Python 官方文档:入门教程 => 点击学习
目录快速入门技术的本质——底层结构结构构成为什么要用链表哈希算法手写HashMapHashMap底层的实现什么情况下用红黑树?快速入门 存储:put 方法 put(key,v
存储:put 方法 put(key,value)
查询 : get 方法 get(key)
java 代码如下
import java.util.HashMap;
import java.util.Map;
public class App {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("刘一","刘一");
map.put("陈二","陈二");
map.put("张三","张三");
map.put("李四","李四");
map.put("王五","王五");
map.put("Money","我是猴哥Money老师");
System.out.println(map.get("Money"));
}
}
//输出结果:我是猴哥Money老师
程序是等于我们的数据结构和算法
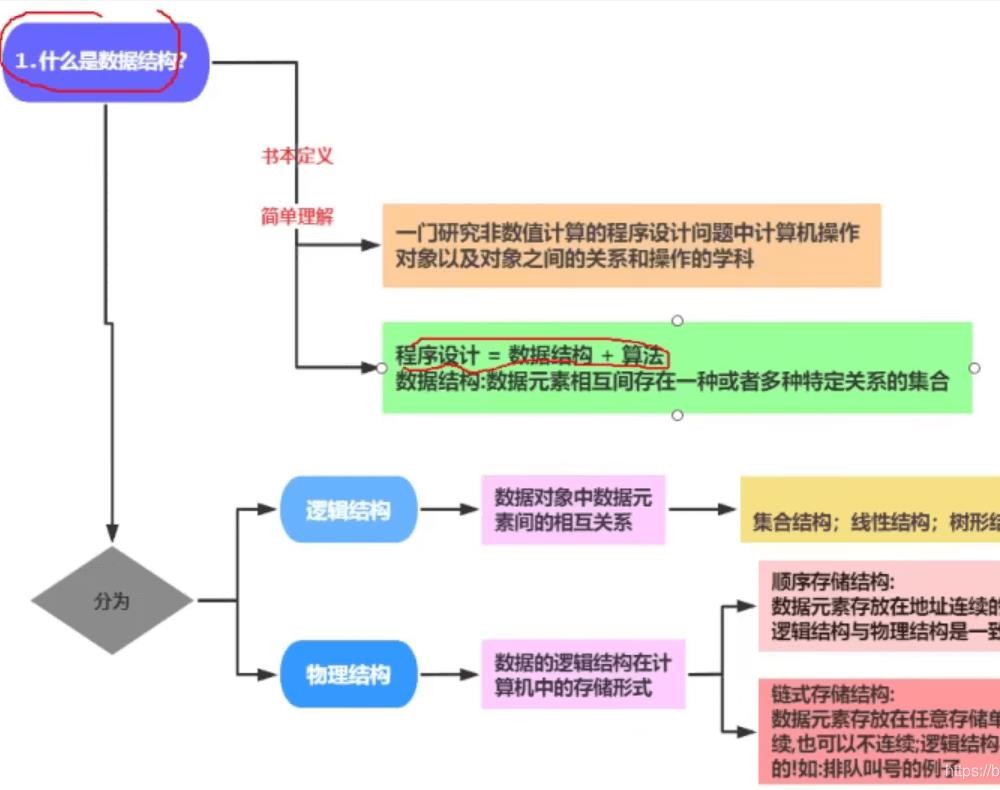
HashMap 其实就是做存储的,做存储的就是数据结构
存储是按上面的规则存储的,那查询是怎么查的了
既然要了解HashMap 的组成,就谈谈它的结构组成
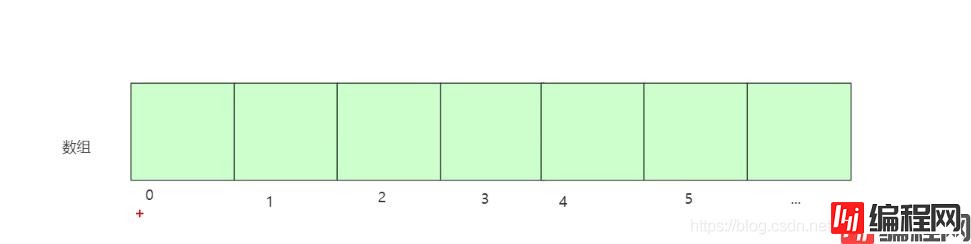
首先我们来说下数组,数组在java 中是怎么定义的了
//数组:采用一段连续的存储单元来存储数据的
//数组的特点: 查询时间复杂度:0(1) ,删除,插入,时间负责度0(N),总结:查询块,插入慢
public static void main(String [] args){
//数组的定义:初始化长度为10,数据类型Integer ,
Integer integer[] = new Integer[10];
//指定下标,复制
integer[0]=0;
//指定下标,复制
integer[1]=1;
//指定下标,复制
integer[9]=2;
//指定下标,复制
integer[9]=400;
System.out.println(integer[9]);
}
// 输出结果:400
数组结构如图:
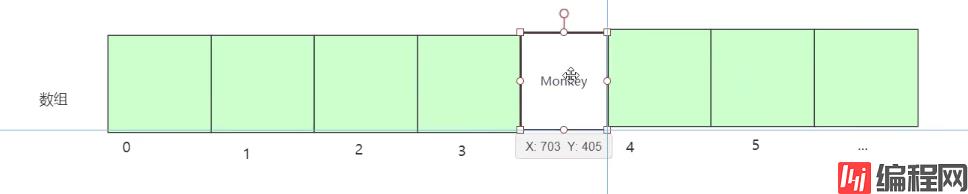
查询: 时间复杂度 0(1),查询非常快的
删除,插入 :时间复杂度0(N) 非常慢的,效率没有查询那么快
为什么查询快,插入,删除慢了?
查询快

插入,删除慢
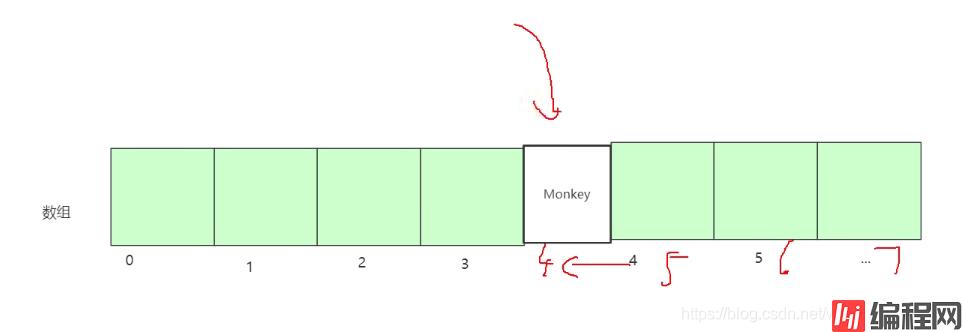
类似,我们后面的下标都要向左移动,这样我后面的数据是不是要做很大的改动,这样时间复杂度则为0(N),这样就保证了我们数组的连续性,同理删除的话如图:
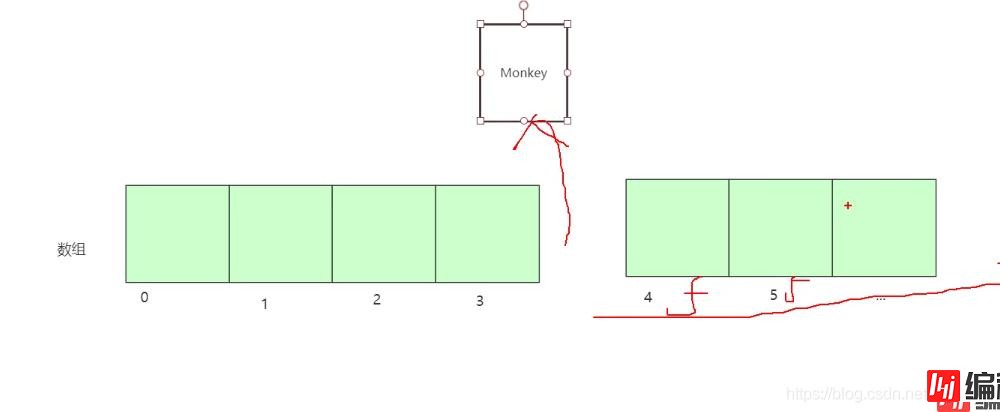
数组后面数据的下标,都要还原成之前插入前的下标,后面的节点都要改变,这样我们可以看出,这就是数组,删除,插入 为什么这么慢!
除非是插入,删除,数组的最后一个元素,大家懂了吗?还不懂那就私聊!
扩充:
大家知道我们java 哪一个类,底层用的就是数组?
在我们的java.util 包下面有一个ArrayList 类,如图

怎么验证了?
我们查看它的add 方法
public boolean add(E var1) {
this.ensureCapacityInternal(this.size + 1);
this.elementData[this.size++] = var1;
return true;
}
如果面试被问到ArrayList 的特性,直接回答 查询快,插入,删除慢
为什么HashMap 用到数组存储了,还要用到链表了?
谈谈什么是链表?
在java 中是这么定义的:
package node;
import com.sun.org.apache.bcel.internal.generic.IMPDEP1;
public class Node {
public Node next;
private Object data;
public Node(Object next) {
this.data = next;
}
//链表:链表是一种物理存储单元上非连续,非顺序的存储结构
//特点: 插入,删除时间复杂度0(1) 查找遍历时间复杂度0(N) 总结:插入快,查询慢
public static void main(String[] args){
Node head =new Node("monkey");
head.next =new Node("张三");
head.next.next =new Node("刘一");
System.out.println(head.data);
System.out.println(head.next.data);
System.out.println(head.next.next.data);
}
}
//输出结果:
//monkey
//张三
//刘一
链表:链表是一种物理存储单元上非连续,非顺序的存储结构,如图:
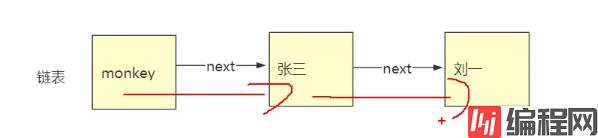
为什么它插入,删除快,查询慢了?
删除 某个节点,只需要上一个节点 head.next =null
插入 某个几点,只需要上一个节点 head.next 指向插入的节点,插入的节点指向下一个节点
查询某个节点:链表查询都要通过头节点,比如我们要查‘刘一',我们则要先查头monkey,再查张三,再查到刘一,
虽然只有3个节点,但是我们要查到刘一要查三次,把整个链表都遍历了一次,所以查询慢!
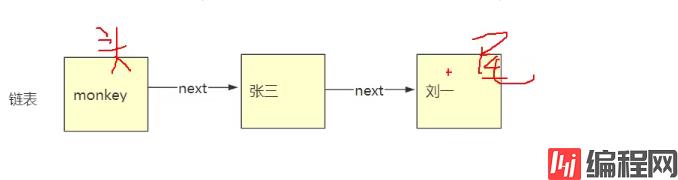
扩充
在我们java 中,哪一个util 类采用的链表来实现的?
我们来查看它的add 方法
public boolean add(E var1) {
this.linkLast(var1);
return true;
}
//看上面有一个linkLast,如下:
void linkLast(E var1) {
LinkedList.Node var2 = this.last;
LinkedList.Node var3 = new LinkedList.Node(var2, var1, (LinkedList.Node)null);
this.last = var3;
if (var2 == null) {
this.first = var3;
} else {
var2.next = var3;
}
++this.size;
++this.modCount;
}
//看上面有一个Node,如下:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> var1, E var2, LinkedList.Node<E> var3) {
this.item = var2;
this.next = var3;
this.prev = var1;
}
}
//上面有一个next,有一个prev
//这是一个双向链表
双向链表如图: 类似与分页,上一页,下一页,下面的对象也可以获取上面对象的数据(head.prev)

现在大家都已经了解JDK7 HashMap 数据结构了,开始了解下算法!
那么HashMap 是怎么去存储的了?他是如何将数据放到我们的数组和链表上的?
用的就是哈希算法,你们知道哈希算法的底层是怎么实现的?
哈希表
什么是哈希算法?
哈希算法(也叫散列),就是把任意长度值(key)通过散列算法变换成固定长度的key(地址), 通过这个地址进行访问的数据结构,
它通过把关键码值映射到表中一个位置来访问记录,以加快查找速度。
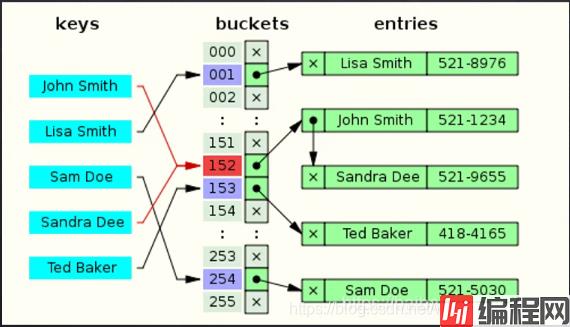
例如图中的John Smith 通过散列算法变换成固定长度的key:152 (永远是152),然后通过152 变成John Smith 是不可能的,哈希算法是不可逆的。
HashCode: 通过字符串算出它的ascii 码,进行mod(取模),算出哈希表中的下标
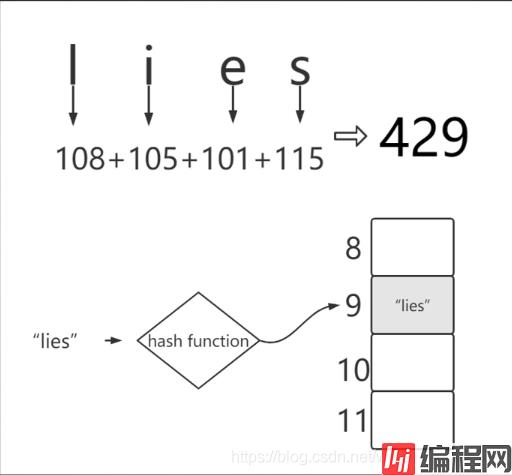
代码如下:
public class AsciiCode {
public static void main(String[] args) {
char c [] ="lies".toCharArray();
for (int i = 0; i < c.length; i++) {
System.out.println((c[i])+":" +(int)c[i]);
}
}
}
//输出结果:
//l:108
//i:105
//e:101
//s:115
将 lies 算出来的ascii 码相加然后除以10 取模(为什么取模不直接存储 429了 )
为什么取模不直接存储 429了?
//数组是采用一段连续的存储单元来存储数据的,那存lies 数据将如图:
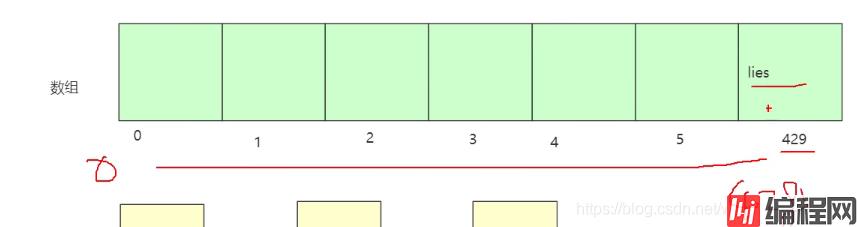
如果你要存lies 则需要300 个这样的内存空间,所以我们取模为10,算出来的值为 9,则节省了很多空间,我们取模的目的就是节省内存空间!
如果我们取模会出现什么问题
会出现hash 冲突(碰撞)的一个问题,
什么是hash冲突
lies 的值通过ascii 码计算的总和为 429foes 的值通过ascii 码计算的总和也为 429
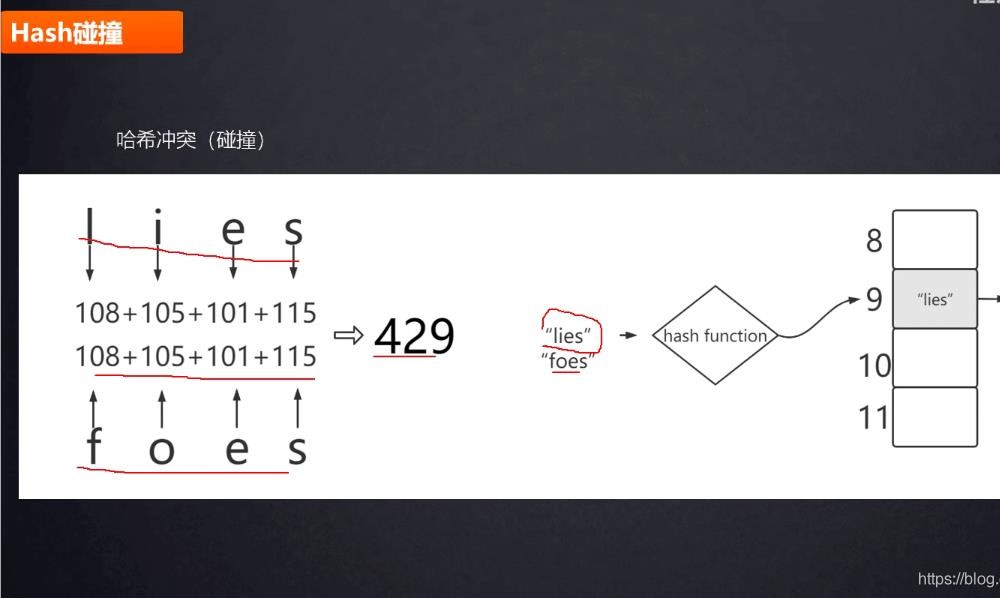
两个单词取模后的值都是 9 ,则lies 会存在下标为9 的这个位置,foes 也存在下标为9 的这个位置,而数组存在同一个下标下面是会覆盖的(上面代码讲数组的时候Intergers[9]=400,会覆盖Intergers[9]=2 的值,最终Intergers[9] =400),同样我们先存的是lies 后存的是foes,则lies
将会被覆盖,lies 和foes 是不同的key, 我们HashMap 是可以存这两个值的,为什么没有被覆盖了?这个地方就叫做哈希碰撞!
Hash冲突怎么解决了
我们用链表来解决这个问题, 链表是有一个指针的,我们可以让这个lies 指向这个foes,我们让foes 去匹配下标为9 的这个节点,如果匹配lies 不相等,则去匹配下一个节点foes,最终就会找到这个foes,这就是我们hash 算法底层的原理及解决冲突。
不调用JDK7 的HashMap,自己手动写一个HashMap
public class App {
public static void main(String[] args) {
//Map<String,String> map = new HashMap<>();
App map = new App();
map.put("刘一","刘一");
map.put("陈二","陈二");
map.put("张三","张三");
map.put("李四","李四");
map.put("王五","王五");
map.put("Money","我是猴哥Money老师");
//System.out.println(map.get("Money"));
}
public void put(String key,String value){
System.out.printf("key:%s:::::::::::::::;::hash值:%s:::::::::::::::::::存储位置:%s\r\n",key,key.hashCode(),Math.abs(key.hashCode() % 15));
}
}
//输出结果:
// key:刘一:::::::::::::::;::hash值:671464:::::::::::::::::::存储位置:4
// key:陈二:::::::::::::::;::hash值:1212740:::::::::::::::::::存储位置:5
// key:张三:::::::::::::::;::hash值:774889:::::::::::::::::::存储位置:4
// key:李四:::::::::::::::;::hash值:842061:::::::::::::::::::存储位置:6
// key:王五:::::::::::::::;::hash值:937065:::::::::::::::::::存储位置:0
// key:Monkey:::::::::::::::;::hash值:-1984628749:::::::::::::::::::存储位置:4
模拟我们是怎么存值的
我们一组数据就是 key,value , 可以用string,int 来存吗?这里显然不能,我们一般存这种值一般用对象来存值,我在这里随便命名用个Object或者叫Entry 对象,其实我们还要存另外两个值?(hash和next),当发生hash 冲突的时候(存储位置4) next 可以指向下一个节点,hash 值是用来比较的,比较hashCode 值是否相等!

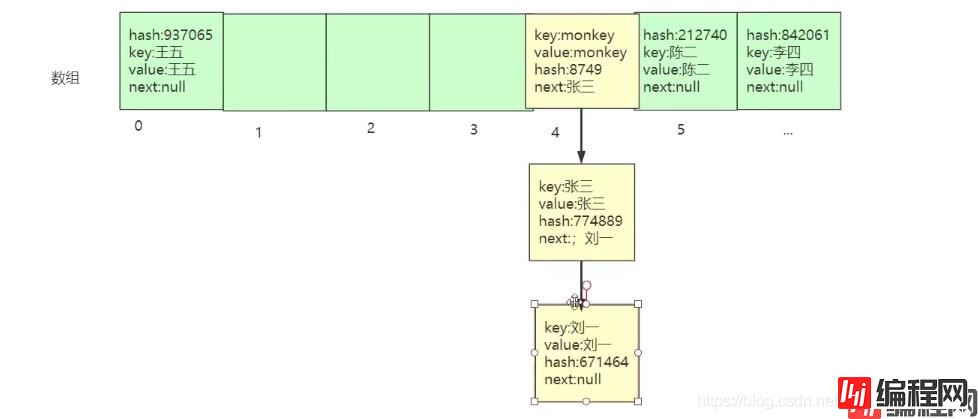
上面的图形结构,我们就知道如何存数据了!
那我们该如何取数据了?
-假如我们要取‘刘一' 的值
我们通过get(key) 方法获取数据的模,然后根据key,与hashCode 的值去比较下标为4 的key 和hashCode,查看是否相等,如果不相等我们通过next 方法比较下一个节点的数据,直到 key 与hashCode 对比的值都相等,此时,获取value的值就是当前key 所对应的value!
HashMap 底层如何实现的了?我们用写源码的方式验证
模拟java HashMap
定义一个Map 接口
public interface Map<K,V> {
V put(K k,V v);
V get(K k);
int size();
interface Entry<K,V>{
K geTKEy();
V getValue();
}
}
定义一个实现Map 的HashMap
import sun.management.snmp.JVMmib.JvmRTInputArgsTableMeta;
public class HashMap<K,V> implements Map<K,V>{
//存储元素对象
private Entry<K,V> table[] = null;
//扩容初始化
int size =0;
//初始化存储元素对象大小
public HashMap() {
this.table = new Entry[16];
}
@Override
public V put(K k, V v) {
int index = hash(k);
Entry<K,V> entry = table[index];
if(null ==entry){
//刘一,陈二,李四,王五 就开始存在这个entry,每个entry 对象则存储到了对应table 中
table[index] = new Entry<>(k, v, index, null);
size++;
}else{
//冲突了,张三,Monkey
table[index] = new Entry<>(k, v, index, entry);
}
return table[index].getValue();
}
private int hash(K k) {
//HashMap 底层用到的是移位的操作,性能高很多 >>,我们这里就直接取模
int index =k.hashCode() % 16;
//Math.abs(index);
return index>0?index:-index;
}
@Override
public V get(K k) {
//如果没有存储数据那size 为0,也不用查了,直接返回null
if(size ==0){
return null;
}
int index = hash(k);
Entry<K, V> entry = findValue(table[index], k);
//通过index 找打这个对象
return entry==null?null:entry.getValue();
}
private Entry<K,V> findValue(Entry<K,V> entry,K k) {
//存的可能是数值类型,也可能是字符串类型
if (k.equals(entry.getKey()) || k == entry.getKey()) {
return entry;
//如果不相等,估计这个节点是个链表,判断它next 数据是否匹配
} else {
if(entry.next !=null){
//用到递归,在链表里面一直查询这个k,值是否相等
return findValue(entry.next,k);
}
}
return null;
}
@Override
public int size() {
return size++;
}
class Entry<K,V> implements Map.Entry<K,V>{
//存四个值
K k;
V v;
int hash;
Entry<K,V> next;
public Entry(K k, V v, int hash, Entry<K, V> next) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}
定义一个测试类
public class Test {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("Monkey","我是moneky老师");
map.put("东山再起","东山再起是位好同学");
System.out.println(map.get("Monkey"));
System.out.println(map.get("东山再起"));
}
//输出结果:
//我是moneky老师
//东山再起是位好同学
}
查看到测试结果,我们就能看到HashMap ,是怎么存储的,和获取值的!
但是JDK8 用的是红黑树,为什么了?
举个代码的例子
import com.sun.xml.internal.ws.api.model.wsdl.WSDLOutput;
public class Test {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
for (int i = 0; i < 1000; i++) {
map.put("Monkey"+i,"我是moneky老师"+i);
}
System.out.println(map);
}
}
可以看到这个map 的size 只有16,却存了很多的数据:
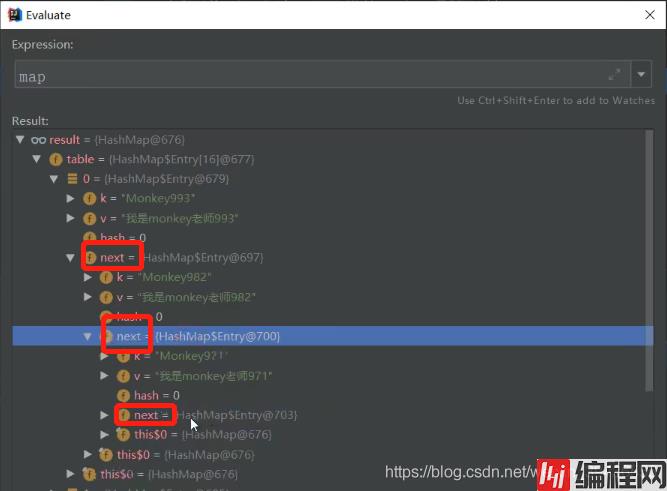
容量不够,我们就只能把这个数据放到链表上,链表无线延长,这种hash冲突是十分严重的,而链表的特性是查询慢,而链表又无线延长,我们查询链表末端的数据,这样性能就很低了,所以JDK8 就用红黑树了!
总结:解决链表过长查询效率过低的问题
前提条件
阈值 8
HashMap 类下面有个这个:
static final int TREEIFY_THRESHOLD = 8;
为什么要阈值 是8 了?
因为红黑叔插入慢,他要判断小中大(也就是左边的小于右边的),而链表插入快,删除快,但是为什么是 8 不是 6了?
具体原因请参考这篇Java红黑树的数据结构与算法解析
到此这篇关于HashMap底层原理全面详解面试绝对不慌的文章就介绍到这了,更多相关HashMap底层原理内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: HashMap底层原理全面详解面试绝对不慌
本文链接: https://lsjlt.com/news/134052.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0