Python 官方文档:入门教程 => 点击学习
目录前言整理透视 pivot 聚合透视 Pivot Table 聚合透视高级操作交叉表crosstab()数据融合melt()数据堆叠 stack前言 panda
pandas对数据框也可以像excel一样进行数据透视表整合之类的操作。主要是针对分类数据进行操作,还可以计算数值型数据,去满足复杂的分类数据整理的逻辑。
首先还是导入包:
import numpy as np
import pandas as pd首先介绍的是最简单的整理透视函数pivot,其原理如图:
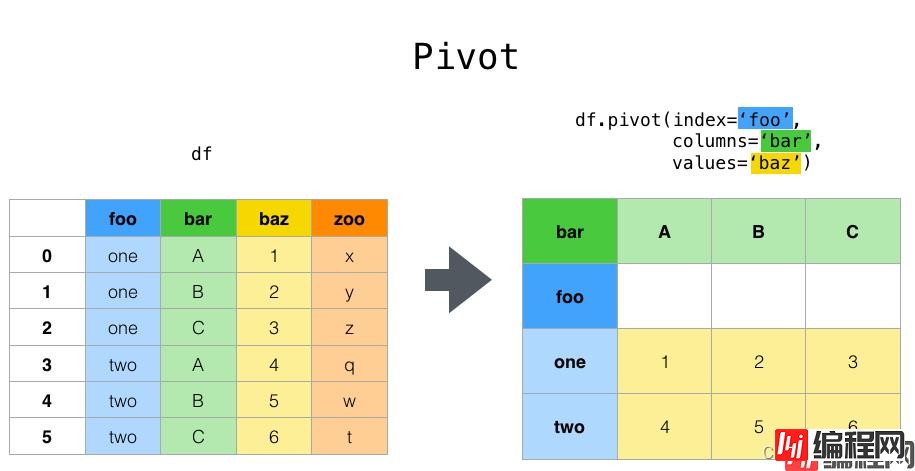
pivot参数:
用法如下,首先生成案例数据df
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two', 'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
df
df.pivot(index='foo', columns='bar', values='baz')
可以看到是一一对应。简单来说就是把foo、bar两个分类变量整到行列名称上去了,baz作为值
# 多层索引,可以取其中一列
df.pivot(index='foo', columns='bar') #['baz']
# 指定值
df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])
上面的pivot只适用于一一对应的情况,如果分类变量的组合一样,但是取值不一样就会报错。此时应该用Pivot Table,他默认计算相同情况的均值。
参数:
df = pd.DataFrame({"A": ["a1", "a1", "a1", "a2", "a2","a2"],
"B": ["b2", "b2", "b1", "b1", "b1","b1"],
"C": ['c1','c1','c2','c2','c1','c1'],
"D": [1, 2, 3, 4, 5, 6]})
df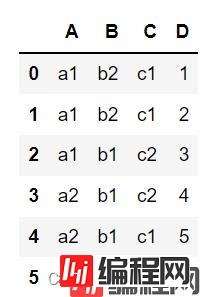
#索引a,列b使用Pivot会报错,因为他们之间的组合有重复,要用Pivot Table,默认计算均值
pd.pivot_table(df,index='A',columns='B',values='D')
#验证一下b1,a2这个均值5
df.loc[(df.A=='a2')&(df.B=='b1')].D.mean()
pd.pivot_table(df,index=['A','B'],#指定多个索引
columns=['C'], #指定列
values='D', #数据值列
aggfunc=np.sum, #聚合函数
fill_value=0, #空值填充
margins=True #增加汇总列
)
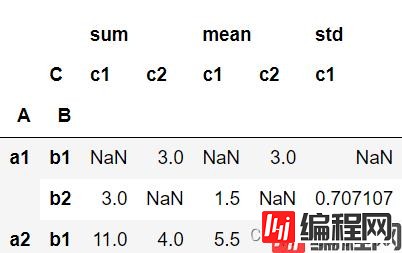
#多个计算方法
pd.pivot_table(df,index=['A','B'],#指定多个索引
columns=['C'], #指定列
values='D', #数据值列
aggfunc=[np.sum,np.mean,np.std]
)
交叉表是用于统计分组频率的特殊透视表。简单来说,就是将两个或者多个列重中不重复的元素组成一个新的 DataFrame,新数据的行和列交叉的部分值为其组合在原数据中的数量
语法结构如下:
pd.crosstab(index, columns, values=None, rownames=None,colnames=None, aggfunc=None, margins=False,
margins_name: str = 'All', dropna: bool = True,nORMalize=False) #→ 'DataFrame'
参数说明:
index:类数组,在行中按分组的值。
columns:类数组的值,用于在列中进行分组。
values:类数组的,可选的,要根据因素汇总的值数组。
aggfunc:函数,可选,如果未传递任何值数组,则计算频率表。
rownames:序列,默认为None,必须与传递的行数组数匹配。
colnames:序列,默认值为None,如果传递,则必须与传递的列数组数匹配。
margins:布尔值,默认为False,添加行/列边距(小计)
normalize:布尔值,{'all','index','columns'}或{0,1},默认为False。 通过将所有值除以值的总和进行归一化。'
生成案例数据:
df = pd.DataFrame({"A": ["a1", "a1", "a1", "a2", "a2","a2"],
"B": ["b2", "b2", "b1", "b1", "b1","b1"],
"C": ['c1','c1','c2','c2','c1','c1'],
"D": [1, 2, 3, 4, 5, 6]})
df
pd.crosstab(df['A'],df['B']) #都是分类数据,计算频率
pd.crosstab(df['A'],df['C']) #都是分类数据
#对交叉结果进行归一化:
pd.crosstab(df['A'], df['B'], normalize=True)
#对每列进行归一化:
pd.crosstab(df['A'], df['B'], normalize='columns')
#聚合,指定列做为值,并将这些值按一定算法进行聚合:
pd.crosstab(df['A'], df['C'], values=df['D'], aggfunc=np.sum) #分类和数值
#边距汇总,在最右边增加一个汇总列:
pd.crosstab(df['A'], df['B'],values=df['D'],aggfunc=np.sum,
normalize=True,margins=True)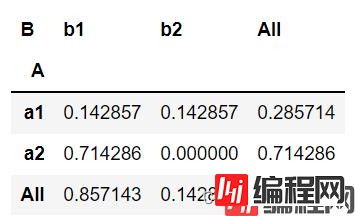
#df.melt() 是 df.pivot() 逆转操作函数。简单说就是将指定的列放到铺开放到行上名为variable(可指定)列,值在value(可指定)列
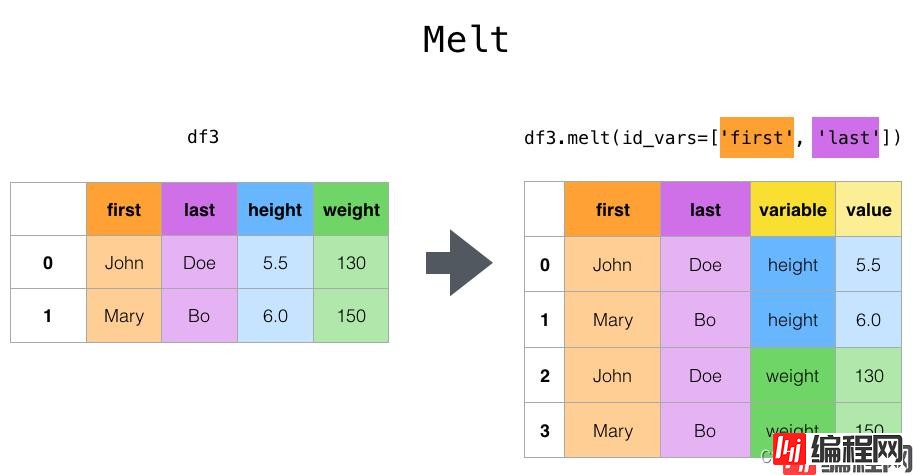
语法结构:
具体语法结构如下:
pd.melt(frame: pandas.core.frame.DataFrame,id_vars=None, value_vars=None,
var_name='variable', value_name='value',col_level=None)其中:
生成案例数据:
df=pd.DataFrame({'A':['a1','a2','a3','a4','a5'],
'B':['b1','b2','b3','b4','b5'],
'C':[1,2,3,4,5]})
df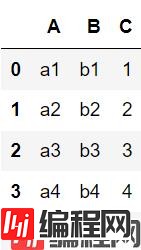
pd.melt(df)
#指定标识和值,
pd.melt(df,id_vars=['A']) #只对BC展开
pd.melt(df,value_vars=['B','C']) #保留BC,并展开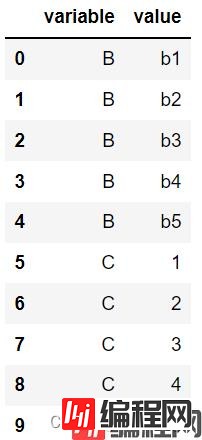
#同时指定,并命名
pd.melt(df,id_vars=['A'],value_vars=['B'],var_name='B_label',value_name='B_value') 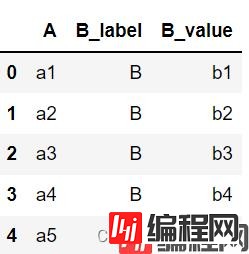
#stack就是把列变量堆到行上,unstack就是行变到列上
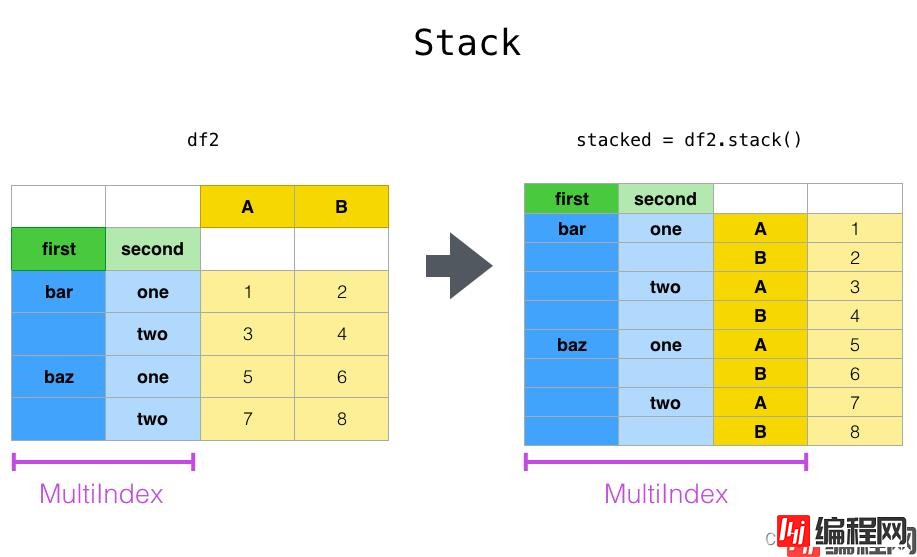
生成案例数据 :
#堆叠 stack 单层索引:
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2','b1','b2'],
'C':[1,2,3,4],
'D':[5,6,7,8],
'E':[5,6,7,8]})
df.set_index(['A','B'],inplace=True)
df
stack 堆叠
df.stack()
unstack 解堆
df.stack().unstack()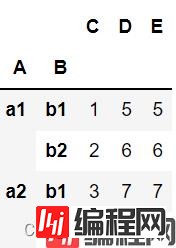
df.stack().unstack().unstack()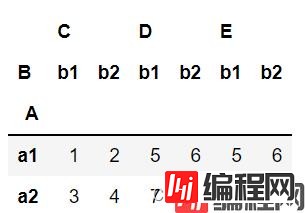
df.stack().unstack().unstack().unstack()
可以看到,解堆就是不停地把列变量弄到行上去作为索引。
到此这篇关于Pandas数据分析之pandas数据透视表和交叉表的文章就介绍到这了,更多相关pandas数据透视表内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Pandas数据分析之pandas数据透视表和交叉表
本文链接: https://lsjlt.com/news/119951.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0