摘要:大数据计算服务(MaxCompute,原名ODPS)是阿里云提供的一种快速、完全托管的EB级数据仓库解决方案。本文章中阿里云MaxCompute公有云技术支持人员刘力夺通过一个实验向大家介绍了阿里云关系型数据库产品RDS中的Mysql
摘要:大数据计算服务(MaxCompute,原名ODPS)是阿里云提供的一种快速、完全托管的EB级数据仓库解决方案。本文章中阿里云MaxCompute公有云技术支持人员刘力夺通过一个实验向大家介绍了阿里云关系型数据库产品RDS中的Mysql数据如何同步到MaxCompute,帮助用户大体了解MaxCompute产品以及其数据同步过程。
直播视频回顾:
mysql/RDS数据如何同步到MaxCompute
以下内容根据演讲视频以及PPT整理而成。
实验方案概述
本实验是对RDS同步数据到MaxCompute的一个初步讲解。当企业需要利用MaxCompute进行数据开发时,如果数据不在MaxCompute而在RDS中,首先需要将RDS中的数据同步到MaxCompute。本实验将以RDS(Mysql)为例,具体讲解此过程的操作步骤以及一些容易遇到的问题,为企业的数据同步过程提供一些指导与帮助。
本次同步过程的方案分为以下两个链路:1)通过DataWorks中的数据集成功能进行同步;2)通过DTS(数据传输服务)进行同步。
方案1需要在DataWorks中新建RDS和MaxCompute的数据源,利用抽象化的数据抽取插件(Reader),数据写入插件(Writer)进行数据传输,达到数据同步的目的;
方案2利用DTS服务确定同步的数据来源及数据去向进行同步。
下图是同步的方案流程图,数据来源是RDS,包括两个数据同步链路,分别是DataWorks和DTS,数据最终要同步到MaxCompute中。

下面分别介绍一下上图方案中涉及到的一系列功能或平台:
•RDS
RDS是阿里云关系型数据库,是一种稳定可靠、可弹性伸缩的在线数据库服务。它基于阿里云分布式文件系统和SSD盘高性能存储,同时支持多种数据库类型,如MySQL、SQL Server、postgresql。

•数据集成
数据集成是DataWorks中的一个功能,是阿里集团对外提供的稳定高效,弹性伸缩的数据同步平台,致力于提供复杂网络环境下、丰富的异构数据源之间数据高速稳定的数据移动及同步能力。

•DTS
DTS是一种数据传输服务,其支持RDBMS、NoSQL、OLAP等数据源间的数据交互。DTS具备极高的链路稳定性和数据可靠性。数据传输支持同/异构数据源之间的数据交互,提供数据迁移/订阅/同步交互功能。

进行实验之前需要进行操作环境的准备:如果使用DataWorks数据集成,需要确保MaxCompute服务已开通,DataWorks项目空间已开通;如果使用DTS,则需要购买DTS服务。
同步操作步骤
下面介绍数据同步到MaxCompute具体的操作步骤:
•DataWorks数据集成
1.以项目管理员身份登陆DataWorks控制台,单击工作空间列表,找到对应的工作空间,单击进入数据集成选项。
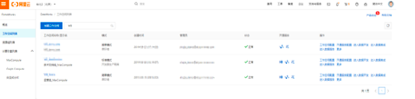
单击任务列表同步资源管理中的数据源选项,在右上方选择新增数据源。
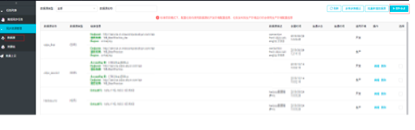
因为做的是RDS同步到MaxCompute,因此需要分别添加两种类型的数据源,首先添加数据来源,选择新增数据库类型为MySQL关系型数据库。
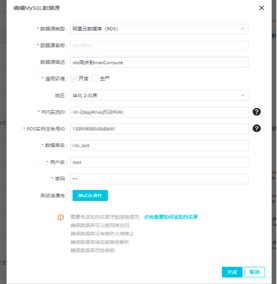
数据源选择完成后需要填写数据源的配置项。数据源类型选择阿里云数据库(RDS),填写对应RDS实例ID,RDS实例主账号ID。填写RDS中对应的MySQL数据库名称及密码。最后测试连通性,显示测试连通性成功证明配置成功。需要注意的一点是,在连接之前还需配置RDS的白名单,确保RDS可以被其他设备访问,后面会详细介绍。
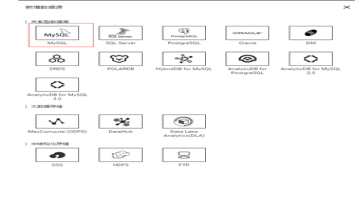
新增MaxCompute类型的数据源。
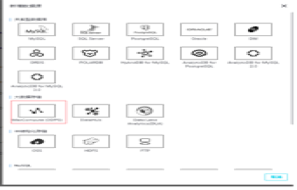
配置MaxCompute类型数据源,填写数据源名称和适用环境(开发和生产),类型Endpoint,对应MaxCompute项目名称,AccessKey ID以及AccessKey Secret。至此,创建数据源已经完成。
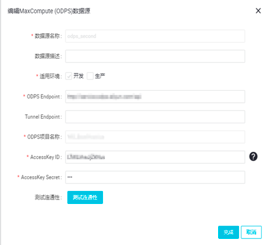
以开发者身份进入DataWorks管理控制台,找到对应项目后点击进入数据开发选项。
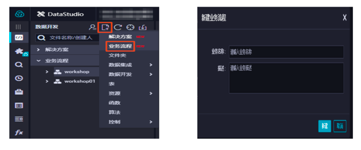
进入DataStudio(数据开发)页面,新建业务流程(下图红色框),填写业务流程名称及描述。
在DataWorks中建立对应RDS中的表,并在业务流程下的数据集成选项中新建数据同步节点并提交。
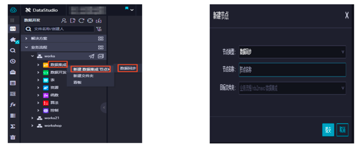
配置数据来源与数据去向,需要配置的数据源是刚才添加的数据源,数据来源是MySQL,它的表是RDS中对应的表,目标数据源是MaxCompute,其他的如清理规则、空字符串是否为null的配置选项,默认选择即可。
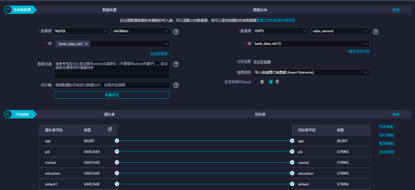
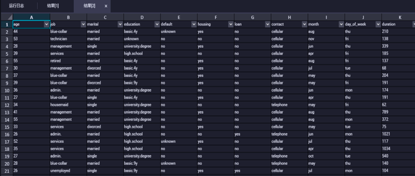
配置完成后可以保存并运行同步数据节点,查询MaxCompute的同步表中是否存在数据,且与RDS的数据一致,判断同步是否成功。
下面介绍如何利用DTS进行数据同步。
•DTS数据同步
1.首先需要登陆数据传输控制台,在左侧导航栏中点击数据同步选项。
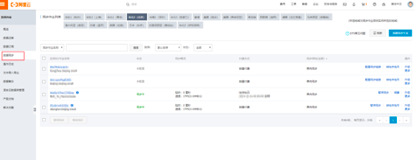
单击完成后在控制台的右上方点击创建同步作业选项,购买DTS服务,前面提到使用DTS需要提前购买服务,指的便是这步操作。需要注意的一点是,所购买的DTS所属的Region尽量要和RDS以及MaxCompute的Region一致,为了避免后续操作中不必要的麻烦。
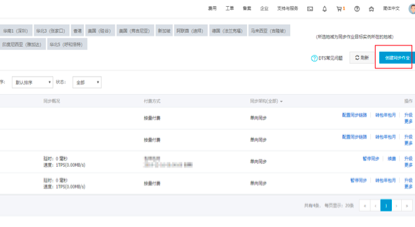

找到购买的DTS实例,单击配置同步链路。需要填写购买的RDS实例ID,RDS中数据库的用户名、密码,需要同步到的MaxCompute项目名称。配置同步链路完成之后单击授权白名单并进入下一步选项,将DTS服务器的IP地址自动添加到RDS实例和MaxCompute实例的白名单中,保障DTS服务器能够正常连接源和目标实例。
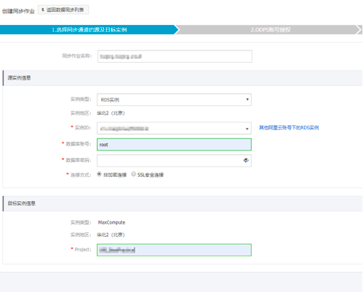
单击下一步,允许将MaxCompute中项目的下述权限授予给DTS同步账号。
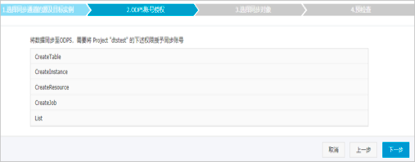
配置同步策略和同步对象,配置完成之后单击预检查并启动。只有预检查通过后才会成功启动数据同步作业。如果预检查失败,可以根据提示详情修复后重新进行预检查。
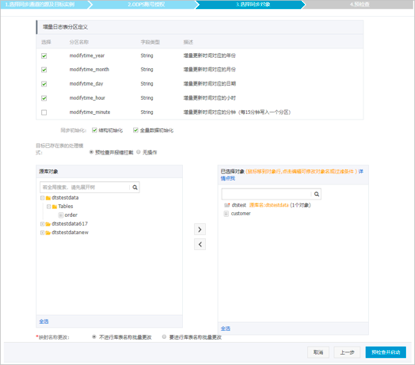
DTS数据同步配置的参数主要有:1)同步通道的源实例及目标实例信息;2)同步策略和同步对象。其中源实例及目标实例信息的配置需要注意的是源实例的名称和同步作业的信息,还有实例类型、地区和ID,同步策略和同步对象的配置需要注意的是增量日志表分区定义、同步初始化、目标已存在的表的处理模式以及选择同步对象。

在预检查对话框显示预检查通过后,关闭预检查对话框后同步作业正式开始。用户可以在数据同步作业页面查看同步的状态。
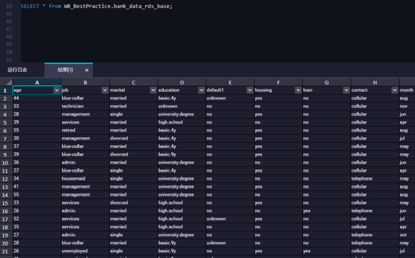
同步完成后,会在MaxCompute的生产环境中生成两张表,一张以_base结尾,存储同步到的数据,另一张以_log结尾,存储增量数据和元信息。用户可以通过查询表数据确定同步过程是否成功。
实验注意事项及易遇到的问题
1.需要配置RDS的白名单,确保RDS可以被访问,否则会同步失败。
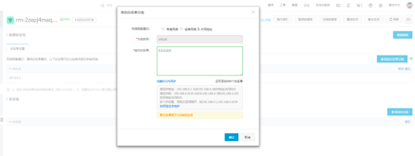
关于配置RDS白名单,需要登陆到RDS控制台,找到对应Region下的RDS实例并进入。单击设置白名单选项,这里以内网地址的设置白名单为例。
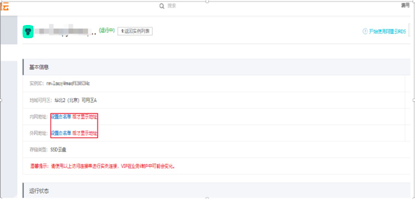
默认IP地址为127.0.0.1,表示不允许任何设备访问该RDS实例,需要修改允许其他设备访问。
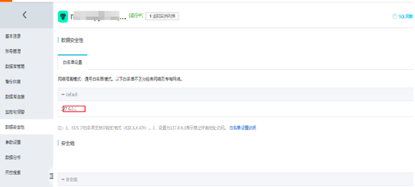
需要修改默认地址,填写需要访问该实例的IP地址或IP段,如10.10.10.0/24,表示10.10.10.x的网段都可以访问该实例。0.0.0.0/0表示任意设备都可以访问该实例,此设置有一定安全风险,请谨慎使用。
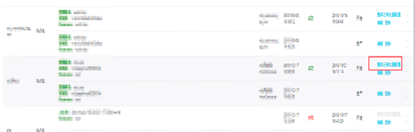
针对DataWorks数据集成的快速批量配置,在公共云上,如果用户想对RDS同步到MaxCompute进行快速批量配置,可以进行整库迁移操作。如下图所示,找到添加到的数据源,单击整库迁移批量配置的选项。
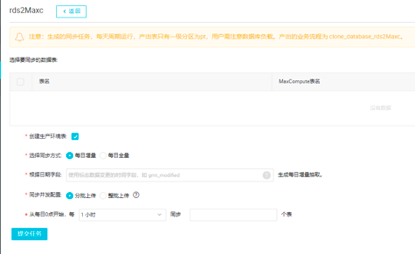
单击整库迁移批量配置的选项后,就可以进入到快速批量配置界面,需要选择要同步的数据表、创建生产环境表、选择同步方式等。下图展示了快速批量配置界面待迁移表筛选区、迁移模式、并发控制区。
此外,还可以进行高级设置,提供表名称,列名称,列类型的映射转换规则
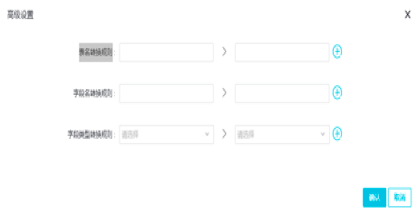
当使用DTS同步时,会在同步的目标表中添加一些附加列。如果附加列和目标表中已有的列名称冲突会导致同步失败,可以通过启用新的附加列规则避免冲突,此配置会在旧版附加列的基础上加上new_dts_sync_的前缀。
阅读原文
本文为云栖社区原创内容,未经允许不得转载。
--结束END--
本文标题: MySQL/RDS数据如何同步到MaxCompute之实践讲解
本文链接: https://lsjlt.com/news/2205.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0