Python 官方文档:入门教程 => 点击学习
目录模式(schema)与其他系统的比较Java客户端实现定义一个schema使用Java代码生成插件生成的User类进行序列化和反序列化在不生成User类的情况下直接进行序列化和反
Apache Avro是一个数据序列化系统。具有如下基本特性:
丰富的数据结构。一种紧凑、快速的二进制数据格式。一个容器文件,用于存储持久数据。远程过程调用 (rpc)。与动态语言的简单集成。 代码生成不需要读取或写入数据文件,也不需要使用或实现 RPC 协议。 代码生成作为一种可选的优化,只值得为静态类型语言实现。
Avro 依赖于模式。读取 Avro 数据时,写入时使用的模式始终存在。 这允许在没有每个值开销的情况下写入每个数据,从而使序列化既快速又小。 这也便于使用动态脚本语言,因为数据及其模式是完全自描述的。
当 Avro 数据存储在文件中时,它的模式也随之存储,以便以后任何程序都可以处理文件。 如果读取数据的程序需要不同的模式,这很容易解决,因为两种模式都存在。
在 RPC 中使用 Avro 时,客户端和服务器在连接握手中交换模式。 (这可以优化,使得对于大多数调用,实际上不传输模式。)由于客户端和服务器都具有对方的完整模式,因此可以轻松解决相同命名字段之间的对应关系,如缺少字段,额外字段等 .
Avro 模式是用 JSON 定义的。 这有助于在已经具有 jsON 库的语言中实现。
Avro 提供类似于 Thrift、Protocol Buffers 等系统的功能。Avro 在以下基本方面与这些系统不同。
动态类型:Avro 不需要生成代码。 数据总是伴随着一个模式,该模式允许在没有代码生成、静态数据类型等的情况下完全处理该数据。这有助于构建通用数据处理系统和语言。未标记数据:由于在读取数据时存在模式,因此需要用数据编码的类型信息要少得多,从而导致更小的序列化大小。没有手动分配的字段 ID:当架构更改时,处理数据时始终存在旧架构和新架构,因此可以使用字段名称象征性地解决差异。
首先在maven项目中添加下述依赖:
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.0</version>
</dependency>
以及下述插件
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.11.0</version>
<executions>
<execution>
<phase>generate-sources</phase>
<Goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
Avro 模式是使用 JSON 定义的。 模式由基本类型(null、boolean、int、long、float、double、bytes 和 string)和复杂类型(record、enum、array、map、uNIOn 和 fixed)组成。 您可以从规范中了解有关 Avro 模式和类型的更多信息,但现在让我们从一个简单的模式示例 user.avsc 开始:
{
"namespace": "com.bigdatatoai.avro.generate",
"type": "record",
"name": "User",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "favorite_number",
"type": [
"int",
"null"
]
},
{
"name": "favorite_color",
"type": [
"string",
"null"
]
}
]
}
此模式定义了代表假设用户的记录。 (请注意,模式文件只能包含单个模式定义。)记录定义至少必须包括其类型(“type”:“record”)、名称(“name”:“User”)和字段, 在本例中为 name、favorite_number 和 favorite_color。 我们还定义了一个命名空间(“namespace”:“com.bigdatatoai.avro.generate”),它与 name 属性一起定义了模式的“全名”(在本例中为 com.bigdatatoai.avro.User)。
字段是通过对象数组定义的,每个对象都定义了一个名称和类型(其他属性是可选的,有关详细信息,请参阅记录规范)。 字段的类型属性是另一个模式对象,它可以是基本类型或复杂类型。 例如,我们的 User 模式的 name 字段是原始类型字符串,而 favorite_number 和 favorite_color 字段都是联合,由 JSON 数组表示。 unions 是一种复杂类型,可以是数组中列出的任何类型; 例如, favorite_number 可以是 int 或 null,本质上使它成为一个可选字段。
已知我们在maven项目中添加了avro插件,那么我们便可以使用compile命令生成User类。
下述以idea为例
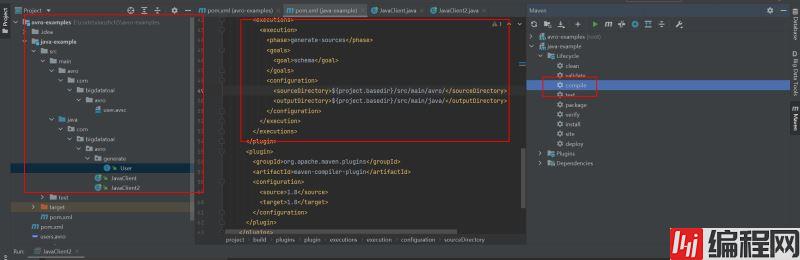
现在我们已经完成了代码生成,让我们创建一些用户,将它们序列化为磁盘上的数据文件,然后读回文件并反序列化用户对象。
创建User用户
// 新建user三种方式
// 方式1
User user1 = new User();
user1.setName("Alyssa");
user1.setFavoriteNumber(256);
// 方式2
User user2 = new User("Ben", 7, "red");
// 方式3
User user3 = User.newBuilder()
.setName("Charlie")
.setFavoriteColor("blue")
.setFavoriteNumber(null)
.build();
如本例所示,可以通过直接调用构造函数或使用构建器来创建 Avro 对象。 与构造函数不同,生成器将自动设置模式中指定的任何默认值。 此外,构建器会按设置验证数据,而直接构造的对象在对象被序列化之前不会导致错误。 但是,直接使用构造函数通常会提供更好的性能,因为构造函数会在写入数据结构之前创建数据结构的副本。
请注意,我们没有设置 user1 最喜欢的颜色。 由于该记录的类型为 [“string”, “null”],我们可以将其设置为字符串或将其保留为 null; 它本质上是可选的。 同样,我们将 user3 最喜欢的数字设置为 null(使用构建器需要设置所有字段,即使它们为 null)。
将上述新建的User用户序列化并保存到磁盘
// 持久化数据到磁盘
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);
dataFileWriter.create(user1.getSchema(), new File("users.avro"));
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
dataFileWriter.close();
从磁盘读取users.avro并反序列化输出
// 从User反序列化数据
DatumReader<User> userDatumReader = new SpecificDatumReader<User>(User.class);
DataFileReader<User> dataFileReader = new DataFileReader<User>(new File("users.avro"), userDatumReader);
User user = null;
while (dataFileReader.hasNext()) {
user = dataFileReader.next(user);
System.out.println(user);
}
Avro 中的数据始终与其对应的模式一起存储,这意味着无论我们是否提前知道模式,我们都可以随时读取序列化项目。 这允许我们在不生成代码的情况下执行序列化和反序列化。
让我们回顾与上一节相同的示例,但不使用代码生成:我们将创建一些用户,将它们序列化为磁盘上的数据文件,然后读回文件并反序列化用户对象。
使用user.avsc文件创建User用户
Schema schema = new Schema.Parser().parse(new File("java-example/src/main/avro/com/bigdatatoai/avro/user.avsc"));
GenericRecord user1 = new GenericData.Record(schema);
user1.put("name", "Alyssa");
user1.put("favorite_number", 256);
GenericRecord user2 = new GenericData.Record(schema);
user2.put("name", "Ben");
user2.put("favorite_number", 7);
user2.put("favorite_color", "red");
由于我们不使用代码生成,我们使用 GenericRecords 来表示用户。 GenericRecord 使用模式来验证我们是否只指定了有效字段。 如果我们尝试设置一个不存在的字段(例如,user1.put(“favorite_animal”, “cat”)),我们将在运行程序时收到 AvroRuntimeException。
请注意,我们没有设置 user1 最喜欢的颜色。 由于该记录的类型为 [“string”, “null”],我们可以将其设置为字符串或将其保留为 null; 它本质上是可选的。
将上述新建的User持久化到磁盘
File file = new File("users2.avro");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, file);
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.close();
从磁盘读取users.avro并反序列化输出
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(file, datumReader);
GenericRecord user = null;
while (dataFileReader.hasNext()) {
user = dataFileReader.next(user);
System.out.println(user);
}
到此这篇关于基于Java实现Avro文件读写功能的文章就介绍到这了,更多相关Java Avro读写功能内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 基于Java实现Avro文件读写功能
本文链接: https://lsjlt.com/news/139613.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0