这篇文章主要介绍“Mysql的binlog、redo log和undo log怎么使用”,在日常操作中,相信很多人在mysql的binlog、redo log和undo log怎么使用问题上存在疑惑,小编查
这篇文章主要介绍“Mysql的binlog、redo log和undo log怎么使用”,在日常操作中,相信很多人在mysql的binlog、redo log和undo log怎么使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Mysql的binlog、redo log和undo log怎么使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!

binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。binlog是mysql的逻辑日志,并且由Server层进行记录,使用任何存储引擎的mysql数据库都会记录binlog日志。
逻辑日志:可以简单得理解为sql语句;
物理日志:MySQL中数据都是保存在数据页中的,物理日志记录的是数据页上的变更;在这里插入代码片
binlog是通过追加的方式进行写入的,可以通过max_binlog_size参数设置每个binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
binlog使用场景
项目 在实际应用中,binlog的主要使用场景有两个,分别是主从复制和数据恢复。
主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致。
数据恢复:通过使用mysqlbinlog工具来恢复数据。
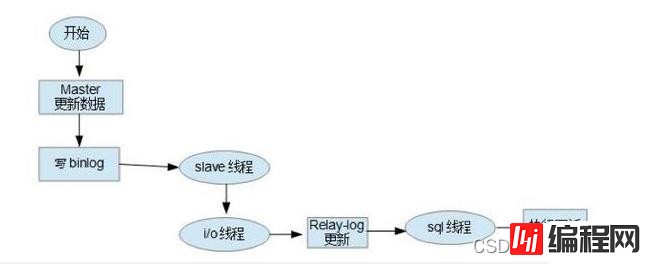
MySQL主从同步原理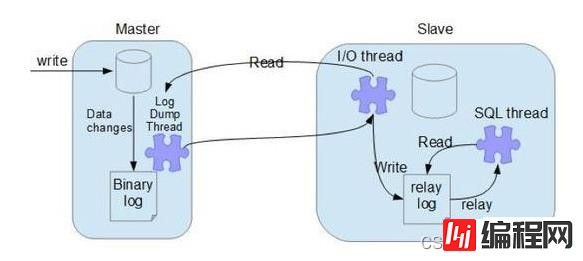
主节点 binlog dump 线程
当从节点连接主节点时,主节点会创建一个log dump 线程,用于发送binlog的内容。在读取binlog中的操作时,此线程会对主节点上的binlog加锁,当读取完成,甚至在发动给从节点之前,锁会被释放;
从节点I/O线程
当从节点上执行start slave命令之后,从节点会创建一个I/O线程用来连接主节点,请求主库中更新的binlog。I/O线程接收到主节点binlog dump进程发来的更新之后,保存在本地relaylog中;
从节点SQL线程
SQL线程负责读取relaylog中的内容,解析成具体的操作并执行,最终保证主从数据的一致性;
MySQL 数据库主从同步原理
binlog的内容
上面说了,binlog是一种逻辑日志,可以简单得理解为sql语句,但是实际上还包含着执行的sql语句的反向逻辑。delete对应着delete本身以及反向的insert信息;update包含着对应的update执行前后数据行的相关信息;insert包含自身的insert以及对应的delete信息。
binlog的格式
binlog共有三种格式,分别是statement、row以及mixed。MySQL 5.7.7版本之前默认使用的是statement,MySQL 5.7.7之后默认使用的是row。日志的格式可以通过my.ini配置文件中的binlog-fORMat来修改。
(1)statement:基于sql语句的复制(statement-based replication,SBR),每一条修改数据的sql语句都会记录到binlog中。
优点:不需要具体记录某一行的变化,节约空间,减少io,提高性能;
缺点:在执行sysdate()或者sleep()等操作的时候,可能导致主从数据不一致的情况;
(2)row:基于行记录的复制(row-based replication,RBR),不记录sql语句上下文相关信息,而是记录哪条记录被修改的细节。
优点:非常详细地记录每一行记录修改的细节,因而不会出现数据无法被正确复制的情况;
缺点:由于会非常详细地记录每一条记录修改的细节,这样会产生大量的日志内容。假设现在有一条update语句,修改了很多条记录,则每条修改记录都会记录到binlog中。特别地,alter table这个操作,由于表结构的变化,每行记录都会发生变化,导致日志量暴增;
(3)mixed:根据上面所说的,statement和row各有优缺点,因此出现了mixed这个版本,将这二者进行混合。一般情况下使用statement格式来进行保存,当遇到statement无法解决时,切换为row格式来进行保存。
特别地,上面说了,新版本(MySQL 5.7.7之后)默认使用的row格式,这里的row也做了相应的优化,在遇到alter table这个操作时采用statement格式进行记录,其余操作仍然使用row格式。
binlog刷盘时机
对于InnoDB存储引擎来说,只有在事务提交的时候才会记录binlog,此时记录还在内存中,MySQL通过sync_binlog来控制binlog的刷盘时机,取值范围为0-N:
0:不强制刷到磁盘,由系统自行判断何时写入磁盘中;
1:每次提交后都要将binlog写入磁盘中;
N:每N个事务,才会将binlog写入磁盘中;
从上面可以看出,sync_binlog最安全的是设置是1,这也是MySQL 5.7.7之后版本的默认值。但是设置一个大一些的值可以提升数据库性能,因此实际情况下也可以将值适当调大,牺牲一定的一致性来获取更好的性能。
binlog的物理文件大小
在my.ini配置文件中,可以通过max_binlog_size来配置binlog的大小。当日志量超过binlog文件的大小时,系统会重新生成一个新的文件来继续保存文件。当一个事务比较大时,或者是当日志越来越多的时候,此时占据的物理空间太大怎么办?MySQL提供了一种自动删除的机制,还是在my.ini配置文件中,可以通过配置expire_logs_days这个参数来解决,单位为天。当这个参数为0,表示永不删除;为N时,表示第N天后自动删除。
redolog是InnoDB引擎专有的日志系统。主要是用来实现事务的持久性以及实现crash-safe功能。redolog属于物理日志,记录的是sql语句执行之后数据页上的具体修改内容。
我们都知道,当MySQL运行的时候,会将数据从磁盘中加载到内存当中。当执行sql语句对数据进行修改时,修改后的内容其实都只是暂时保存到内存当中,如果此时断电或者出现其他情况,这些修改就会丢失。因而,当修改完数据之后,MySQL会寻找机会将这些内存中的记录刷回到磁盘当中。但这就出现一个性能问题,主要有两个方面:
InnoDB中是以页为数据单位与磁盘进行交互的,而一个事务很可能只是修改了一个页上的几个字节,如果将一个完整的数据页刷回磁盘当中,浪费资源;
一个事务可能涉及到多个数据页,这些数据页只是逻辑上连续,在物理上并不连续,使用随机IO性能太差;
因此,MySQL设计了redolog来记录事务对数据页具体做了哪些修改,之后将redolog再刷回磁盘当中。你可能会有疑惑,本来就是想减少io,这不又加上一次io么?InnoDB的设计者在设计之初就已经考虑到了这些。redolog文件一般都比较小,且在刷回磁盘的过程中是顺序io,相比于随机io来说,性能更好。
redo log基本概念
redolog由两部分组成,一个是内存中的日志缓存redo log buffer,一个是磁盘中的日志文件redo log file。当每次对数据记录进行修改的时候,都会将这些修改内容先写入redo log buffer中,后续等待合适的时机将内存中的修改刷回到redo log file中。这种先写日志,再写磁盘的技术就是WAL(Write-Ahead Logging)技术。需要注意的是redolog比数据页先刷回磁盘,聚簇索引,二级索引,undo页面的修改,均需要记录redolog。
在计算机操作系统中,用户空间(user space)下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间(kernel space)缓冲区(OS Buffer)。因此,redo log buffer写入redo log file实际上是先写入OS Buffer,然后再通过系统调用fsync()将其刷到redo log file中,过程如下: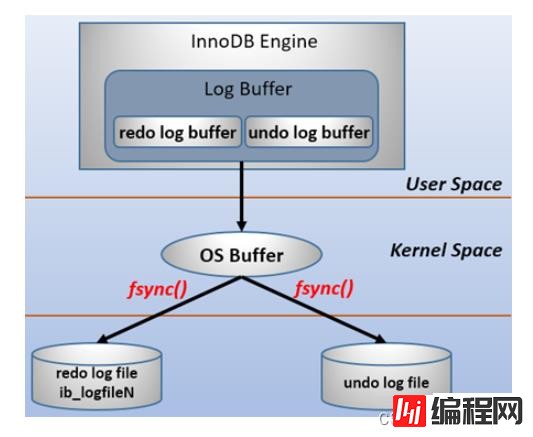
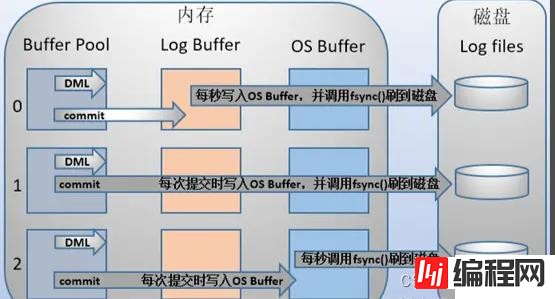
mysql支持三种将redo log buffer写入redo log file的时机,可以通过innodb_flush_log_at_trx_commit参数配置,各参数值含义如下:
| 参数值 | 含义 |
|---|---|
| 0(延迟写) | 事务提交时不会将redo log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到redo log file中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。 |
| 1(实时写,实时刷) | 事务每次提交都会将redo log buffer中的日志写入os buffer并调用fsync()刷到redo log file中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。 |
| 2(实时写,延迟刷) | 每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到redo log file。 |
redo log记录形式
redolog采用固定大小,循环写入的格式,当redolog写满之后,会重新从头开始写。为什么这么设计呢?
redo log存在的意义主要就是降低对数据页刷盘的要求。redolog记录了数据页上的修改,但是当数据页也刷回到磁盘后,这些记录就失去作用了。因此当MySQL判断之前的redolog已经失去作用之后,新数据会将这些失效的数据进行覆盖。那如何判断该不该进行覆盖呢?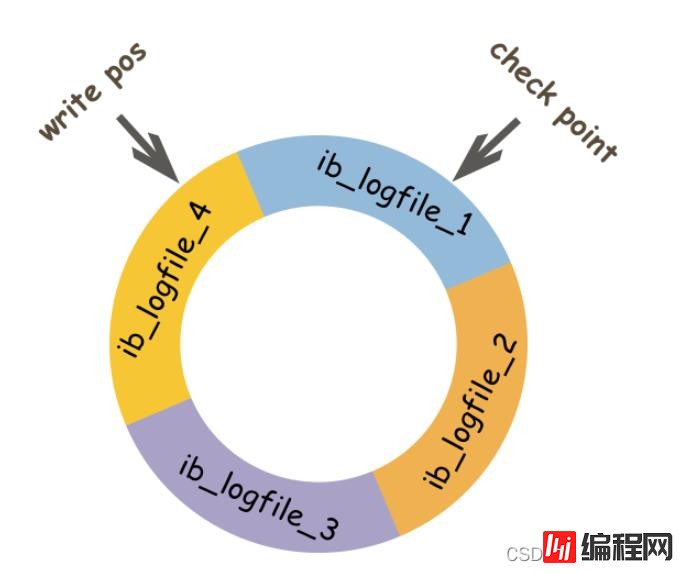
上图是redo log file的示意图,write pos表示redolog当前记录的日志序列号LSN(log sequence number)。当数据页也已经刷回磁盘之后,会更新redo log file中的LSN,表示到这个LSN之前的数据已经落盘,这个LSN就是check point。write pos到check point之间的部分是redolog空余的部分,用于记录新的记录;check point到write pos之间是redolog已经记录的数据页修改部分,但此时数据页还未刷回磁盘的部分。当write pos追上check point时,会先推动check point向前移动,空出位置再记录新的日志。
启动innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。恢复时,会先检查数据页中的LSN,如果这个LSN小于redolog中的LSN,即write pos位置,说明在redolog上记录着数据页上尚未完成的操作,接着就会从最近的一个check point出发,开始同步数据。
那有没有可能数据页中的LSN大于redolog中的LSN呢?答案是当然可能。出现这种情况时,这时超出redolog的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
redo log与binlog区别
| redo log | binlog | |
|---|---|---|
| 文件大小 | redo log的大小是固定的。 | binlog可通过配置参数max_binlog_size设置每个binlog文件的大小。 |
| 实现方式 | redo log是InnoDB引擎层实现的,并不是所有引擎都有。 | binlog是Server层实现的,所有引擎都可以使用 binlog日志 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | binlog 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 适用场景 | redo log适用于崩溃恢复(crash-safe) | binlog适用于主从复制和数据恢复 |
由binlog和redo log的区别可知:binlog日志只用于归档,只依靠binlog是没有crash-safe能力的。但只有redo log也不行,因为redo log是InnoDB特有的,且日志上的记录落盘后会被覆盖掉。因此需要binlog和redo log二者同时记录,才能保证当数据库发生宕机重启时,数据不会丢失。
两阶段提交
上面简单介绍了redolog和binlog,在对数据进行修改时,他们都会对这些修改进行保存落地,只是一个是物理日志,一个是逻辑日志。那他俩具体在修改过程中是如何执行的呢?
假设现在有一条update语句要执行,update from table_name set c=c+1 where id=2,执行流程如下:
先定位到id=2这一条记录;
执行器拿到引擎给的行数据,把这个值加上 1,得到新的一行数据,再调用引擎接口写入这行新数据;
引擎将这行新数据更新到内存中,同时将这个更新操作记录到redolog里面,此时 redolog 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务;
执行器生成这个操作的 binlog,并把binlog写入磁盘;
执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成;
示意图如下所示: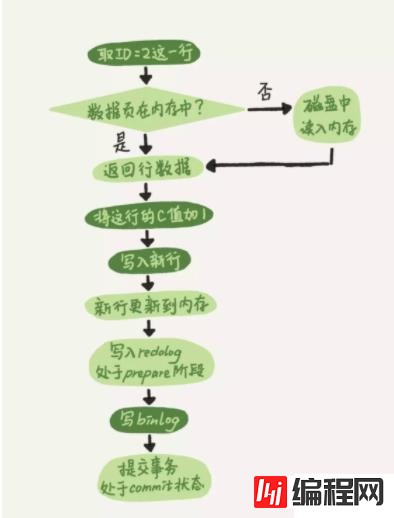
这种将redolog的写入拆分成prepare和commit两个步骤的过程称之为两阶段提交。
redolog 和binlog都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。如果不使用两阶段提交,而是先写其中一个再写另外一个可能会带来一些问题。
此时还是使用update来举例。假设当前id=2,有一个字段c=0,分别分析以下情况:
先写redolog再写binlog
假设先写redolog,当redolog写完,但是binlog还未写完的时候,此时MySQL突然出现异常导致重启。由于之前redolog已经写完,系统重启后,修改的记录仍然存在,所以恢复后这一行 c 的值是 1。但由于系统重启,binlog中并未有这条记录。之后备份日志的时候,存起来的binlog里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的binlog丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
先写binlog再写redolog
假如先写binlog,然后写redolog的时候系统重启。重启之后,redolog中没有对c进行修改的记录,此时c的值还是0。但是 binlog里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
因此,综上所述,如果是先写某一个日志再写另一个日志,就会出现数据库的状态与使用binlog恢复出来的库的状态不一致的情况。
undolog主要用来记录某条行记录被修改之前的状态,记录的是修改前的数据。这样的话,当事务进行回滚时,就可以通过undolog将记录恢复到事务开始前的样子。事务的原子性和持久性也是依靠undolog来实现的。undo log主要记录了数据的逻辑变化,比如一条INSERT语句,对应一条DELETE的undo log,对于每个UPDATE语句,对应一条相反的UPDATE的undo log,这样在发生错误时,就能回滚到事务之前的数据状态。同时,在进行数据恢复的时候,与binlog,redolog结合使用,保证了数据恢复的正确性。
undolog的作用流程如下所示:
在事务开始之前将修改前的版本写入到undo log中;
开始进行修改,将修改过的数据保存到内存当中;
将undolog持久化到磁盘当中;
将数据页刷回到磁盘当中;
事务提交;
需要注意的是,与redolog一样,undolog也是要先于数据页刷回到磁盘当中。在恢复数据时,如果undolog是完整的,可以根据undolog来回滚事务。
在一个事务当中,可能会对同一条数据进行多次修改,那么是不是每一次修改前的记录都要记录到undolog中呢?这样的话,会导致undolog日志量太大,此时redolog就要上场了。在一个事务当中,如果是对同一条记录进行修改,undolog只会记录事务开始前的原始记录,当再次对这条记录进行修改时,redolog会记录后续的变化。在数据恢复时,redolog完成前滚,undolog完成回滚,二者相互协调完成数据的恢复。过程如下所示:
到此,关于“MySQL的binlog、redo log和undo log怎么使用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: MySQL的binlog、redo log和undo log怎么使用
本文链接: https://lsjlt.com/news/72062.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0