Python 官方文档:入门教程 => 点击学习
目录一、下载器中间件(Downloader Middleware)process_request(request, spider)process_response(request,
scrapy 结构概述:

如上图标号4、5处所示,下载器中间件用于处理scrapy的request和response的钩子框架,如在request中设置代理ip,header等,检测response的Http响应码等。
scrapy已经自带来一堆下载器中间件。
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
上面就是默认启用的下载器中间件,其各个中间件的作用参考一下官方文档:Scrapy download-middleware
自定义下载器中间件
有时我们需要编写自己的一些下载器中间件,如使用代理池,随机更换user-agent等,要使用自定义的下载器中间件,就需要在setting文件中激活我们自己的实现类,如下:
DOWNLOADERMIDDLEWARES = {
'myproject.middlewares.Custom_A_DownloaderMiddleware': 543,
'myproject.middlewares.Custom_B_DownloaderMiddleware': 643,
'myproject.middlewares.Custom_B_DownloaderMiddleware': None,
}
设置值是个DICT,key是我们自定义的类路径,后面数字是执行顺序,数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可。
(PS. 如果两个下载器的没有强制的前后关系,数字大小没什么影响)
实现下载器我们需要重写以下几个方法:
process_request:可以选择返回None、Response、Request、raise IgnoreRequest其中之一。
通常返回None较常见,它会继续执行爬虫下去
当下载器完成HTTP请求,传递响应给引擎的时候调用,它会返回 Response 、Request 、IgnoreRequest三种对象的一种
当下载处理器(download handler)或process_request()抛出异常(包括 IgnoreRequest 异常)时, Scrapy调用 process_exception() ,通常返回None,它会一直处理异常
这个类方法通常是访问settings和signals的入口函数
例如下面2个例子是更换user-agent和代理ip的下载中间件
# setting中设置
USER_AGENT_LIST = [ \
"Mozilla/5.0 (windows NT 6.1; WOW64) AppleWEBKit/537.1 (Khtml, like Gecko) Chrome/22.0.1207.1 Safari/537.1", \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.132 Safari/537.36", \
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"
]
PROXIES = [
'1.85.220.195:8118',
'60.255.186.169:8888',
'118.187.58.34:53281',
'116.224.191.141:8118',
'120.27.5.62:9090',
'119.132.250.156:53281',
'139.129.166.68:3128'
]
代理ip中间件
import random
class Proxy_Middleware():
def __init__(self, crawler):
self.proxy_list = crawler.settings.PROXY_LIST
self.ua_list = crawler.settings.USER_AGENT_LIST
@claSSMethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
try:
ua = random.choice(self.ua_list)
request.headers.setdefault('User-Agent', ua)
proxy_ip_port = random.choice(self.proxy_list)
request.meta['proxy'] = 'http://' + proxy_ip_port
except request.exceptions.RequestException:
spider.logger.error('some error happended!')
重试中间件
有时使用代理会被远程拒绝或超时等错误,这时我们需要换代理ip重试,重写scrapy.downloadermiddlewares.retry.RetryMiddleware
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy.utils.response import response_status_message
class My_RetryMiddleware(RetryMiddleware):
def __init__(self, crawler):
self.proxy_list = crawler.settings.PROXY_LIST
self.ua_list = crawler.settings.USER_AGENT_LIST
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_response(self, request, response, spider):
if request.meta.get('dont_retry', False):
return response
if response.status in self.retry_http_codes:
reason = response_status_message(response.status)
try:
ua = random.choice(self.ua_list)
request.headers.setdefault('User-Agent', ua)
proxy_ip_port = random.choice(self.proxy_list)
request.meta['proxy'] = 'http://' + proxy_ip_port
except request.exceptions.RequestException:
spider.logger.error('获取讯代理ip失败!')
return self._retry(request, reason, spider) or response
return response
# scrapy中对接selenium
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *
class ChromeDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
if CHROME_PATH:
options.binary_location = CHROME_PATH
if CHROME_DRIVER_PATH: # 初始化Chrome驱动
self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH)
else:
self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
try:
print('Chrome driver begin...')
self.driver.get(request.url) # 获取网页链接内容
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8',
status=200) # 返回HTML数据
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
如文章第一张图所示,spider中间件用于处理response及spider生成的item和Request
启动自定义spider中间件必须先开启settings中的设置
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
同理,数字越小越靠近引擎,process_spider_input()优先处理,数字越大越靠近spider,process_spider_output()优先处理,关闭用None
编写自定义spider中间件
process_spider_input(response, spider)
当response通过spider中间件时,这个方法被调用,返回None
process_spider_output(response, result, spider)
当spider处理response后返回result时,这个方法被调用,必须返回Request或Item对象的可迭代对象,一般返回result
process_spider_exception(response, exception, spider)
当spider中间件抛出异常时,这个方法被调用,返回None或可迭代对象的Request、dict、Item
补充一张图:
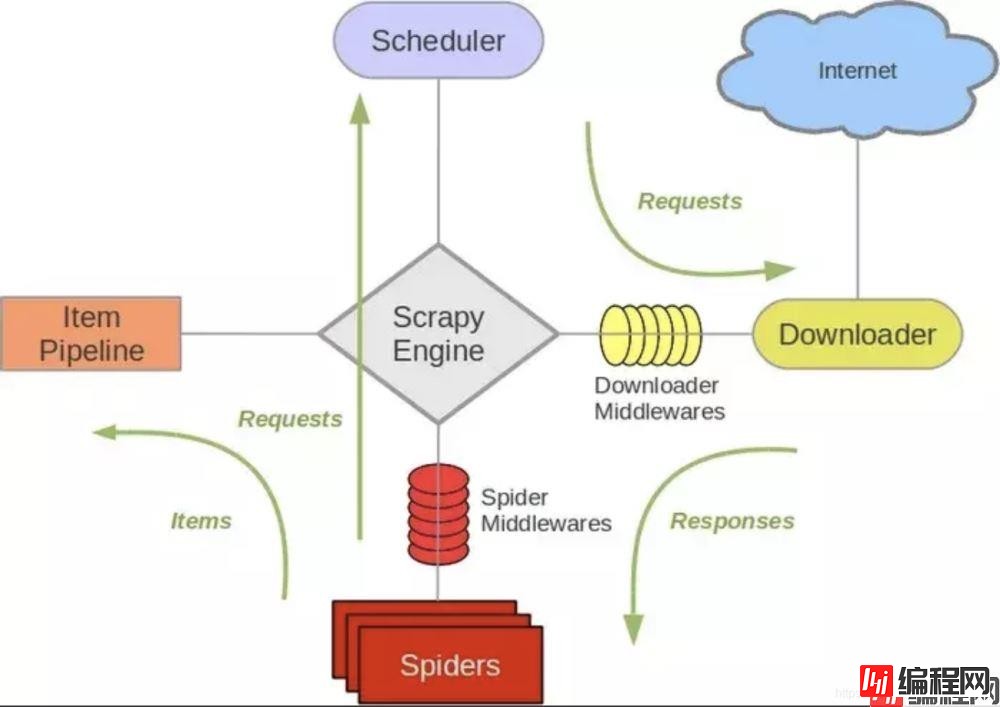
参考文档:
https://docs.scrapy.org/en/latest/topics/spider-middleware.html
https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
到此这篇关于Scrapy 之中间件(Middleware)的文章就介绍到这了,更多相关Scrapy 之中间件(Middleware)内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Scrapy 之中间件(Middleware)的具体使用
本文链接: https://lsjlt.com/news/118679.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0