以我们至少减少了一半的闩锁活动,但是,更重要的是,内存中的撤销锁存器有多个子锁存器,每个子锁存器对应一个内存中的撤销池。在新机制出现之前,大多数系统运行时只有一个重做分配锁存器,所以尽管我们现在使用内存中的撤销锁存器的次数与使用重做分配锁存器的次数一样多,但我们正在将访问扩展到更多的锁存器。
Earlier on we saw that every change we made resulted in an access to the In memory undo latch. Does that mean we have just moved the threat of latch activity rather than actually relieving it? Yes and no. We now hit only one latch (In memory undo latch) instead of two (redo allocation and redo copy), so we have at least halved the latch activity, but, more significantly, there are multiple child latches for the In memory undo latches, one for each in-memory undo pool. Before the new mechanism appeared, most systems ran with just one redo allocation latch, so although we now hit an In memory undo latch just as many times as we used to hit the redo allocation latch, we are spreading the access across far
more latches.
另外值得注意的是,新机制还具有两种重做分配闩锁:一种覆盖私有重做线程,一种覆盖公共重做线程,每个线程都有自己的闩锁。这有助于解释我们前面看到的重做分配闩锁统计的额外收获:我们的会话使用私有重做分配闩锁来获取私有重做线程,然后在提交时必须获取公共重做分配闩锁,然后日志编写器(我们将在第6章中看到)获取公共重做分配锁存(我的测试系统有两个公共重做线程)来将日志缓冲区写入文件。
It’s also worth noting that the new mechanism also has two types of redo allocation latch—one type covers the private redo threads, one type covers the public redo threads, and each thread has its own latch. This helps to explain the extra gets on the redo allocation latch statistic that we saw earlier: our session uses a private redo allocation latch to acquire a private redo thread, then on the commit it has to acquire a public redo allocation latch, and then the log writer (as we shall see in Chapter 6) acquires the public redo allocation latches (and my test system had two public redo threads) to write the log buffer to file.
总的来说 ,latch 活动的数量减少了, latch 活动的分布得更广了,这是一件好事。但是在多用户系统中,总是有其他的观点需要考虑—使用旧的机制,在任何时刻复制到日志缓冲区并应用到数据库块的会话的重做量非常小;使用这种新机制,复制和应用的重做量可能相对较大,这意味着将更多的时间应用于数据库块,这可能会阻止其他会话在进行更改时访问这些块。这可能是私有重做线程在大小上受到严格限制的原因之一。
Overall, then, the amount of latch activity decreases and the focus of latch activity is spread a little more widely, which is a good thing. But in a multiuser system, there are always other points of view to consider—using the old mechanism, the amount of redo a session copied into the log buffer and applied to the database blocks at any one instant was very small; using the new mechanism, the amount of redo to copy and apply could be relatively large, which means it takes more time to apply to the database blocks, potentially blocking other sessions from accessing those blocks as the changes are made. This may be one reason why the private redo threads are strictly limited in size.
此外,使用旧的机制, 第二个会话会立即看到数据的修改 ;使用新机制,第二个会话只能看到一个块受到一些私有重做的影响,所以第二个会话现在负责跟踪私有重做并将其应用到块(如果需要),然后决定接下来对块做什么。(如果您不能立即看到另一个会话删除了您需要的主键,请考虑引用完整性的问题) 这会导致另一个问题, 代码更长更复杂, 我们需要使用更多的CPU资源来获取读一致性。
Moreover, using the old mechanism, a second session reading a changed block would see the changes immediately; with the new mechanism, a second session can see only that a block is subject to some private redo, so the second session is now responsible for tracking down the private redo and applying it to the block (if necessary), and then deciding what to do next with the block. (Think about the problems of referential integrity if you can’t immediately see that another session has, for example, deleted a primary key that you need.) This leads to longer code paths, and more complex code, but even if the resulting code for read consistency does use more CPU than it used to, there is always an argument for making several sessions use a little more CPU as a way of avoiding a single point of contention.
Note 注意
有一个重要的优化原则经常被忽视。有时,如果这意味着每个人都在不同的地点工作,而不是不断地在同一个竞争点上冲突,那么最好每个人都多做一点工作——竞争 会 浪费资源。
There is an important principle of optimization that is often overlooked. Sometimes it is better for everyone to do a little more work if that means they are operating in separate locations rather than constantly colliding on the same contention point—competition wastes resources.
我不知道有多少不同的事件 events 可以迫使会话从私有重做 private redo 和撤消 undo 中构造新版本的块,但我知道有几个事件会导致会话在提交之前放弃新策略。
I don’t know how many different events there are that could force a session to construct new versions of blocks from private redo and undo, but I do know that there are several events that result in a session abandoning the new strategy before the commit.
当私有重做线程 private redo thread或内存中的撤消池in-memory undo pool已满时,Oracle必须放弃这种新机制。正如我们前面看到的,每个私有区域被限制在大约64KB(如果运行的是64位的Oracle,则为128KB)。当一个区域已满时,Oracle创建一个redo记录,将其复制到公共redo线程,然后继续以旧方式使用公共redo线程。
An obvious case where Oracle has to abandon the new mechanism is when either the private redo thread or the in-memory undo pool becomes full. As we saw earlier, each private area is limited to roughly 64KB (or 128KB if you’re running a 64-bit copy of Oracle). When an area is full, Oracle creates a single redo record, copies it to the public redo thread, and then continues using the public redo thread in the old way.
但还有其他一些事件过早地导致了这种转变。例如,您的SQL可能触发一个递归语句。为了快速检查可能的原因,以及每种原因发生的次数,可以 用 SYS 用户 连接 数据库 并运行以下SQL( 示例 10.2.0.3):
But there are other events that cause this switch prematurely. For example, your SQL might trigger a recursive statement. For a quick check on possible causes, and how many times each has occurred, you could connect as SYS and run the following SQL (sample taken from 10.2.0.3):
select ktiffcat, ktiffflc from x$ktiff;

不幸的是,尽管在v$sysstat动态性能视图中有各种与IMU相关的统计数据(例如,IMU刷新),但它们似乎与x$structure中的数字没有太好的关联,尽管如果忽略其中的几个数字,您可能会非常接近地认为找到了匹配的位。
Unfortunately, although there are various statistics relating to IMU in the v$sysstat dynamic performance view (e.g., IMU flushes), they don’t seem to correlate terribly well with the figures from the x$ structure—although, if you ignore a couple of the numbers, you can get quite close to thinking you’ve found the matching bits.
四: Undo Complexity --- Undo复杂性
Undo 比 Redo 更复杂。 理论 上任何进程在任何时候 都可能 访问任何撤销记录undo record, 来 “隐藏”还不应该看到的数据项。为了有效地满足这个需求,Oracle将undo记录保存在数据库中的一个特殊的表空间中,这个表空间被称为undo表空间。然后,代码必须维护指向撤消记录的各种指针,以便进程知道在哪里可以找到它需要的撤消记录。将撤消信息undo information保存在“普通”数据文件的数据库中的优点是,这些块与数据库中的每个块所受的缓冲、写入和恢复算法完全相同 , 管理撤消块的基本代码与处理其他类型块的代码相同。
Undo is more complicated than redo. Most significantly, any process may, in principle, need to access any undo record at any time to “hide” an item of data that it is not yet supposed to see. To meet this requirement efficiently, Oracle keeps the undo records inside the database in a special tablespace known, unsurprisingly, as the undo tablespace; then the code has to maintain various pointers to the undo records so that a process knows where to find the undo records it needs. The advantage of keeping undo information inside the database in “ordinary” data files is that the blocks are subject to exactly the same buffering, writing, and recovery algorithms as every block in the database—the basic code to manage undo blocks is the same as the code to handle every other type of block.
进程需要读取undo记录的原因有三个,因此指针链通过undo表空间的方式有三种。我们将在第3章中详细讨论这三种方法,但是我将对目前最常见的两种方法做一些初步的评论。
There are three reasons why a process needs to read an undo record, and therefore three ways in which chains of pointers run through the undo tablespace. We will examine all three in detail in Chapter 3, but I will make some initial comments about the commonest two uses now.
注意
撤销记录 undo records 的链表用于处理读一致性、回滚更改以及派生由于延迟块清除而“丢失”的提交scn。第三个主题将推迟到第三章
Note
Linked lists of undo records are used to deal with read consistency, rolling back changes, and deriving commit SCNs that have been “lost” due to delayed block cleanout. The third topic will be postponed until Chapter 3.
4.1 Read Consistency 读一致性
第一个也是最常调用的undo用法是read consistence,我已经对read consistence做了简要的评论。UNDO的存在允许会话在尚未看到较新版本的情况下看到旧版本的数据。
The first, and most commonly invoked, use of undo is read consistency, and I have already commented briefly on read consistency. The existence of undo allows a session to see an older version of the data when it’s not yet supposed to see a newer version.
读取一致性的要求意味着一个块必须包含一个指向undo记录的指针,undo记录描述了如何隐藏对块的更改。但是,可能有大量的更改需要隐藏,而且在一个块中没有足够的空间容纳这么多指针。因此,Oracle允许每个块中的指针数量有限(每个影响块的并发事务一个指针),这些指针存储在ITL条目中。当一个进程创建一个undo记录时,它(通常)会覆盖一个现有的指针,将之前的值保存为undo记录的一部分。
The requirement for read consistency means that a block must contain a pointer to the undo records that describe how to hide changes to the block. But there could be an arbitrarily large number of changes that need to be concealed, and insufficient space for that many pointers in a single block. So Oracle allows a limited number of pointers in each block (one for each concurrent transaction affecting the block), which are stored in the ITL entries. When a process creates an undo record, it (usually) overwrites one of the existing pointers, saving the previous value as part of the undo record.
在更新了一个块中的三行 数据 后,再看一看我前面显示的撤消记录 :
Take another look at the undo record I showed you earlier, after updating three rows in a single block:
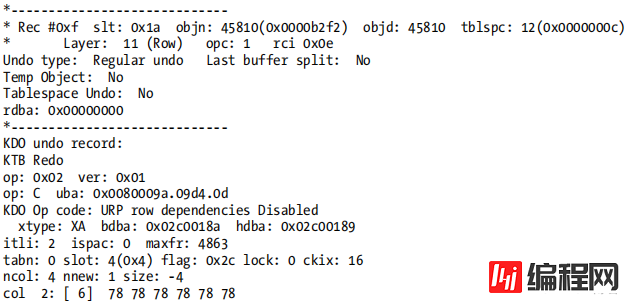
这个撤销记录显示我更新的第五行的表块指向,我们可以从转储的第二行看到撤销块中的记录0xf。从转储的底部向上七行可以看到,这个记录有op:C,它告诉我们,它是同一事务先前更新的延续。这使Oracle知道行uba:0x0080009a.09d4.0d的其余部分是用于重新创建块的旧版本的信息的一部分:由于将xxxxxx(78s)复制回第4行的第2列,因此必须将值0x0080009a.09d4.0d复制回ITL条目2。
The table block holding the fifth row I had updated was pointing to this undo record, and we can see from the second line of the dump that it is record 0xf in the undo block. Seven lines up from the bottom of the dump you see that this record has op: C, which tells us that it is the continuation of an earlier update by the same transaction. This lets Oracle know that the rest of the line uba: 0x0080009a.09d4.0d is part of the information that has to be used to re-create the older version of the block: as the xxxxxx (78s) are copied back to column 2 of row 4, the value 0x0080009a.09d4.0d has to be copied back to ITL entry 2.
当然,一旦Oracle采取了这些步骤来重建一个旧版本的块,它将发现数据还没有走得足够远,但是ITL 2中的指针现在告诉它在哪里找到下一个要应用的undo记录。这样,一个过程就可以随着时间的推移而逐渐倒退;每个ITL条目中的指针告诉Oracle在何处应用撤消记录,每个撤消记录包含使ITL条目在时间上向后以及使数据在时间上向后的信息。
Of course, once Oracle has taken these steps to reconstruct an older version of the block, it will discover that it hasn’t yet gone far enough, but the pointer in ITL 2 is now telling it where to find the next undo record to apply. In this way a process can gradually work its way backward through time; the pointer in each ITL entry tells Oracle where to find an undo record to apply, and each undo record includes the information to take the ITL entry backward in time as well as taking the data backward in time.
4.2 Rollback
第二,撤销的主要用途是回滚更改,可以使用显式回滚(或回滚到保存点),也可以因为事务中的某个步骤失败而Oracle发出了隐式的语句级回滚 。
读取一致性是关于单个块,并找到该块的所有撤消记录的链接列表。回滚与事务的历史有关,因此我们需要一个链表,它以正确的顺序(在本例中,这意味着反向)遍历事务的所有undo记录。
The second, major use of undo is in rolling back changes, either with an explicit rollback (or rollback to savepoint) or because a step in a transaction has failed and Oracle has issued an implicit, statement-level rollback.
Read consistency is about a single block, and finding a linked list of all the undo records for that block. Rolling back is about the history of a transaction, so we need a linked list that runs through all the undo records for a transaction in the correct (which, in this case, means reverse) order.
注意
下面是一个简单的例子,演示了为什么需要“反向”链接撤销记录。“假设我们更新一行两次,将单个列值从 A 更改为B,然后从B更改为C,从而得到两条undo记录。如果我们想要逆转改变,我们必须先把C变回B,然后才能应用“把B变回 A ”的撤销记录;换句话说,我们必须在应用第一个撤消记录之前应用第二个撤消记录 。
Note
Here is a simple example demonstrating why we need to link the undo records “backward.” Imagine we update a row twice, changing a single column value from A to B and then from B to C, giving us two undo records. If we want to reverse the change, we have to change the C back to B before we can apply an undo record that says “change a B to an A”; in other words, we have to apply the second undo record before we apply the first undo record.
再次查看示例undo记录,我们可以看到链表的迹象。转储的第3行包括rci 0x0e条目。这告诉Oracle在这个undo记录之前立即创建的undo记录是同一个undo块中的第14号(0x0e)。这是有可能的,当然,之前的取消记录将在一个不同的撤销,但应该只有当前撤销撤销块的记录是第一个取消记录,在这种情况下,rci条目将零和rdba:条目下面四行给前面的块地址取消记录。如果必须返回一个块,那么块的最后一条记录通常是必需的记录,尽管从技术上讲,您需要的是irb: entry指向的记录。但是,如果您已经回滚到savepoint,那么irb: entry可能不会指向最后一条记录。
Looking again at the sample undo record, we can see signs of the linked list. Line 3 of the dump includes the entry rci 0x0e. This tells Oracle that the undo record created immediately before this undo record was number 14 (0x0e) in the same undo block. It’s possible, of course, that the previous undo record will be in a different undo block, but that should be the case only if the current undo record is the first undo record of the undo block, in which case the rci entry would be zero and the rdba: entry four lines below it would give the block address of the previous undo record. If you have to go back a block, then the last record of the block will usually be the required record, although technically what you need is the record pointed at by the irb: entry. However, the only case in which the irb: entry might not point to the last record is if you have done a rollback to savepoint.
读一致性和回滚之间有一个重要的区别。为了读取一致性,我们复制了内存中的数据块并将撤销记录undo records应用到那个块 data block 上,一旦我们完成了它,我们就可以很快地丢弃它;当回滚时,我们获取当前块current block并对其应用undo record。这有三个重要的影响 :
There’s an important difference between read consistency and rolling back, of course. For read consistency we make a copy of the data block in memory and apply the undo records to that block, and it’s a copy of the block that we can discard very rapidly once we’ve finished with it; when rolling back we acquire the current block and apply the undo record to that. This has three important effects:
1.数据块 data block 是当前的块 current block ,因此它是最终必须写入到磁盘的块的版本。
2. 因为它是当前块,所以当我们更改它时,将生成 redo (即使我们“将它更改回原来的方式”)。
3.因为Oracle有尽可能高效地清理事故的崩溃恢复机制,所以我们需要确保在使用undo记录时将其标记为“undo applied”,这样做会生成更多的重做。
1. The data block is the current block, so it is the version of the block that must
eventually be written to disc.
2. Because it is the current block, we will be generating redo as we change it (even
though we are “changing it back to the way it used to be”).
3. Because Oracle has crash-recovery mechanisms that clean up accidents as
efficiently as possible, we need to ensure that the undo record is marked as “undo
applied” as we use it, and doing that generates even more redo.
如果undo记录已经被用于回滚,那么转储的第4行应该是这样的
If the undo record was one that had already been used for rolling back, line 4 of the dump would have looked like this:
Undo type: Regular undo User Undo Applied Last buffer split: No
在原始块转储中,用户撤销应用的标志只有1个字节,而不是一个17个字符的字符串。
回滚涉及大量工作,而且回滚所花费的时间与原始事务所花费的时间大致相同,可能会生成类似数量的重做。但是您必须记住,回滚是一个更改数据块的活动,因此您必须重新获取、修改和编写这些块,并编写描述您如何更改这些块的重做。此外,如果事务是一个大型的长时间运行的事务,您可能会发现您更改的一些块已经被写入到磁盘并从缓存中清除了—所以在您可以回滚它们之前,必须从磁盘读取它们到内存!
In the raw block dump, the User Undo Applied flag is just 1 byte rather than a 17-character string.
Rolling back involves a lot of work, and a rollback can take roughly the same amount of time as the original transaction, possibly generating a similar amount of redo. But you have to remember that rolling back is an activity that changes data blocks, so you have to reacquire, modify, and write those blocks, and write the redo that describes how you’ve changed those blocks. Moreover, if the transaction was a large, long-running transaction, you may find that some of the blocks you’ve changed have been written to disc and flushed from the cache—so they’ll have to be read from disc before you can roll them back!
注意
有些系统使用Oracle表来保存“临时”或“暂存”信息。使用的策略之一是插入数据而不提交数据,这样读一致性使其成为会话的私有数据,然后回滚使数据“消失”。这一战略存在许多缺陷,回滚的潜在高成本只是其中之一。可以使用全局临时表代替这种策略。
Note
Some systems use Oracle tables to hold “temporary” or “scratchpad” information. One of the strategies used with such tables is to insert data without committing it so that read consistency makes it private to the session, and then roll back to make the data “go away.” There are many flaws in this strategy, the potentially high cost of rolling back being just one of them. The ability to eliminate the cost of rollback is one of the things that makes global temporary tables useful.
当然,通过回滚还会引入其他开销。当一个会话创建撤消记录时,它一次获取、固定和填充一个撤消块;当它回滚时,它一次从undo块获取一条记录,释放并重新获取每个记录的块。这意味着在撤消块上生成的回滚缓冲区访问比最初执行事务时生成的要多。而且,每次Oracle获得undo记录时,它都会检查应该应用到的表空间是否仍然在线(如果不是,Oracle会将undo记录转移到system表空间中的save undo段);这在字典缓存(特别是dc_tablespaces缓存)上显示为get。
There are other overheads introduced by rolling back, of course. When a session creates undo records, it acquires, pins, and fills one undo block at a time; when it is rolling back it gets one record from an undo block at a time, releasing and reacquiring the block for each record. This means that you generate more buffer visits on undo blocks to roll back than you generated when initially executing the transaction. Moreover, every time Oracle acquires an undo record, it checks that the tablespace it should be applied to is still online (if it isn’t, Oracle will transfer the undo record into a save undo segment in the system tablespace); this shows up as get on the dictionary cache (specifically the dc_tablespaces cache).
我们可以用最后一个 特殊 的小细节来结束关于回滚的评论。如果会话发出回滚命令,则完成回滚的步骤是提交。我们会在第三章多花一点时间在这上面 。
We can finish the comments on rolling back with one last quirky little detail. If your session issues a rollback command, the step that completes the rollback is a commit. We’ll spend a little more time on that in Chapter 3.
Summary 总结:
在某些方面,redo 重做是一个非常简单的概念:数据文件中对块的每个更改都用重做更改向量redo change vector来描述,并且这些更改向量被立即写入重做日志缓冲区redo log buffer(几乎是),并最终写入重做日志文件redo log file。
In some ways redo is a very simple concept: every change to a block in a data file is described by a redo change vector, and these change vectors are written to the redo log buffer (almost) immediately, and are ultimately written into the redo log file.
当我们对数据(包括索引项和结构元数据)进行更改时,我们还在undo表空间中创建undo记录,这些记录描述了如何逆转这些更改。由于undo表空间只是另一组数据文件,所以我们创建了redo change vector来描述我们存储在那里的undo记录 。
As we make changes to data (which includes index entries and structural metadata), we also create undo records in the undo tablespace that describe how to reverse those changes. Since the undo tablespace is just another set of data files, we create redo change vectors to describe the undo records we store there.
在Oracle的早期版本中,更改向量change vectors通常以成对的形式组合在一起—一个描述正向更改forward change,一个描述撤消记录undo record— 把这一对record合并成一个redo record,并写入到 redo log buffer 。
In earlier versions of Oracle, change vectors were usually combined in pairs—one describing the forward change, one describing the undo record—to create a single redo record that was written (initially) into the redo log buffer.
在Oracle的较新版本中,OLTP系统中将更改向量change vectors移动到重做日志缓冲区redo log buffer的步骤被视为的一个重要瓶颈,并 引入 一个新机制, 将一个会话里的所有操作存放在 private redo log buffer中,事务完成后在一起写入到public redo log buffer。
In later versions of Oracle, the step of moving change vectors into the redo log buffer was seen as an important bottleneck in OLTP systems, and a new mechanism was created to allow a session to accumulate all the changes for a transaction “in private” before creating one large redo record in the redo buffer.
新机制严格限制了会话在将其更改向量刷新到重做日志缓冲区并切换到旧机制之前所做的工作,并且有各种各样的事件会使这种切换提前发生。
The new mechanism is strictly limited in the amount of work a session will do before it flushes its change vectors to the redo log buffer and switches to the older mechanism, and there are various events that will make this switch happen prematurely.
当redo作为一个简单的“写 入---忽略 ”流操作时,undo可能会在数据库的当前活动中频繁地重新读取,而undo记录必须以不同的方式链接在一起,以实现有效的访问。读取一致性Read consistency要求给定块的撤销记录链;回滚 rolling back需要一个给定事务的撤销记录链。(还有第三条链,将在第三章中讨论。)
While redo operates as a simple “write it and forget it” stream, undo may be frequently reread in the ongoing activity of the database, and undo records have to be linked together in different ways to allow for efficient access. Read consistency requires chains of undo records for a given block; rolling back requires a chain of undo records for a given transaction. (And there is a third chain, which will be addressed in Chapter 3.)
2020-02-02 陈举超
---翻译整理自
《Oracle Core Essential Internals for DBAs and Developers》
Chapter 2:Redo and Undo
欢迎关注我的微信公众号"IT小Chen",共同学习,共同成长!!!


--结束END--
本文标题: Oracle Redo and Undo
本文链接: https://lsjlt.com/news/45301.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0