目录一、Flow的基本概念二、Flow的生命周期与异常处理2.1 开始与结束2.2 异常的处理2.3 retry的处理2.4 超时的处理2.5 Flow的取消三、Flow的创建方式四
Kotlin 的 Flow 相信大家都或多或少使用过,毕竟目前比较火,目前我把Flow的使用整理了一下。希望和大家所学对照一下,能有所启发。
Kotlin 的 Flow 用于流式编程,作用于 Kotlin 的协程内。与协程的生命周期绑定,当协程取消的时候,Flow 也会取消。
Flow 的操作符和 RxJava 类似,如果之前会 RxJava 那么可以轻松上手,相比 RxJava ,Flow 更加的简单与场景化。
按照 Flow 的数据流顺序发送的过程,我们对数据流的三个角色交提供方(创建),中介(转换),使用方(接收)。
按照 Flow 流 是否由接收者开始接收触发整个流的启动,我们分为冷流(由接收方启动)与热流(不由接收方启动)。
基本的使用:
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.collect {
println(it)
}
}
打印结果:

基本的使用默认是冷流,从 collect 方法开始发送数据,这里简单的定义一个创建者和一个接收者。
和 RxJava 一样 ,我们同样的可以监听任务流的生命周期,开始,结束,与接收
runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.collect { v ->
YYLogUtils.w(v.toString())
}
}
打印结果:

假如如果我们手动的抛一个异常,看看日志的打印顺序
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
YYLogUtils.e(throwable.message ?: "Unkown Error")
}
lifecycleScope.launch(exceptionHandler) {
flow {
for (i in 1..5) {
delay(100)
emit(i)
if (i == 3) throw RuntimeException("自定义错误")
}
}.onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.collect { v ->
YYLogUtils.w(v.toString())
}
}
看到打印结果:

我们可以在 onCompletion 中打印出错误的对象。但是大家看到我这里使用的协程的上下文来捕获的异常,因为如果不捕获这个异常,程序会崩溃,那可不可以不使用协程的异常捕获?可以,我们可以使用 Flow 的异常捕获。
runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
if (i == 3) throw RuntimeException("自定义错误")
}
}.onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}.collect { v ->
YYLogUtils.w(v.toString())
}
}
可以看到打印的顺序是和上面的一样的,只是换成了Flow来捕获异常了

retry 方法可以让我们程序在错误或异常的时候尝试重新执行创建者的操作。
runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
if (i == 3) throw RuntimeException("自定义错误")
}
}.retry(2).onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}.collect { v ->
YYLogUtils.w(v.toString())
}
}
可以看到打印的结果:
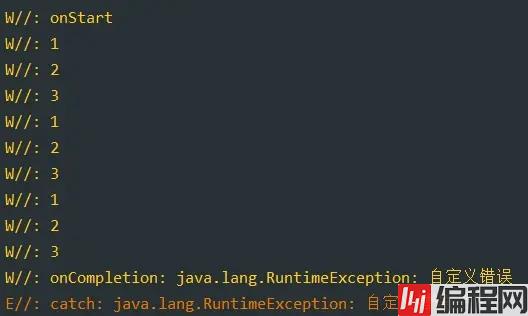
只会走一次开始的回调和结束的回调。
measureTimeMillis { } ,withTimeout(xx) { } 这些都是协程内部的快捷处理方法,处理时间相关。
withTimeout 超时的处理使用的时候协程的快捷函数,其实跟Flow没什么关系,并不是Flow包下面的,所以我们不能使用Flow的异常来处理,因为它是Flow的父亲协程里面的错误,我们可以使用try-catch。也可以使用协程上下文来处理异常。
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
YYLogUtils.e(throwable.message ?: "Unkown Error")
}
lifecycleScope.launch(exceptionHandler) {
withTimeout(200) {
flow {
for (i in 1..5) {
delay(100)
emit(i)
if (i == 3) throw RuntimeException("自定义错误")
}
}.retry(2).onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}.collect { v ->
YYLogUtils.w(v.toString())
}
}
}
打印结果如下:

如果我想计算Flow的耗时,其实就是计算协程内的一个任务的耗时,跟是不是Flow没关系。
lifecycleScope.launch(exceptionHandler) {
val time = measureTimeMillis {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}.collect { v ->
YYLogUtils.w(v.toString())
}
}
YYLogUtils.w("总耗时time:" + time)
}
打印的结果:

同样的 Flow 并没有提供取消的方法,因为Flow是运行在协程中的我们可以依赖协程的运行与取消来实现 Flow 的取消。
我们知道默认的flow是冷流 ,flow.collect 才是触发点,它标记为 suspend 函数,需要执行在协程中。我们就能把Flow的创建和接收分开,并且取消 flow.collect 的作用域协程。
runBlocking {
val flow = flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}
//Flow的取消依赖协程的取消
withTimeoutOrNull(210) {
flow.collect {
YYLogUtils.w("collect:$it")
}
}
}
效果如下:

甚至我们Flow的创建一般都不需要在协程中,比如我还能这么改
val flow = (1..5).asFlow().onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}
runBlocking {
//Flow的取消依赖协程的取消
withTimeoutOrNull(210) {
flow.collect {
YYLogUtils.w("collect:$it")
}
}
}
这里先讲到Flow的基本生命周期与异常处理,Flow的超时,计时,取消等概念,下面我们看看Flow的创建的方式
上面的代码中我们可以看到Flow的创建有几种方式,这里总结一下
flow:创建Flow的操作符。 flowof:构造一组数据的Flow进行发送。 asFlow:将其他数据转换成Flow,一般是其他数据格式向Flow的转换
flow构建器 是经常被使用的流构建器,emit 是 suspend 的需要在协程中执行
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}
flowOf构建器 可以用于定义能够发射固定数量值的流
flowOf(1,2,3,4,5)
asFlow构建器可以将各种集合转为Flow 例如 LongRange IntRange IntArray Array Sequence
(1..10).asFlow()
LiveData同样可以使用 asFlow 扩展方法转换为flow
val liveData = MutableLiveData<Int>(1)
val flow = liveData.asFlow()
.onStart {
YYLogUtils.w("onStart")
}.onCompletion { exception ->
YYLogUtils.w("onCompletion: $exception")
}.catch { exception ->
YYLogUtils.e("catch: $exception")
}
runBlocking {
//Flow的取消依赖协程的取消
withTimeoutOrNull(210) {
flow.collect {
YYLogUtils.w("collect:$it")
}
}
}
![]()
Flow的接收函数操作符常见的有
collect、数据收集操作符,默认的flow是冷流,即当执行collect时,上游才会被触发执行。
其他的终端操作符,大家看名字都知道怎么使用了,我就不一一演示了,这里看看后面2个 reduce 怎么使用的。
runBlocking {
val reduce = flowOf(1, 2, 3).reduce { accumulator, value ->
YYLogUtils.w("accumulator:" + accumulator + " value:" + value)
accumulator + value
}
YYLogUtils.w("reduce:" + reduce)
}
看Log可以看到 accumulator 是已经加过的数值 value是当前数值

那么fold和 reduce类似,只是多了一个初始值
runBlocking {
val fold = flowOf(1, 2, 3).fold(4) { accumulator, value ->
YYLogUtils.w("accumulator: $accumulator value: $value")
accumulator + value
}
println(fold)
YYLogUtils.w("fold:" + fold)
}

比较难理解的就是这2个了。
我们除了Flow创建于接收之外的一些操作符,另外都是一些中间操作符,要说起flow操作符可太多了,这里只说下常用的几个操作符吧
transform transfORM 它会调用 Flow 的 collect() 函数,然后构建一个新的 Flow. 如果想要继续发射值,需要重新调用 emit() 函数。
runBlocking {
flowOf(1, 2, 3).transform {
emit("transformed $it")
}.collect {
println("Collect: $it")
}
}
map实际上就是 transform + emit ,自动封装了
runBlocking {
flowOf(1, 2, 3).map {
"mapped $it"
}.collect {
println("Collect: $it")
}
}
drop 根据条件不要表达式内的数据
runBlocking {
flowOf(1, 2, 3).dropWhile {
it < 2
}.collect {
println("Collect $it")
}
}
打印值为: 2 3
filter 根据条件只要表达式内的数据
runBlocking {
flowOf(1, 2, 3).filter {
it < 2
}.collect {
println("Collect $it")
}
}
打印值为: 1
debounce 防抖动函数,当用户在很短的时间内输入 “d”,“dh”,“dhl”,但是用户可能只对 “dhl” 的搜索结果感兴趣,因此我们必须舍弃 “d”,“dh” 过滤掉不需要的请求,针对于这个情况,我们可以使用 debounce 函数,在指定时间内出现多个字符串,debounce 始终只会发出最后一个字符串
runBlocking {
val result = flow {
emit("h")
emit("i")
emit("d")
delay(90)
emit("dh")
emit("dhl")
}.debounce(200).toList()
println(result)
}
打印值为:dhl
distinctUntilChanged 用来过滤掉重复的请求,只有当前值与最后一个值不同时才将其发出
runBlocking {
val result = flow {
emit("d")
emit("d")
emit("d")
emit("d")
emit("dhl")
emit("dhl")
emit("dhl")
emit("dhl")
}.distinctUntilChanged().toList()
println(result)
}
打印值为:d, dhl
flatMapLatest当有新值发送时,会取消掉之前还未转换完成的值
runBlocking {
flow {
emit("dh")
emit("dhl")
}.flatMapLatest { value ->
flow<String> {
delay(100)
println("collected $value") // 最后输出 collected dhl
}
}.collect()
}
场景如下,正在查询 “dh”,然后用户输入 “dhl”
打印值为:dhl
这里涉及到上下游数据耗时的问题,类似RxJava的背压的概念,比如发出的数据的速度比较快,但是接受的数据的速度比较慢。场景如下
runBlocking {
val time = measureTimeMillis {
flow {
(1..5).forEach {
delay(200)
println("emit: $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
emit(it)
}
}.collect {
delay(500)
println("Collect $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
}
}
println("time: $time")
}
那么就会阻塞掉,5*700 = 3500

可以看到上面的结果是串行等待执行的,那么我们可以通过下面的操作符让代码并发执行优化效率
buffer 该运算符会在执行期间为流创建一个单独的协程。从而实现并发效果。
runBlocking {
val time = measureTimeMillis {
flow {
(1..5).forEach {
delay(200)
println("emit: $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
emit(it)
}
}.buffer().collect {
delay(500)
println("Collect $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
}
}
println("time: $time")
}
可以看到是并发执行的。时间是200 + 5*500 = 2700

conflate 发射数据太快,只处理最新发射的
runBlocking {
val time = measureTimeMillis {
flow {
(1..5).forEach {
delay(200)
println("emit: $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
emit(it)
}
}.conflate().collect {
delay(500)
println("Collect $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
}
}
println("time: $time")
}
注意会丢失数据的,2和4没有接收到
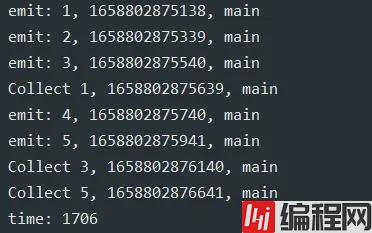
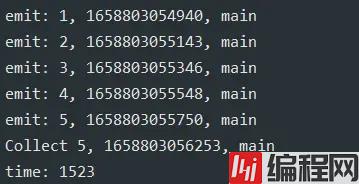
collectLatest 接收处理太慢,只处理最新接收的,但是注意一下这个不是中间操作符,这个是接收操作符,这里作为对比在这里演示
runBlocking {
val time = measureTimeMillis {
flow {
(1..5).forEach {
delay(200)
println("emit: $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
emit(it)
}
}.collectLatest {
// 消费效率较低
delay(500)
println("Collect $it, ${System.currentTimeMillis()}, ${Thread.currentThread().name}")
}
}
println("time: $time")
}
这样就只会接收到最后一个 5
zip 组合两个流,将2个Flow合并为1个Flow
runBlocking {
flowOf("a", "b", "c").zip(flowOf(1, 2, 3)) { a, b ->
a + b //自己定义规则
}.collect {
println(it)
}
}
打印 a1 b2 c3
combine 可以合并多个不同的 Flow 数据流,生成一个新的流。只要其中某个子 Flow 数据流有产生新数据的时候,就会触发 combine 操作,进行重新计算,生成一个新的数据。
val bannerFlow = MutableStateFlow<String?>(null)
val listFlow = MutableStateFlow<String?>(null)
lifecycleScope.launch {
combine(bannerFlow, listFlow) { banner, list ->
val resultList = mutableListOf<String?>()
if (banner != null) {
resultList.add(banner)
}
if (list != null) {
resultList.add(list)
}
return@combine resultList
}.collect { list ->
YYLogUtils.w("list:" + list)
}
withContext(Dispatchers.Default) {
delay(1000)
bannerFlow.emit("Banner")
}
withContext(Dispatchers.Default) {
delay(3000)
listFlow.emit("list")
}
}
可以看到只要其中一个Flow更新了数据都会刷新

对比zip与combine 同样的代码我们对比zip与combine的区别,注意看Log的打印
val bannerFlow = MutableStateFlow<String?>(null)
val listFlow = MutableStateFlow<String?>(null)
lifecycleScope.launch {
bannerFlow.zip(listFlow){ banner, list ->
val resultList = mutableListOf<String?>()
if (banner != null) {
resultList.add(banner)
}
if (list != null) {
resultList.add(list)
}
return@zip resultList
}.collect { list ->
YYLogUtils.w("list:" + list)
}
}
lifecycleScope.launch {
withContext(Dispatchers.Default) {
delay(1000)
bannerFlow.emit("Banner")
}
withContext(Dispatchers.Default) {
delay(3000)
listFlow.emit("list")
}
}
zip只有在都更新了才会触发,这也是最重要的他们的不同点

merge
merge 操作符想说 活都被你们干完了,我还活不活了!??
其实我们可以理解 同一类型我们可以用 merge ,不同的类型我们用zip、combine 。 zip、combine需要我们自定义拼接方式,而 merge 则是需要两者类型一样,直接合并为一个对象。
val bannerFlow = MutableStateFlow<String?>(null)
val listFlow = MutableStateFlow<String?>(null)
lifecycleScope.launch {
listOf(bannerFlow, listFlow).merge().collect {
YYLogUtils.w("value:$it")
}
}
lifecycleScope.launch {
withContext(Dispatchers.Default) {
delay(1000)
bannerFlow.emit("Banner")
}
withContext(Dispatchers.Default) {
delay(3000)
listFlow.emit("list")
}
}
打印结果:

展平操作符 flattenConcat 以顺序方式将给定的流展开为单个流
runBlocking {
flow {
emit(flowOf(1, 2))
emit(flowOf(3,4))
} .flattenConcat().collect { value->
print(value)
}
}
执行结果:1 2 3 4
flattenMerge 作用和 flattenConcat 一样,但是可以设置并发收集流的数量
runBlocking {
flow {
emit(flowOf(1, 2))
emit(flowOf(3,4))
} .flattenMerge(2).collect { value->
print(value)
}
}
执行结果:1 2 3 4
flatMapConcat通过展平操作,用这两个元素各自构建出一个新的流 it + "一年级", it + "二年级", it + "三年级"。
runBlocking {
flowOf("初中", "高中").flatMapConcat {
flowOf(it + "一年级", it + "二年级", it + "三年级")
}.collect {
YYLogUtils.w(it)
}
}

flatMapMerge
runBlocking {
flowOf("初中", "高中").flatMapMerge {
flowOf(it + "一年级", it + "二年级", it + "三年级")
}.collect {
YYLogUtils.w(it)
}
}

实现的效果是一样的,和上面的 flatten 效果类似,后缀为 Concat 是串行,后缀为 Merge 的是并行,效率更高。
Flow的切换线程相比协程的更加简单,至于使用的方式大家可能都不陌生了,这里我简单的举例。
切换线程的操作分一个中间操作符和一个接收操作符,代码如下:
flow {
YYLogUtils.w( "start: ${Thread.currentThread().name}")
repeat(3) {
delay(1000)
this.emit(it)
}
YYLogUtils.w( "end: ${Thread.currentThread().name}")
}
.flowOn(Dispatchers.Main)
.onEach {
YYLogUtils.w( "collect: $it, ${Thread.currentThread().name}")
}
.launchIn(CoroutineScope(Dispatchers.IO))
打印结果如下:

launchIn为接收操作符,指明此Flow运行的协程作用域对象,一般我们可以指定作用域,指定运行线程,例如CoroutineScope(Dispatchers.IO)、 MainScope() 、lifecycleScope等。
flowOn则是切换线程,需要指明协程的上下文对象 ,一般我们用于切换线程。
不知不觉文章又超长了,内容有点太多了,下面总结一下。
总的来说以上应该都是 Flow 使用的基础了,看下来感觉和RxJava还是很像的吧,我们使用 Kotlin 构建项目的过程中,我们真心是不需要 RxJava 了,基本上 Flow 能替代 RxJava 完成我们想要的效果了。毕竟导入一个 RxJava 的库也不小。
Flow 的使用还是很常见的,同时还有它的一些封装类 SharedFlow 与 StateFlow 也比较常用。
以上就是Kotlin Flow操作符及基本使用详解的详细内容,更多关于Kotlin Flow操作符的资料请关注编程网其它相关文章!
--结束END--
本文标题: KotlinFlow操作符及基本使用详解
本文链接: https://lsjlt.com/news/166477.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-01-21
2023-10-28
2023-10-28
2023-10-27
2023-10-27
2023-10-27
2023-10-27
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0