Python 官方文档:入门教程 => 点击学习
目录步骤1:添加自定义的类步骤2:修改使用的loss函数自定义loss的方法有很多,但是在博主查资料的时候发现有挺多写法会有问题,靠谱一点的方法是把loss作为一个PyTorch的模
自定义loss的方法有很多,但是在博主查资料的时候发现有挺多写法会有问题,靠谱一点的方法是把loss作为一个PyTorch的模块,
比如:
class CustomLoss(nn.Module): # 注意继承 nn.Module
def __init__(self):
super(CustomLoss, self).__init__()
def forward(self, x, y):
# .....这里写x与y的处理逻辑,即loss的计算方法
return loss # 注意最后只能返回Tensor值,且带梯度,即 loss.requires_grad == True示例代码:
以一个pytorch求解线性回归的代码为例:
import torch
import torch.nn as nn
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def get_x_y():
np.random.seed(0)
x = np.random.randint(0, 50, 300)
y_values = 2 * x + 21
x = np.array(x, dtype=np.float32)
y = np.array(y_values, dtype=np.float32)
x = x.reshape(-1, 1)
y = y.reshape(-1, 1)
return x, y
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim) # 输入的个数,输出的个数
def forward(self, x):
out = self.linear(x)
return out
if __name__ == '__main__':
input_dim = 1
output_dim = 1
x_train, y_train = get_x_y()
model = LinearRegressionModel(input_dim, output_dim)
epochs = 1000 # 迭代次数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
model_loss = nn.MSELoss() # 使用MSE作为loss
# 开始训练模型
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs: torch.Tensor = model(inputs)
# 计算损失
loss = model_loss(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.fORMat(epoch, loss.item()))我们就用自定义的写法来写与MSE相同的效果,MSE计算公式如下:
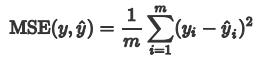
添加一个类:
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
self.mse_loss = nn.MSELoss()
def forward(self, x, y):
mse_loss = torch.mean(torch.pow((x - y), 2)) # x与y相减后平方,求均值即为MSE
return mse_loss只需要把原始代码中的:
model_loss = nn.MSELoss() # 使用MSE作为loss改为:
model_loss = CustomLoss() # 自定义loss即可
完整代码:
import torch
import torch.nn as nn
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def get_x_y():
np.random.seed(0)
x = np.random.randint(0, 50, 300)
y_values = 2 * x + 21
x = np.array(x, dtype=np.float32)
y = np.array(y_values, dtype=np.float32)
x = x.reshape(-1, 1)
y = y.reshape(-1, 1)
return x, y
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim) # 输入的个数,输出的个数
def forward(self, x):
out = self.linear(x)
return out
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
self.mse_loss = nn.MSELoss()
def forward(self, x, y):
mse_loss = torch.mean(torch.pow((x - y), 2))
return mse_loss
if __name__ == '__main__':
input_dim = 1
output_dim = 1
x_train, y_train = get_x_y()
model = LinearRegressionModel(input_dim, output_dim)
epochs = 1000 # 迭代次数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# model_loss = nn.MSELoss() # 使用MSE作为loss
model_loss = CustomLoss() # 自定义loss
# 开始训练模型
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs: torch.Tensor = model(inputs)
# 计算损失
loss = model_loss(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
到此这篇关于pytorch自定义loss损失函数的文章就介绍到这了,更多相关pytorch loss损失函数内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: pytorch自定义loss损失函数
本文链接: https://lsjlt.com/news/138854.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0