Python 官方文档:入门教程 => 点击学习
目录一.了解spark、PySparkSpark是什么python on SparkPyspark 小结二.构建PySpark执行环境入口对象PySpark的编程模型小结三

定义:Apache Spark是用于大规模数据(large-Scala data)处理的统一(unified)分析引擎。

简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据
Spark作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。而Python语言,则是Spark重点支持的方向。
Spark对Python语言的支持,重点体现在,Python第三方库: PySpark之上。
PySpark是由Spark官方开发的Python语言第三方库。
python开发者可以使用pip程序快速的安装PySpark并像其它三方库那样直接使用。
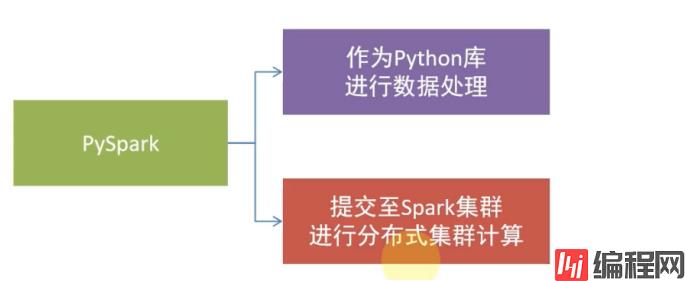
1.什么是Spark、什么是PySpark
2.为什么要学习PySpark?
大数据开发是Python众多就业方向中的明星赛道,薪资高岗位多,Spark ( PySpark)又是大数据开发中的核心技术
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。PySpark的执行环境入口对象是:类SparkContext的类对象

注意:
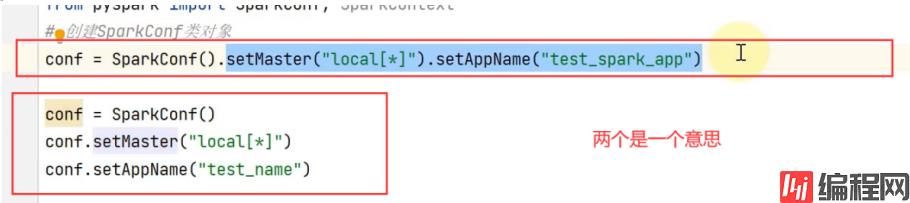
红框里面的两个都是一个意思,上面的方法叫做链式调用
#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#基于SparkConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
#打印Pyspark版本
print(sc.version)
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()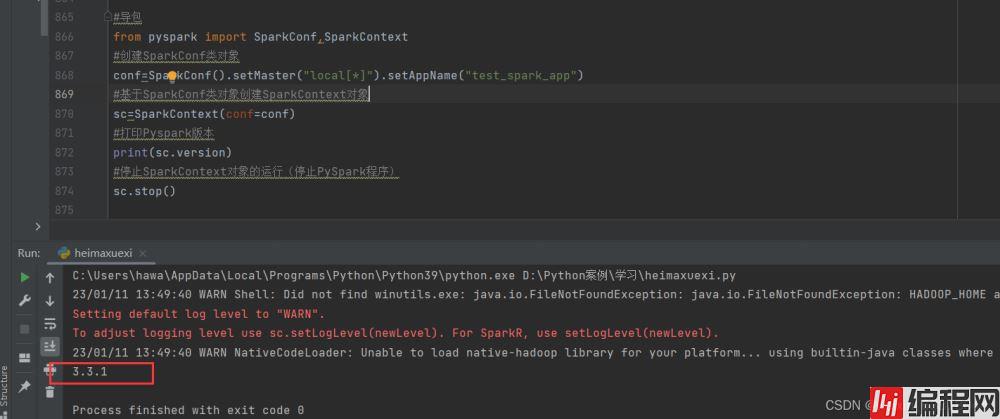
注意:要想运行成功需要下载jdk并配置好环境变量
SparkContext类对象,是PySpark编程中一切功能的入口。PySpark的编程,主要分为如下三大步骤:

1.如何安装PySpark库
pip install pyspark
2.为什么要构建SparkContext对象作为执行入口
PySpark的功能都是从SparkContext对象作为开始
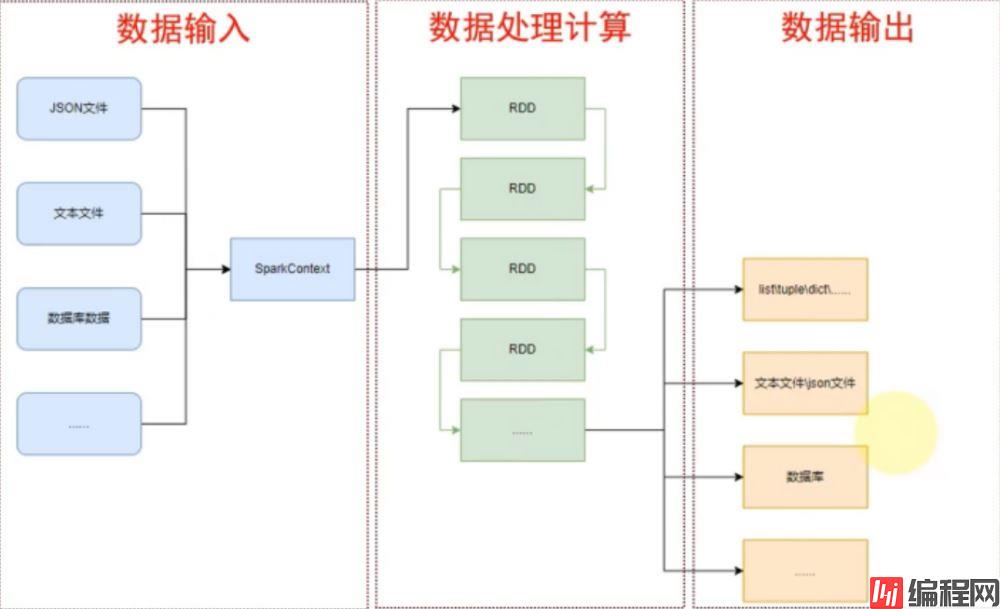
3.PySpark的编程模型是?
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集( Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
PySpark支持通过Sparkcontext对象的parallelize成员方法,将:
转为PySpark的RDD对象
代码:

#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#基于SparkConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
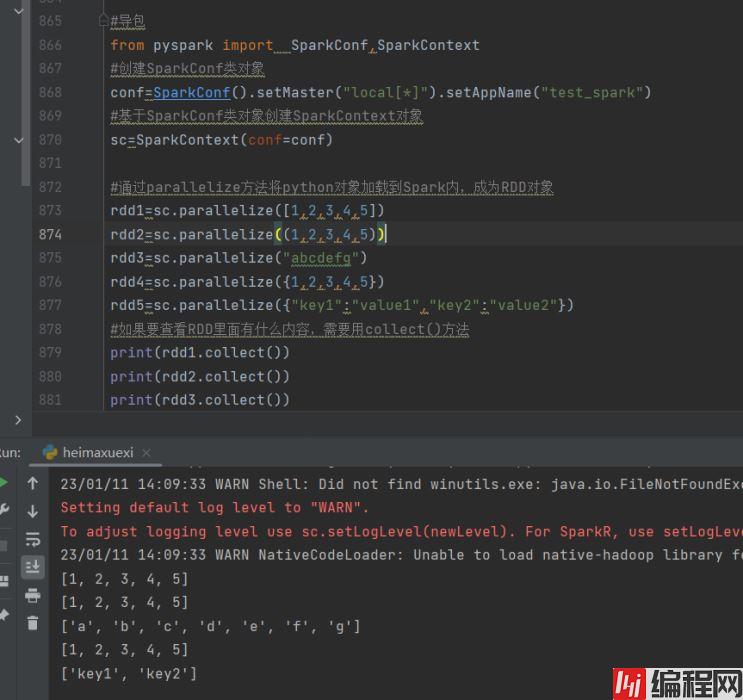
#通过parallelize方法将python对象加载到Spark内,成为RDD对象
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize((1,2,3,4,5))
rdd3=sc.parallelize("abcdefg")
rdd4=sc.parallelize({1,2,3,4,5})
rdd5=sc.parallelize({"key1":"value1","key2":"value2"})
#如果要查看RDD里面有什么内容,需要用collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()结果是
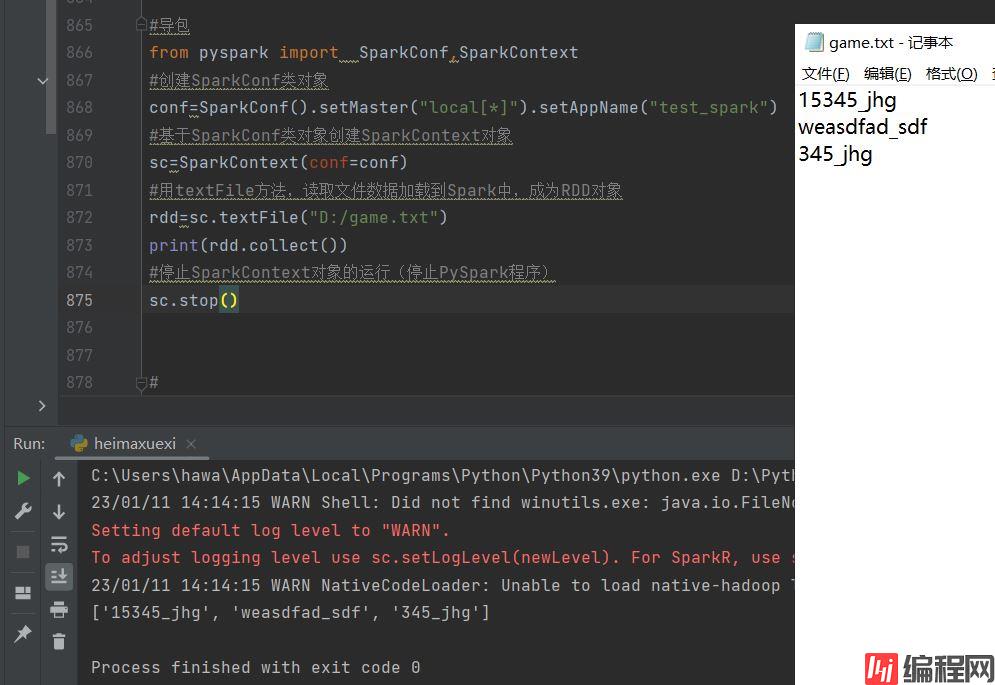
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。

#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#基于SparkConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
#用textFile方法,读取文件数据加载到Spark中,成为RDD对象
rdd=sc.textFile("D:/game.txt")
print(rdd.collect())
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()结果是
到此这篇关于PySpark和RDD对象详解的文章就介绍到这了,更多相关PySpark和RDD对象内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: PySpark和RDD对象最新详解
本文链接: https://lsjlt.com/news/177448.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0