目录一、前言二、再看k8s架构图三、pod特点四、pod分类五、pod中的容器六、Pod中的网络补充:k8s中的网络通信模型七、Pod中的存储八、Pod常用操作命令补充说明:九、Po
在之前k8s组件一篇中,我们谈到了pod这个组件,了解到pod是k8s中资源管理的最小单位,可以说Pod是整个k8s对外提供服务的最基础的个体,有必要对Pod做深入的学习和探究。
为了加深对k8s中pod的理解,再来回顾下k8s的完整架构

结合上面这张图,关于pod,可以总结下面几点:
根据pod是否自主创建,可以分为两种
从上图可以发现,容器是运行在pod中的,也可以简单理解为pod是容器运行的外部容器,所以一个pod理论上可以运行很多个docker容器,关于这一点,做两点说明:
对于k8s集群中的某个节点来说,可能部署了多个pod,这些不同的pod之间如果也需要互相通信怎么办呢?这就需要说到pod中的网络了;
K8S集群的有4种网络:
具体如下:同一pod内的容器间通信、各pod彼此之间的通信、pod与service间的通信、以及集群外部的流量同service之间的通信
1、查看k8s集群中系统运行的pod
kubectl get pod -n kube-system
2、查看创自己创建的pod
kubectl get pod
或
kubectl get pod,svc,deploy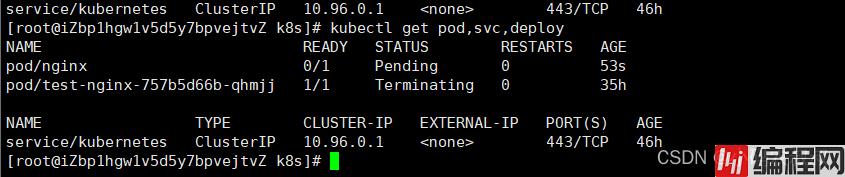
3、删除pod
直接删除pod:
kubectl delete pod pod名称 -n 名称空间
删除通过控制器创建的pod:
kubectl delete pod控制器名称 -n 名称空间
4、启动一个pod【命令方式启动】
kubectl run pod名称 --image=镜像 --port=80 --namespace 命名空间名字
比如在上一篇中,我们创建了一个Nginx的pod,可以写成:
kubectl run test-nignx-pod --image=nginx:1.23.0 --port=80 --namespace test
5、启动一个pod【yaml方式启动】
在当前目录下创建一个yaml的文件
配置内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
labels:
chapter: first-app
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name : nginx
image: nginx:1.23.0
ports:
- containerPort: 80然后使用apply的方式启动
kubectl apply -f ./test-nginx.yaml

注意点:
通过 apply -f 的方式创建的pod,删除的时候,也需要通过apply -f 的方式删除
6、通过deployment控制器导出yaml文件
在当前集群下,我们有下面这个pod

使用下面的命令导出这个pod对应的yaml
kubectl create deployment test-nginx3 --image=nginx:1.23.0 --namespace test -o yaml --dry-run=client > ./nginx.yaml执行之后可以发现在当前目录下创建了一个yaml的文件

文件内容是不是和前面我们自己创建的那个yaml很像,看起来似乎更加完整,需要注意的是,这个里面的有些参数是可以手动修改的,比如:replicas 这个表示生成的nginx的pod个数;
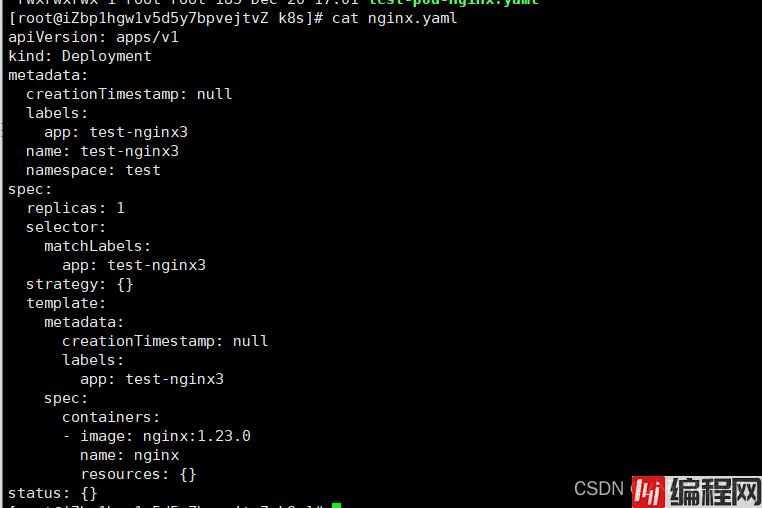
然后就可以使用apply的命令创建pod了
kubectl apply -f nginx.yaml
7、查看某个名称空间下 pod 的详细信息
kubectl get pod -n ns名称 -o wide
比如,查看default名称空间下的pod信息,就能看到上面通过yaml文件创建的pod;
kubectl get pod -n default -o wide

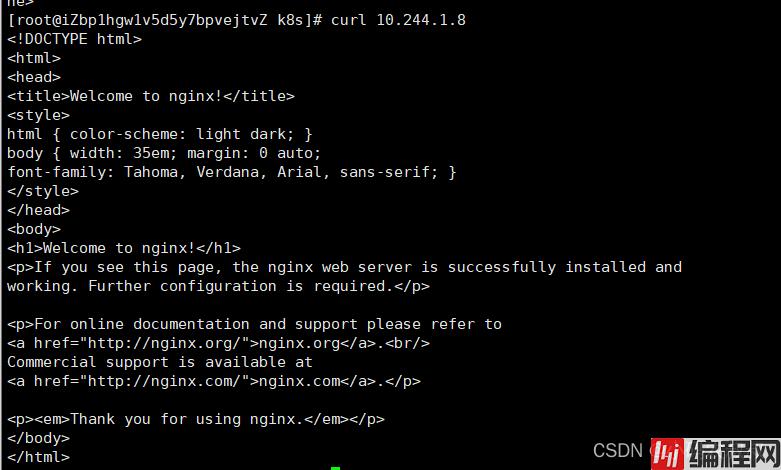
通过k8s创建出来的pod,会分给当前的pod一个IP地址,可以直接通过curl 进行访问【同一个集群下的其他节点都可访问】
1、pod镜像拉取策略
pod镜像拉取策略可以通过imagePullPolicy字段配置镜像拉取策略,如下:
spec:
containers:
- name: nginx
image: nginx:1.23.0
imagePullPolicy: Always #可取 Always(默认值)、IfNotPresent、NeverimagePullPolicy可以使用以下3种策略值:
Always: 默认值,每次创建pod都会重新拉取一次镜像;
IfNotPresent: 镜像在宿主机上不存在时才拉取;
Never: 永远不会主动拉取镜像,使用本地镜像,需要你手动拉取镜像下来;
2、pod使用资源限制配置
我们知道,集群中的节点都是有一定的配置的,比如CPU,内存等信息,总不能因为创建的某个pod把节点的资源给打满了,因此可以在配置文件中进行配置,以使用apply -f 的方式创建一个pod,配置文件中关键配置如下:
resources:
requests:
memory:"内存大小"
cpu:"cpu占用大小"
limits:
memory:"内存占用大小"
cpu:"cpu占用大小"下面是一段完整的标签配置和说明
spec:
containers:
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量如下为一段实际使用中的配置

更多配置,请参考文档:k8s文档
3、关于pod的创建流程
以通过kubectl apply -f xxx.yaml 这种方式创建的pod进行说明,结合本文开头的k8s架构图:
4、Pod调度策略
默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上,那么应该怎么做呢?这就要求了解k8s对Pod的调度规则 。
下面列举几个影响pod调度的因素:
pod资源限制
scheduler根据requests找到足够大小的node进行调度
使用节点选择器标签(nodeSelector)
例如,当前需要把pod调度到开发环境中,则可以通过scheduler将pod调度到标签选择器中为env_role:dev的node中 ,对应的yaml核心配置如下:
nodeSelector:
env_role:dev/prod关于节点选择器,后续还会通过一文详细讲解其使用。
到此这篇关于k8s中pod使用详解(云原生kubernetes)的文章就介绍到这了,更多相关k8s中pod使用内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: k8s中pod使用详解(云原生kubernetes)
本文链接: https://lsjlt.com/news/178040.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0