Python 官方文档:入门教程 => 点击学习
目录准备1.求众数1.1对全表进行操作1.1.1求取每列的众数1.1.2 求取每行的众数1.2 对单独的一行或者一列进行操作1.2.1 求取单独某一列的众数1.2.2 求取单独某一行
本文用到的表格内容如下:
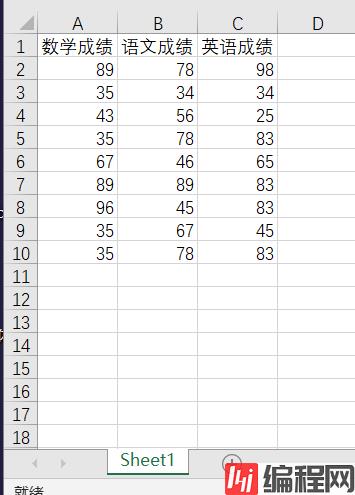
先来看一下原始情形:
result:
数学成绩 语文成绩 英语成绩
0 89 78 98
1 35 34 34
2 43 56 25
3 35 78 83
4 67 46 65
5 89 89 83
6 96 45 83
7 35 67 45
8 35 78 83
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.var())
result:
数学成绩 语文成绩 英语成绩
0 35 78 83
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.mode(axis=1))
result:
0 1 2
0 78.0 89.0 98.0
1 34.0 NaN NaN
2 25.0 43.0 56.0
3 35.0 78.0 83.0
4 46.0 65.0 67.0
5 89.0 NaN NaN
6 45.0 83.0 96.0
7 35.0 45.0 67.0
8 35.0 78.0 83.0
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.mode(axis=1))
result:
0 35
dtype: int64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.iloc[[0]].mode())
result:
数学成绩 语文成绩 英语成绩
0 89 78 98
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df[['数学成绩', "语文成绩"]].mode())
result:
数学成绩 语文成绩
0 35 78
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.iloc[[0, 1]].mode())
result:
数学成绩 语文成绩 英语成绩
0 35 34 34
1 89 78 98
分位数是比中位数更加详细的基于位置的指标,分位数主要有四分之一分位数,二分之一分位数(就是中位数)、四分之三分位数
import pandas as pd
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.quantile(0.25))
result:
数学成绩 35.0
语文成绩 46.0
英语成绩 45.0
Name: 0.25, dtype: float64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.quantile(0.75))
result:
数学成绩 89.0
语文成绩 78.0
英语成绩 83.0
Name: 0.75, dtype: float64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.quantile(0.25))
result:
数学成绩 35.0
语文成绩 46.0
英语成绩 45.0
Name: 0.25, dtype: float64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.quantile(0.25, axis=1))
result:
0 83.5
1 34.0
2 34.0
3 56.5
4 55.5
5 86.0
6 64.0
7 40.0
8 56.5
Name: 0.25, dtype: float64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df['数学成绩'].quantile(0.25))
result:
35.0
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.iloc[[0]].quantile(0.25))
result:
数学成绩 89.0
语文成绩 78.0
英语成绩 98.0
Name: 0.25, dtype: float64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df[['数学成绩', "语文成绩"]].quantile(0.25))
result:
数学成绩 35.0
语文成绩 46.0
Name: 0.25, dtype: float64
df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx')
print(df.iloc[[0, 1]].quantile(0.25))
result:
数学成绩 48.5
语文成绩 45.0
英语成绩 50.0
Name: 0.25, dtype: float64
pandas 和 numpy中都有计算分位数的方法,pandas中是quantile,numpy中是percentile
两个方法其实没什么区别,用法上稍微不同,quantile的优点是与pandas中的groupby结合使用,可以分组之后取每个组的某分位数
quantile代码:
import pandas as pd
import numpy as np
data = pd.read_csv('order_rank_p_0409.txt',sep='\t')
#将data按id_1 和 id_2 分组
grouped=data.groupby(['id_1','id_2'])
#用quantile计算第40%的分位数
grouped['gmv'].quantile(0.4)
#用to_csv生成文件
x.to_csv('order_ran_re.txt',sep= '\t')
percentile代码:
import pandas as pd
import numpy as np
data = pd.read_csv('order_rank_p_0409.txt',sep='\t')
a = array(data['gmv'])
np.percentile(a,0.4)
两段代码,两种方法计算的结果是一样的
到此这篇关于python pandas系列之众数和分位数的文章就介绍到这了,更多相关pandas众数和分位数内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python pandas入门系列之众数和分位数
本文链接: https://lsjlt.com/news/131864.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0