Python 官方文档:入门教程 => 点击学习
目录问题描述:工具:操作:源代码:Reference:总结问题描述: 我有一个这样的数据集叫test_result_test.txt,大概几百上千行,两行数据之间隔一个空行。 N
我有一个这样的数据集叫test_result_test.txt,大概几百上千行,两行数据之间隔一个空行。

N:505904X:0.969wsecY:0.694wsec
N:506038X:4.246wsecY:0.884wsec
N:450997X:8.472wsecY:0.615wsec
...
现在我希望能提取每一行X:和Y:后面的数字,然后保存进excel做进一步的数据处理和分析
就拿第一行来说,我只需要0.969 和0.694。每一行三个数字的具体位置是不确定的,因此不能用固定的列数去处理,刚好发现split函数能对文本进行切片,所以这里我们用这个函数来提取需要的数字信息。
split函数语法如下:
1、split()函数
语法:str.split(str="",num=string.count(str))[n]
参数说明:
str:表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]:表示选取第n个分片
注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略

以“:”进行切片得到
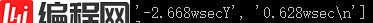
取第三个分片进行“w”切片,得到

这里的第一分片就是我们要的X坐标
最后我们分析一下思路:
首先定位文件位置读取txt文件内容,去掉空行保存Excel准备工作,新建Excel表格,并编辑好标题为写入数据就位对于每一行数据,首先用‘:'进行切片,再用‘w'切片得到想要的数字,然后写入Excel保存
安装好python模块的visual studio 2017
包:os,xlwt
先import我们所需要的包
import os
import xlwt
1.找到我们想要处理的文件,因此去到指定的位置,定位好文件
a = os.getcwd() #获取当前目录
print (a) #打印当前目录
os.chdir('D:/') #定位到新的目录,请根据你自己文件的位置做相应的修改
a = os.getcwd() #获取定位之后的目录
print(a) #打印定位之后的目录
2.打开我们的txt文件查看下里面的内容(这一步可有可无)
#读取目标txt文件里的内容,并且打印出来显示
with open('test_result1.txt','r') as raw:
for line in raw:
print (line)
3.去除空白行并保存
#去掉txt里面的空白行,并保存到新的文件中
with open('test_result1.txt','r',encoding = 'utf-8') as fr, open('output.txt','w',encoding= 'utf-8') as fd:
for text in fr.readlines():
if text.split():
fd.write(text)
print('success')
执行完毕同个位置下多了一个txt文件

4. 创建一个Excel文件
#创建一个workbook对象,相当于创建一个Excel文件
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
'''
Workbook类初始化时有encoding和style_compression参数
encoding:设置字符编码,一般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。默认是ascii。
style_compression:表示是否压缩,不常用。
'''
5.创建一个sheet对象
# 创建一个sheet对象,一个sheet对象对应Excel文件中的一张表格。
sheet = book.add_sheet('Output', cell_overwrite_ok=True)
# 其中的Output是这张表的名字,cell_overwrite_ok,表示是否可以覆盖单元格,其实是Worksheet实例化的一个参数,默认值是False
6.在表格里添加好基本的数据标题,我这里是X和Y坐标
# 向表中添加数据标题
sheet.write(0, 0, 'X') # 其中的'0-行, 0-列'指定表中的单元,'X'是向该单元写入的内容
sheet.write(0, 1, 'Y')
7.多次切割数据并定位好需要的部分保存进Excel
#对文本内容进行多次切片得到想要的部分
n=1
with open('output.txt','r+') as fd:
for text in fd.readlines():
x=text.split(':')[2]
y=text.split(':')[3]
print (x.split('w'))
print (y.split('w'))
sheet.write(n,0,x.split('w')[0])#往表格里写入X坐标
sheet.write(n,1,y.split('w')[0])#往表格里写入Y坐标
n = n+1
# 最后,将以上操作保存到指定的Excel文件中
book.save('Output.xls')
现在定位到之前定义的文件位置,发现又多了一个Excel表格,打开Excel,想要的数据齐齐整整的排好躺在里面,舒服~

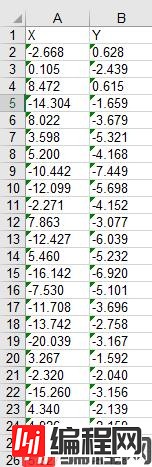
此时数据为文本格式,想要进一步的处理请用Excel转换成数字格式
https://GitHub.com/julis-wolala/TextdataHandler
Https://www.jb51.net/article/230557.htm
到此这篇关于教你用Python提取txt文件中的特定信息并写入Excel的文章就介绍到这了,更多相关python提取txt文件写入Excel内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 教你用python提取txt文件中的特定信息并写入Excel
本文链接: https://lsjlt.com/news/158643.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0