Python 官方文档:入门教程 => 点击学习
本篇文章给大家分享的是有关如何利用python代码批量将pdf文件转为Word格式,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。在日常工作或学习中,经常会遇到这样的无奈:“小任
本篇文章给大家分享的是有关如何利用python代码批量将pdf文件转为Word格式,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
在日常工作或学习中,经常会遇到这样的无奈:
“小任,你把这个PDF中的文件码出来发我”
倒霉,2M的PDF12点也完不了啊!
很多时候在学习时发现许多文档都是PDF格式,PDF格式却不利于学习使用,因此需要将PDF转换为Word文件,但或许你从网上下载了很多软件,但只能转换前五页(如WPS等),要不就是需要收费,那有没有免费的转换软件呢?
so,菜鸟分析给各位带来了一个免费简单快速的方法,手把手教你用Python批量处理PDF格式文件,获取自己想要的内容,存为word形式。
在实现PDF转Word功能之前,我们需要一个python的编写和运行环境,同时安装好相关的依赖包。 对于python环境,我们推荐使用PyCharm。 在本地电脑环境,anaconda提供了非常便利的安装和部署。
PDF转Word功能所需的依赖包如下:
PDFParser(文档分析器),PDFDocument(文档对象),PDFResourceManager(资源管理器),PDFPageInterpreter(解释器),PDFPageAggregator(聚合器),LAParams(参数分析器)
一、前期准备工作
说明:菜鸟分析是在windows7下使用python***的3.6版本
1.安装pdfminer3k模块
安装anaconda后,直接可以通过pip安装
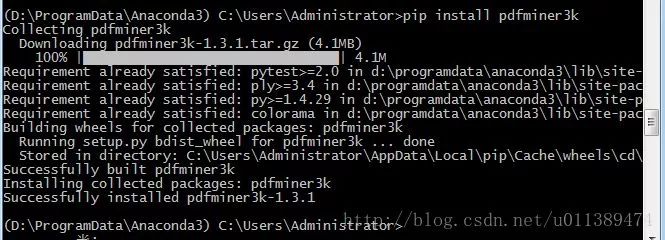
2.若安装不成功,可以试试下面方法
首先下载pdfminer3k:https://pypi.python.org/pypi/pdfminer3k;然后安装pdfminer
将下载好的pdfminer3k解压到D:或其他合适的盘符,通过win+r 打开运行窗口,输入cmd;
输入D:切换到D盘,cd pdfminer3k(pdf解压的文件夹),输入setup.py install安装软件。
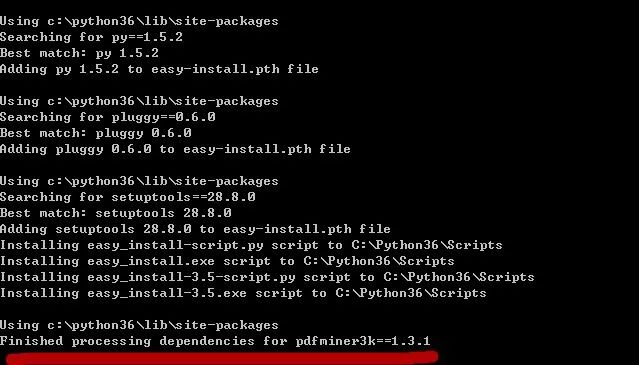
最终显示Finished,则代表成功
二、代码实操
导入相关包
from pdfminer.pdfparser import PDFParser, PDFDocument from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.layout import LAParams from pdfminer.converter import PDFPageAggregator整体思路为:构造文档对象,解析文档对象,提取所需内容
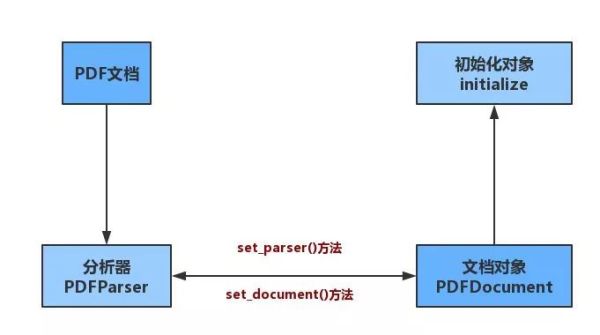
构造文档对象
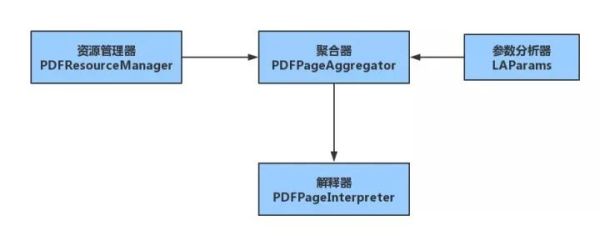
构造解释器
2.导入需要解析的PDF文件
将所需解析的文件与执行代码放到同一个目录下,如图:

test.pdf内容
3.具体代码如下:
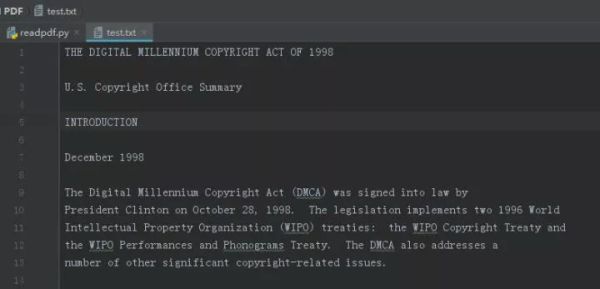
from pdfminer.pdfparser import PDFParser, PDFDocument from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.layout import LAParams from pdfminer.converter import PDFPageAggregator from pdfminer.pdfinterp import PDFTextExtractionNotAllowed def parse(): #rb以二进制读模式打开本地pdf文件 fn = open('test.pdf','rb') #创建一个pdf文档分析器 parser = PDFParser() #创建一个PDF文档 doc = PDFDocument() #连接分析器 与文档对象 parser.set_document() doc.set_parser() # 提供初始化密码doc.initialize("lianxipython") # 如果没有密码 就创建一个空的字符串 doc.initialize("") # 检测文档是否提供txt转换,不提供就忽略 if not doc.is_extractable: raise PDFTextExtractionNotAllowed else: #创建PDf资源管理器 resource = PDFResourceManager() #创建一个PDF参数分析器 laparams = LAParams() #创建聚合器,用于读取文档的对象 device = PDFPageAggregator(resource,laparams=laparams) #创建解释器,对文档编码,解释成Python能够识别的格式 interpreter = PDFPageInterpreter(resource,device) # 循环遍历列表,每次处理一页的内容 # doc.get_pages() 获取page列表 for page in doc.get_pages(): #利用解释器的process_page()方法解析读取单独页数 interpreter.process_page(page) #使用聚合器get_result()方法获取内容 layout = device.get_result() #这里layout是一个LTPage对象,里面存放着这个page解析出的各种对象 for out in layout: #判断是否含有get_text()方法,获取我们想要的文字 if hasattr(out,"get_text"): print(out.get_text()) with open('test.txt','a') as f: f.write(out.get_text()+'\n') if __name__ == '__main__': parse()最终得到的test.txt结果如下:
结束:对于Python批量PDF转Word的操作介绍就到此。
以上就是如何利用Python代码批量将PDF文件转为Word格式,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注编程网Python频道。
--结束END--
本文标题: 如何利用Python代码批量将PDF文件转为Word格式
本文链接: https://lsjlt.com/news/286917.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0