Python 官方文档:入门教程 => 点击学习
前言: 我们想要在爬虫中使用xpath、beautifulsoup、正则表达式,CSS选择器等来提取想要的数据,但是因为scrapy是一个比较重的框架,每次运行都要等到一段时间,因此
前言:
我们想要在爬虫中使用xpath、beautifulsoup、正则表达式,CSS选择器等来提取想要的数据,但是因为scrapy是一个比较重的框架,每次运行都要等到一段时间,因此要去验证我们提取规则是否正确,是一个比较麻烦的事情,因此,scrapy提供了一个shell。用来方便的测试规则,当然也不仅仅局限于这一个功能。
打开Scrapy shell:
进入命令行终端,进入到scrapy项目所在的目录,然后进入到scrapy框架所在的虚拟环境中,输入命令 scrapy shell [链接] ,就会进入到scrapy的shell环境中。在这个环境中,你可以跟在爬虫的parse方法中一样使用了。
进入到scrapy项目所在的目录:
进入到scrapy框架所在的虚拟环境中:
source /Volumes/development/Python_learn/PycharmProjects/venv/crawler_evn/bin/activate输入命令 scrapy shell [链接] :

输入我们需要测试的语句:
srcs = response.xpath('//div[contains(@class,"uibox-con")]/ul/li/a/img/@src').getall()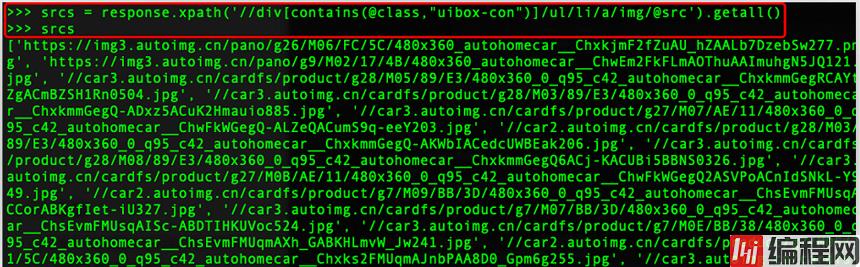
到此这篇关于Python入门之Scrapy shell的使用的文章就介绍到这了,更多相关Scrapy shell的使用内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python中Scrapy shell的使用
本文链接: https://lsjlt.com/news/138357.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0