Python 官方文档:入门教程 => 点击学习
目录seleniumMac安装chromedriver完整代码Maven依赖完整代码目标:爬取b站用户的动态里面的图片,示例动态 如下所示,我们需要获取这些图片 如图所示,哔哩哔哩
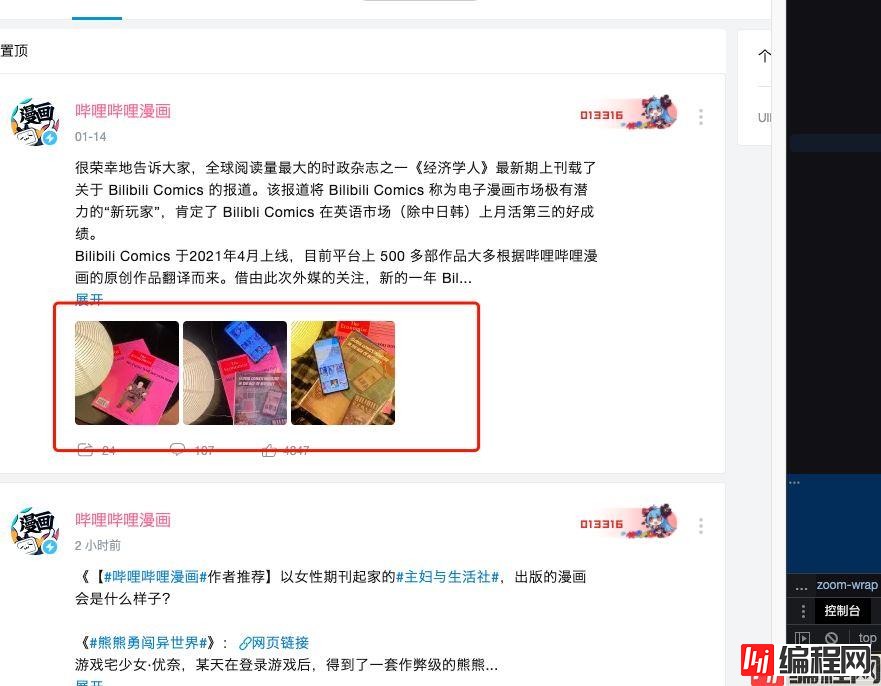
目标:爬取b站用户的动态里面的图片,示例动态
如下所示,我们需要获取这些图片
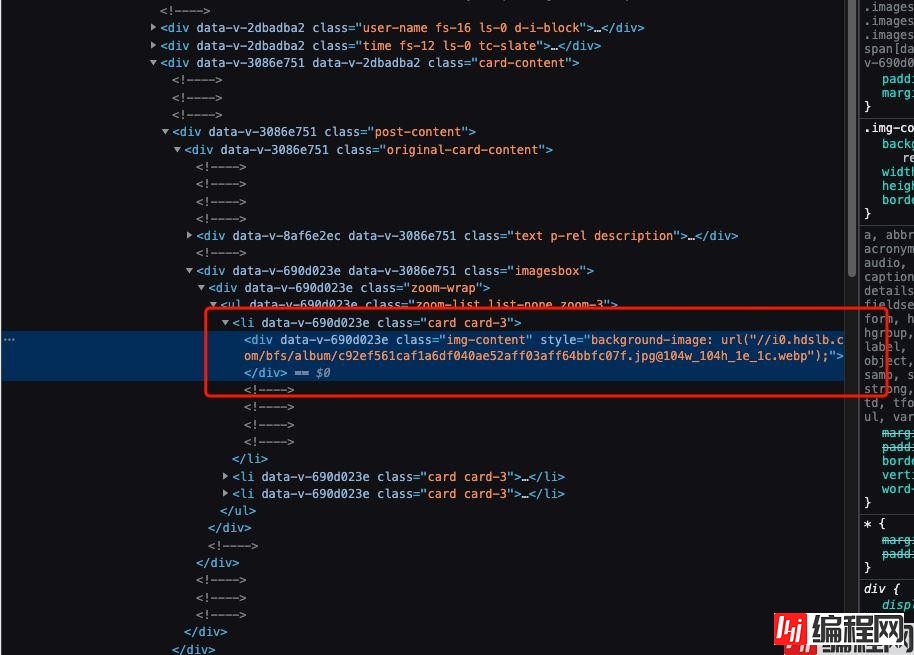
如图所示,哔哩哔哩漫画的数据是动态请求获取的
这里我们使用selenium来爬取数据
Selenium是一个用于WEB应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
官网地址
这里我使用chrome浏览器,所以驱动就选用chromedriver
使用brew安装
brew install chromedriver手动安装
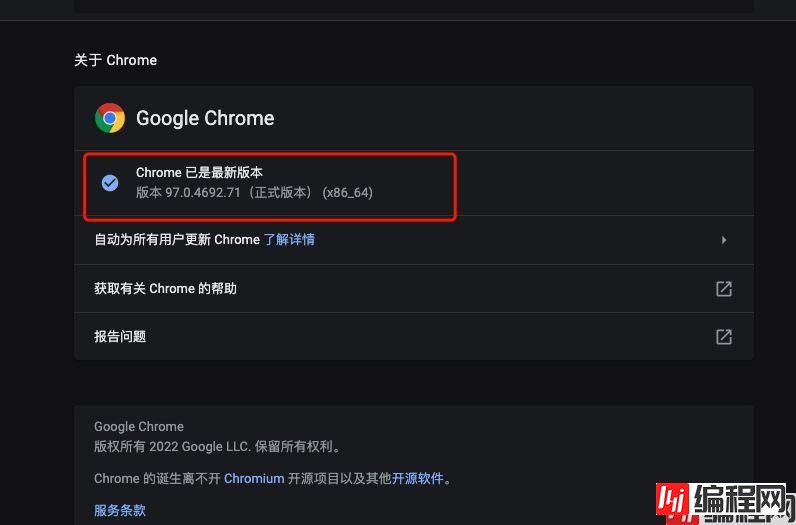
查看电脑上chrome游览器的版本
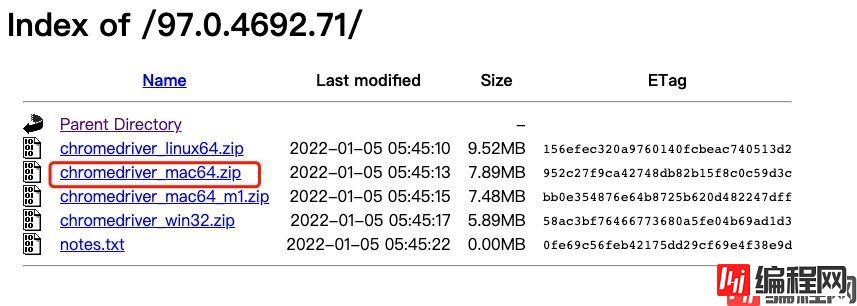
下载对应驱动
chromedriver下载官网
选择对应浏览器版本的驱动下载

解压zip文件,放置到对应文件夹
这里使用SpringBoot框架
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
<dependency>
<groupId>com.GitHub.kevinsawicki</groupId>
<artifactId>Http-request</artifactId>
<version>6.0</version>
</dependency>
selenium用于解析网页
http-request用于下载图片
package com.sun.web_crawler;
import com.github.kevinsawicki.http.HttpRequest;
import org.openqa.selenium.By;
import org.openqa.selenium.javascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.File;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class getPictures3Test {
// https://space.bilibili.com/4099287/dynamic
public static WebDriver getWebDriver(int moudle, String driverPath) {
System.setProperty("webdriver.chrome.driver", driverPath);
HashMap<String, Object> chromePrefs = new HashMap<String, Object>();
chromePrefs.put("profile.managed_default_content_settings.images", 2);
WebDriver driver;
if (moudle == 1)
driver = new ChromeDriver(new ChromeOptions().setHeadless(true).setExperimentalOption("prefs", chromePrefs));
else
driver = new ChromeDriver();
return driver;
}
//将所有链接对应的图片下载到path中,并按照从number开始的顺序编号
public static void downLoad(String path, ArrayList<String> links, int number) throws Exception {
for (String s : links) {
System.out.println("图片:" + s);
HttpRequest hr = HttpRequest.get("https:" + s);
if (hr.ok()) {
File file = new File(path + number + s.substring(s.length() - 4));
hr.receive(file);
number++;
}
}
}
public static void main(String[] args) throws Exception {
//用户uid
String uid = "4099287";
//图片存储位置
String dir = "/Volumes/data/data/b/tako" + File.separator;
//driver位置
String driverPath = "/Volumes/data/env/chromedriver/chromedriver";
//没有图片可以加载时会显示这个
String bottomFlag = "你已经到达了世界的尽头";
//pt2用来匹配一个动态里的图片链接
Pattern pt2 = Pattern.compile("//i0[^@]{50,100}(png|jpg)");
//初始化
WebDriver driver = getWebDriver(1, driverPath);
JavascriptExecutor jse = (JavascriptExecutor) driver;
ArrayList<WebElement> wes = null;
//图片链接links
ArrayList<String> links = new ArrayList<String>();
driver.get("https://space.bilibili.com/" + uid + "/dynamic");
Thread.sleep(3000);
jse.executeScript("window.scrollBy(0," + 4000 + ");");
long time1 = System.currentTimeMillis();
System.out.println("开始爬取页面图片地址!");
int i=1;
int count=0;
while (true) {
System.out.println("向下滚动第"+(i++)+"次!");
//向下滚动
jse.executeScript("window.scrollBy(0," + 800 + 500 * Math.random() + ");");
//如果发现到底了,就退出循环
if (driver.findElement(By.className("div-load-more")).getAttribute("innerhtml").contains(bottomFlag))
break;
wes = (ArrayList<WebElement>) driver.findElements(By.className("original-card-content"));
wes.remove(wes.size() - 1);
//每20个动态获取一次,并删除对应的网页元素(否则会很慢)
if (wes.size() > 20) {
for (WebElement we : wes) {
String innerHtml = we.getAttribute("innerHTML");
Matcher matcher2 = pt2.matcher(innerHtml);
while (matcher2.find()) {
String link = matcher2.group();
if (link.contains("album"))
links.add(link);
System.out.println("记录图片地址数量为:"+ (++count));
}
jse.executeScript("document.getElementsByClassName(\"card\")[0].remove();");
}
}
Thread.sleep(50);
}
Collections.reverse(links);
long time2 = System.currentTimeMillis();
//下载
System.out.println("开始下载图片!");
downLoad(dir, links, 0);
long totalMilliSeconds = time2 - time1;
System.out.println();
long totalSeconds = totalMilliSeconds / 1000;
//求出现在的秒
long currentSecond = totalSeconds % 60;
//求出现在的分
long totalMinutes = totalSeconds / 60;
long currentMinute = totalMinutes % 60;
//求出现在的小时
long totalHour = totalMinutes / 60;
long currentHour = totalHour % 24;
//显示时间
System.out.println("总毫秒为: " + totalMilliSeconds);
System.out.println(currentHour + ":" + currentMinute + ":" + currentSecond + " GMT");
driver.quit();
}
}
开始下载代码时如下:

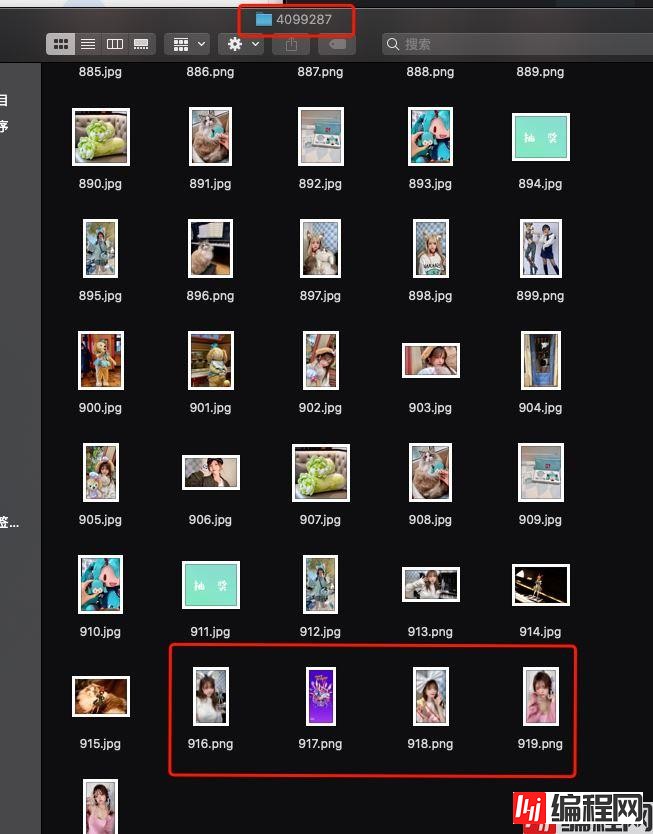
下载完成后:
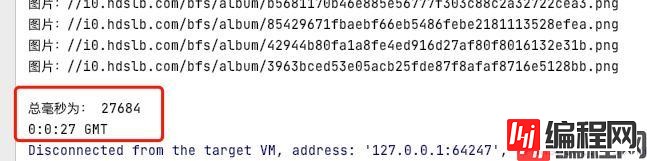
完成后如下:
到此这篇关于Java使用selenium爬取b站动态的实现方式的文章就介绍到这了,更多相关Java selenium爬取b站动态内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Java使用selenium爬取b站动态的实现方式
本文链接: https://lsjlt.com/news/162667.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0