这篇文章主要介绍如何使用selenium+chromedriver+xpath爬取动态加载信息,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!使用selenium实现动态渲染页面的爬取,selenium是浏览器自动化测
这篇文章主要介绍如何使用selenium+chromedriver+xpath爬取动态加载信息,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
使用selenium实现动态渲染页面的爬取,selenium是浏览器自动化测试框架,是一个用于WEB应用程序测试的工具,可以直接运行在浏览器当中,并可以驱动浏览器执行指定的动作,如点击、下拉、填充数据、删除cookie等操作,还可以获取浏览器当前页面的源代码,就像用户在浏览器中操作一样。该工具所支持的浏览器有IE浏览器、Mozilla Firefox以及Google Chrome等。
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium“命令(如果没有安装Anaconda, 可以在cmd命令行窗口中执行安装模块的命令),接着按下(回车)键,如下图:
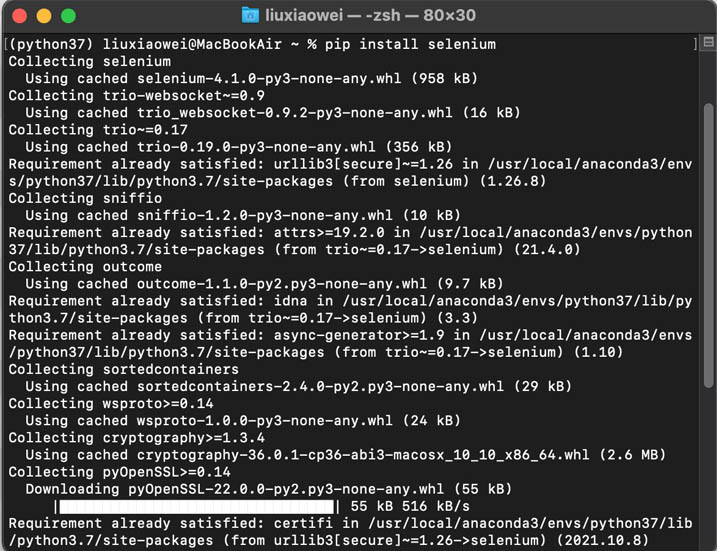
selenium有很多语言的版本,比如:Java、Ruby、python等。
下载浏览器驱动
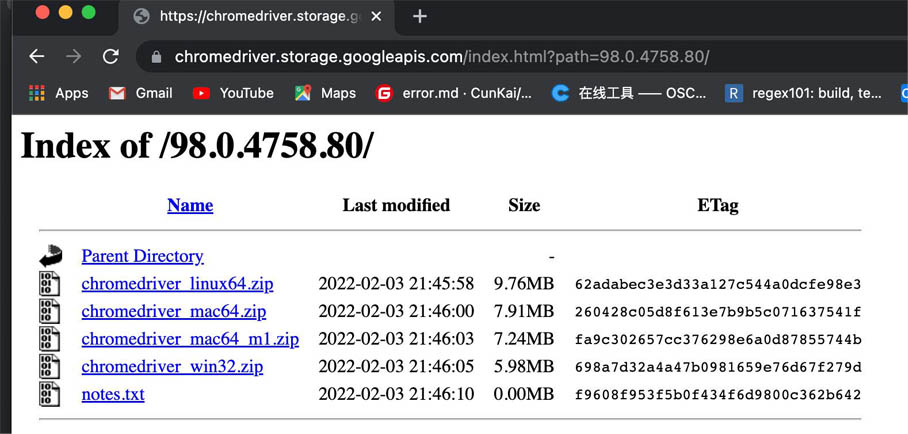
selenium模块安装完成以后还需要选择一个浏览器,然后下载对应的浏览器驱动,此时才可以通过selenium模块来控制浏览器的操作。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build) (x86_64),然后在(Http://chromedriver.storage.Googleapis.com/index.html?path=98.0.4758.80/)谷歌浏览器驱动中下载浏览器驱动。如下图:
说 明
在下载谷歌浏览器驱动时,根据自己的电脑系统下载对应的浏览器驱动。
谷歌浏览器驱动下载完成后, 将名称为chromedriver.exe文件拖放到/usr/bin 目录下(Python.exe文件的同级路径)。然后需要通过Python代码进行谷歌浏览器驱动的加载,这样才可以启动浏览器驱动并控制浏览器了。
针对不同浏览器有不同的driver。以下列出不同浏览器及其对应的driver,如下表:
| Browers | Driver | Link |
|---|---|---|
| Chrome | Chromedriver(.exe) | http://chromedriver.storage.googleapis.com/index.html |
| Internet Explorer | IEDriverServer.exe | http://selenium-release.storage.googleapis.com/index.html |
| Edge | MicrosoftWebDriver.msi | http://go.microsoft.com/fwlink/?LinkId=619687 |
| Firefox | geckodriver(.exe) | https://GitHub.com/mozilla/geckodriver/releases/ |
| Phantomjs | phantomjs(.exe) | http://phantomjs.org/ |
| Opera | operadriver(.exe) | https://github.com/operasoftware/operachromiumdriver/releases |
| Safari | SafariDriver.safariextz | http://selenium-release.storage.googleapis.com/index.html |
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_# 作者 :liuxiaowei# 创建时间 :2/7/22 6:43 PM# 文件 :获取京东商品信息.py# IDE :PyCharmfrom selenium import webdriver # 导入浏览器驱动模块from selenium.webdriver.support.wait import WebDriverWait # 导入等待类from selenium.webdriver.support import expected_conditions as EC # 等待条件from selenium.webdriver.common.by import By # 节点定位#from selenium.webdriver.chrome.service import Servicetry: # 创建谷歌浏览器驱动参数对象 chrome_options = webdriver.ChromeOptions() # 不加载图片 prefs = {"profile.managed_default_content_settings.images": 2} chrome_options.add_experimental_option("prefs", prefs) # 使用headless无界面浏览器模式 chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') # 加载谷歌浏览器驱动driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 请求地址 driver.get('https://item.jd.com/12353915.html') wait = WebDriverWait(driver,10) # 等待10秒 # 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息 wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w"))) # 获取name节点中所有div节点 name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]') name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]') name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]') summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]') print('提取的商品标题如下:') print(name_div1.text) # 打印商品标题 print('提取的商品宣传语如下:') print(name_div2.text) # 打印宣传语 print('提取的编著信息如下:') print(name_div3.text) # 打印编著信息 print('提取的价格信息如下:') print(summary_price.text.strip('降价通知')) # 打印价格信息 driver.quit() # 退出浏览器驱动except Exception as e: print('显示异常信息!', e)程序运行结果如下:
提取的商品标题如下:
零基础学Python(python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
提取的编著信息如下:
明日科技 著
提取的价格信息如下:
京 东 价
¥ 72.00 [9.03折] [定价 ¥79.80]
selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下表:
selenium 模块获取网页节点的常用方法及描述
| 常用方法 | 描 述 |
|---|---|
| driver.find_element_by_id() | 根据id获取节点,参数为字符类型id对应的值 |
| driver.find_element_by_name() | 根据name获取节点,参数为字符类型name对应的值 |
| driver.find_element_by_xpath() | 根据XPATH获取节点,参数为字符类型XPATH对应的值 |
| driver.find_element_by_link_text() | 根据链接文本获取节点,参数为字符类型链接文本 |
| driver.find_element_by_tag_name() | 根据节点名称获取节点,参数为字符类型节点文本 |
| driver.find_element_by_class_name() | 根据class获取节点,参数为字符类型class对应的值 |
| driver.find_element_by_CSS_selector() | 根据CSS选择器获取节点,参数为字符类型的CSS选择器语法 |
说 明
上表所有获取节点的方法均为获取单个节点的方法,如需要获取符合条件的多个节点时,可以在对应方法中element后面添加s即可。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两种方法时,需要为其指定by与value参数。其中by参数表示获取节点的方式,而value为获取方式对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点 name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div') # 提取并输出单个div节点的内容 print('提取的商品标题如下:') print(name_div[0].text) # 打印商品标题 print('提取的商品宣传语如下:') # 打印商品宣传语 print(name_div[1].text)程序运行结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
明日科技 著
说 明
以上代码中首先使用find_element()方法获取class值为“itemInfo-warp“的整个节点,然后在该节点中通过find_elements()方法获取节点名称div的所有节点,最后通过name_div[0].text,name_div[1].text获取所有div中第一个第二个div内的文本信息。
下面是By的其他属性及用法
| By属性 | 用 法 |
|---|---|
| By.ID | 表示根据ID值获取对应的单个或多个节点 |
| By.LINK_TEXT | 表示根据链接文本获取对应的单个或多个节点 |
| By.PARTIAL_LINK_TEXT | 表示根据部分链接文本获取对应的单个或多个节点 |
| By.NAME | 根据name值获取对应的单个或多个节点 |
| By.TAG_NAME | 根据节点名称获取单个或多个节点 |
| By.CLASS_NAME | 根据class值获取单个或多个节点 |
| By.CSS_SELECTOR | 根据CSS选择器获取单个或多个节点,对应的value为字符串CSS的位置 |
| By.XPATH | 根据By.XPATH获取单个或多个节点,对应的value字符串节点位置 |
在使用selenium模块获取某个节点中的某个属性所对应的值时,可以使用get_attribute()方法来实现,示例代码如下:
# 根据XPath定位获取指定节点中的href地址href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')print('指定节点中的地址信息如下:')程序运行结果如下:
指定节点中的地址信息如下:
https://book.jd.com/writer/%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80_1.html
本案例中需要注意的是加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路径关闭浏览器页面
driver.close():关闭当前页面driver.quit():退出整个浏览器以上是“如何使用selenium+chromedriver+xpath爬取动态加载信息”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注编程网精选频道!
--结束END--
本文标题: 如何使用selenium+chromedriver+xpath爬取动态加载信息
本文链接: https://lsjlt.com/news/322220.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0