这篇文章主要介绍“nodejs中的进程管理怎么实现”,在日常操作中,相信很多人在nodejs中的进程管理怎么实现问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”NodeJS中的
这篇文章主要介绍“nodejs中的进程管理怎么实现”,在日常操作中,相信很多人在nodejs中的进程管理怎么实现问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”NodeJS中的进程管理怎么实现”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
熟悉 js 的朋友都知道,js 是单线程的,在 Node 中,采用的是 多进程单线程 的模型。由于javascript单线程的限制,在多核服务器上,我们往往需要启动多个进程才能最大化服务器性能。
node.js 进程集群可用于运行多个 Node.js 实例,这些实例可以在其应用程序线程之间分配工作负载。 当不需要进程隔离时,请改用 worker_threads 模块,它允许在单个 Node.js 实例中运行多个应用程序线程。
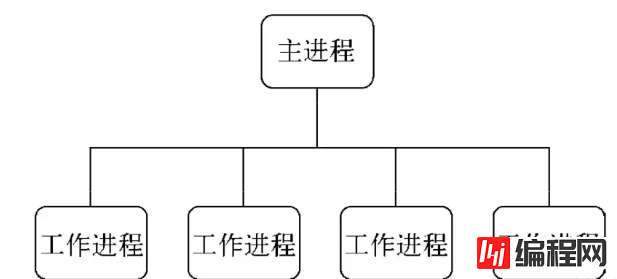
进程总数,其中一个主进程,cpu 个数 x cpu 核数 个 子进程
无论 child_process 还是 cluster,都不是多线程模型,而是多进程模型
应对单线程问题,通常使用多进程的方式来模拟多线程
Node 在 V0.8 版本之后引入了 cluster模块,通过一个主进程 (master) 管理多个子进程 (worker) 的方式实现集群。
集群模块可以轻松创建共享服务器端口的子进程。
cluster 底层是 child_process 模块,除了可以发送普通消息,还可以发送底层对象
tcp、UDP等,cluster模块是child_process模块和net模块的组合应用。 cluster 启动时,内部会启动 TCP 服务器,将这个 TCP 服务器端 Socket 的文件描述符发给工作进程。
在 cluster 模块应用中,一个主进程只能管理一组工作进程,其运作模式没有 child_process 模块那么灵活,但是更加稳定:
const cluster = require('cluster')复.isMaster 标识主进程, Node<16
.isPrimary 标识主进程, Node>16
.isWorker 标识子进程
.worker 对当前工作进程对象的引用【子进程中】
.workers 存储活动工作进程对象的哈希,以 id 字段为键。 这样可以很容易地遍历所有工作进程。 它仅在主进程中可用。cluster.wokers[id] === worker【主进程中】
.settings 只读, cluster配置项。在调用 .setupPrimary()或.fork()方法之后,此设置对象将包含设置,包括默认值。之前为空对象。此对象不应手动更改或设置。
cluster.settings配置项详情:- `execArgv` <string[]>传给 Node.js 可执行文件的字符串参数列表。 **默认值:** `process.execArgv`。
- `exec` <string> 工作进程文件的文件路径。 **默认值:** `process.argv[1]`。
- `args` <string[]> 传给工作进程的字符串参数。 **默认值:**`process.argv.slice(2)`。
- `cwd` <string>工作进程的当前工作目录。 **默认值:** `undefined` (从父进程继承)。
- `serialization` <string>指定用于在进程之间发送消息的序列化类型。 可能的值为 `'JSON'` 和 `'advanced'`。 **默认值:** `false`。
- `silent` <boolean>是否将输出发送到父进程的标准输入输出。 **默认值:** `false`。
- `stdio` <Array>配置衍生进程的标准输入输出。 由于集群模块依赖 IPC 来运行,因此此配置必须包含 `'ipc'` 条目。 提供此选项时,它会覆盖 `silent`。
- `uid` <number>设置进程的用户标识。
- `gid` <number>设置进程的群组标识。
- `inspectPort` <number> | <Function> 设置工作进程的检查器端口。 这可以是数字,也可以是不带参数并返回数字的函数。 默认情况下,每个工作进程都有自己的端口,从主进程的 `process.debugPort` 开始递增。
- `windowsHide` <boolean> 隐藏通常在 Windows 系统上创建的衍生进程控制台窗口。 **默认值:** `false`。.fork([env]) 衍生新的工作进程【主进程中】
.setupPrimary([settings]) Node>16
.setupMaster([settings]) 用于更改默认的 'fork' 行为,用后设置将出现在 cluster.settings 中。任何设置更改只会影响未来对 .fork()的调用,而不会影响已经运行的工作进程。上述默认值仅适用于第一次调用。Node 小于 16【主进程中】
.disconnect([callback]) 当所有工作进程断开连接并关闭句柄时调用【主进程中】
为了让集群更加稳定和健壮,cluster 模块也暴露了许多事件:
'message' 事件, 当集群主进程接收到来自任何工作进程的消息时触发。
'exit' 事件, 当任何工作进程死亡时,则集群模块将触发 'exit' 事件。
cluster.on('exit', (worker, code, signal) => {
console.log('worker %d died (%s). restarting...',
worker.process.pid, signal || code);
cluster.fork();
});'listening'事件,从工作进程调用 listen() 后,当服务器上触发 'listening' 事件时,则主进程中的 cluster 也将触发 'listening' 事件。
cluster.on('listening', (worker, address) => {
console.log(
`A worker is now connected to ${address.address}:${address.port}`);
});'fork' 事件,当新的工作进程被衍生时,则集群模块将触发 'fork' 事件。
cluster.on('fork', (worker) => {
timeouts[worker.id] = setTimeout(errORMsg, 2000);
});'setup' 事件,每次调用 .setupPrimary()时触发。
disconnect事件,在工作进程 IPC 通道断开连接后触发。 当工作进程正常退出、被杀死、或手动断开连接时
cluster.on('disconnect', (worker) => {
console.log(`The worker #${worker.id} has disconnected`);
});Worker 对象包含了工作进程的所有公共的信息和方法。 在主进程中,可以使用 cluster.workers 来获取它。 在工作进程中,可以使用 cluster.worker 来获取它。
.id 工作进程标识,每个新的工作进程都被赋予了自己唯一的 id,此 id 存储在 id。当工作进程存活时,这是在 cluster.workers 中索引它的键。
.process 所有工作进程都是使用 child_process.fork() 创建,此函数返回的对象存储为 .process。 在工作进程中,存储了全局的 process。
.send(message[, sendHandle[, options]][, callback]) 向工作进程或主进程发送消息,可选择使用句柄。在主进程中,这会向特定的工作进程发送消息。 它与 ChildProcess.send()相同。在工作进程中,这会向主进程发送消息。 它与 process.send() 相同。
.destroy()
.kill([signal])此函数会杀死工作进程。kill() 函数在不等待正常断开连接的情况下杀死工作进程,它与 worker.process.kill() 具有相同的行为。为了向后兼容,此方法别名为 worker.destroy()。
.disconnect([callback])发送给工作进程,使其调用自身的 .disconnect()将关闭所有服务器,等待那些服务器上的 'close' 事件,然后断开 IPC 通道。
.isConnect() 如果工作进程通过其 IPC 通道连接到其主进程,则此函数返回 true,否则返回 false。 工作进程在创建后连接到其主进程。
.isDead()如果工作进程已终止(由于退出或收到信号),则此函数返回 true。 否则,它返回 false。
为了让集群更加稳定和健壮,cluster 模块也暴露了许多事件:
'message' 事件, 在工作进程中。
cluster.workers[id].on('message', messageHandler);'exit' 事件, 当任何工作进程死亡时,则当前worker工作进程对象将触发 'exit' 事件。
if (cluster.isPrimary) {
const worker = cluster.fork();
worker.on('exit', (code, signal) => {
if (signal) {
console.log(`worker was killed by signal: ${signal}`);
} else if (code !== 0) {
console.log(`worker exited with error code: ${code}`);
} else {
console.log('worker success!');
}
});
}'listening'事件,从工作进程调用 listen() ,对当前工作进程进行监听。
cluster.fork().on('listening', (address) => {
// 工作进程正在监听
});disconnect事件,在工作进程 IPC 通道断开连接后触发。 当工作进程正常退出、被杀死、或手动断开连接时
cluster.fork().on('disconnect', () => {
//限定于当前worker对象触发
});Node中主进程和子进程之间通过进程间通信 (IPC) 实现进程间的通信,进程间通过 .send()(a.send表示向a发送)方法发送消息,监听 message 事件收取信息,这是 cluster模块 通过集成 EventEmitter 实现的。还是一个简单的官网的进程间通信例子
子进程:process.on('message')、process.send()
父进程:child.on('message')、child.send()
# cluster.isMaster
# cluster.fork()
# cluster.workers
# cluster.workers[id].on('message', messageHandler);
# cluster.workers[id].send();
# process.on('message', messageHandler);
# process.send();
const cluster = require('cluster');
const Http = require('http');
# 主进程
if (cluster.isMaster) {
// Keep track of http requests
console.log(`Primary ${process.pid} is running`);
let numReqs = 0;
// Count requests
function messageHandler(msg) {
if (msg.cmd && msg.cmd === 'notifyRequest') {
numReqs += 1;
}
}
// Start workers and listen for messages containing notifyRequest
// 开启多进程(cpu核心数)
// 衍生工作进程。
const numCPUs = require('os').cpus().length;
for (let i = 0; i < numCPUs; i++) {
console.log(i)
cluster.fork();
}
// cluster worker 主进程与子进程通信
for (const id in cluster.workers) {
// ***监听来自子进程的事件
cluster.workers[id].on('message', messageHandler);
// ***向子进程发送
cluster.workers[id].send({
type: 'masterToWorker',
from: 'master',
data: {
number: Math.floor(Math.random() * 50)
}
});
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
# 子进程
// 工作进程可以共享任何 TCP 连接
// 在本示例中,其是 HTTP 服务器
// Worker processes have a http server.
http.Server((req, res) => {
res.writeHead(200);
res.end('hello world\n');
/
subprocess.send(message, sendHandle)当父子进程之间建立 IPC 通道之后,通过子进程对象的 send 方法发送消息,第二个参数 sendHandle 就是句柄,可以是 TCP套接字、TCP服务器、UDP套接字等,为了解决上面多进程端口占用问题,我们将主进程的 socket 传递到子进程。
# master.js
const fork = require('child_process').fork;
const cpus = require('os').cpus();
const server = require('net').createServer();
server.listen(3000);
process.title = 'node-master'
for (let i=0; i<cpus.length; i++) {
const worker = fork('worker.js');
# 句柄传递
worker.send('server', server);
console.log('worker process created, pid: %s ppid: %s', worker.pid, process.pid);
}// worker.js
let worker;
process.title = 'node-worker'
process.on('message', function (message, sendHandle) {
if (message === 'server') {
worker = sendHandle;
worker.on('connection', function (socket) {
console.log('I am worker, pid: ' + process.pid + ', ppid: ' + process.ppid)
});
}
});验证一番,控制台执行 node master.js


了解 cluster 的话会知道,子进程是通过 cluster.fork() 创建的。在 linux 中,系统原生提供了 fork 方法,那么为什么 Node 选择自己实现 cluster模块 ,而不是直接使用系统原生的方法?主要的原因是以下两点:
fork的进程监听同一端口会导致端口占用错误
fork的进程之间没有负载均衡,容易导致惊群现象
在 cluster模块 中,针对第一个问题,通过判断当前进程是否为 master进程,若是,则监听端口,若不是则表示为 fork 的 worker进程,不监听端口。
针对第二个问题,cluster模块 内置了负载均衡功能, master进程 负责监听端口接收请求,然后通过调度算法(默认为 Round-Robin,可以通过环境变量 NODE_CLUSTER_SCHED_POLICY 修改调度算法)分配给对应的 worker进程。
当代码抛出了异常没有被捕获到时,进程将会退出,此时 Node.js 提供了 process.on('uncaughtException', handler) 接口来捕获它,但是当一个 Worker 进程遇到未捕获的异常时,它已经处于一个不确定状态,此时我们应该让这个进程优雅退出:
关闭异常 Worker 进程所有的 TCP Server(将已有的连接快速断开,且不再接收新的连接),断开和 Master 的 IPC 通道,不再接受新的用户请求。
Master 立刻 fork 一个新的 Worker 进程,保证在线的『工人』总数不变。
异常 Worker 等待一段时间,处理完已经接受的请求后退出。
+---------+ +---------+
| Worker | | Master |
+---------+ +----+----+
| uncaughtException |
+------------+ |
| | | +---------+
| <----------+ | | Worker |
| | +----+----+
| disconnect | fork a new worker |
+-------------------------> + ---------------------> |
| wait... | |
| exit | |
+-------------------------> | |
| | |
die | |
| |
| |当一个进程出现异常导致 crash 或者 OOM 被系统杀死时,不像未捕获异常发生时我们还有机会让进程继续执行,只能够让当前进程直接退出,Master 立刻 fork 一个新的 Worker。
child_process 模块提供了衍生子进程的能力, 简单来说就是执行cmd命令的能力。
默认情况下, stdin、 stdout 和 stderr 的管道会在父 Node.js 进程和衍生的子进程之间建立。 这些管道具有有限的(且平台特定的)容量。 如果子进程写入 stdout 时超出该限制且没有捕获输出,则子进程会阻塞并等待管道缓冲区接受更多的数据。 这与 shell 中的管道的行为相同。 如果不消费输出,则使用 { stdio: 'ignore' } 选项。
const cp = require('child_process');通过 api 创建出来的子进程和父进程没有任何必然联系
4个异步方法,创建子进程:fork、exec、execFile、spawn
spawn(command, args):处理一些会有很多子进程 I/O 时、进程会有大量输出时使用
execFile(file, args[, callback]):只需执行一个外部程序的时候使用,执行速度快,处理用户输入相对安全
exec(command, options):想直接访问线程的 shell 命令时使用,一定要注意用户输入
fork(modulePath, args):想将一个 Node 进程作为一个独立的进程来运行的时候使用,使得计算处理和文件描述器脱离 Node 主进程(复制一个子进程)
Node
非 Node
3个同步方法:execSync、execFileSync、spawnSync

其他三种方法都是 spawn() 的延伸。
fork 方法会开放一个 IPC 通道,不同的 Node 进程进行消息传送
一个子进程消耗 30ms 启动时间和 10MB 内存
记住,衍生的 Node.js 子进程独立于父进程,但两者之间建立的 IPC 通信通道除外。 每个进程都有自己的内存,带有自己的 V8 实例
举个?
在一个目录下新建 worker.js 和 master.js 两个文件:
# child.js
const t = JSON.parse(process.argv[2]);
console.error(`子进程 t=${JSON.stringify(t)}`);
process.send({hello:`儿子pid=${process.pid} 给爸爸进程pid=${process.ppid} 请安`});
process.on('message', (msg)=>{
console.error(`子进程 msg=${JSON.stringify(msg)}`);
});# parent.js
const {fork} = require('child_process');
for(let i = 0; i < 3; i++){
const p = fork('./child.js', [JSON.stringify({id:1,name:1})]);
p.on('message', (msg) => {
console.log(`messsgae from child msg=${JSON.stringify(msg)}`, );
});
p.send({hello:`来自爸爸${process.pid} 进程id=${i}的问候`});
}
通过 node parent.js 启动 parent.js,然后通过 ps aux | grep worker.js 查看进程的数量,我们可以发现,理想状况下,进程的数量等于 CPU 的核心数,每个进程各自利用一个 CPU 核心。
这是经典的 Master-Worker 模式(主从模式)

实际上,fork 进程是昂贵的,复制进程的目的是充分利用 CPU 资源,所以 NodeJS 在单线程上使用了事件驱动的方式来解决高并发的问题。
适用场景
一般用于比较耗时的场景,并且用node去实现的,比如下载文件;
fork可以实现多线程下载:将文件分成多块,然后每个进程下载一部分,最后拼起来;
会把输出结果缓存好,通过回调返回最后结果或者异常信息
const cp = require('child_process');
// 第一个参数,要运行的可执行文件的名称或路径。这里是echo
cp.execFile('echo', ['hello', 'world'], (err, stdout, stderr) => {
if (err) { console.error(err); }
console.log('stdout: ', stdout);
console.log('stderr: ', stderr);
});适用场景
比较适合开销小的任务,更关注结果,比如ls等;
主要用来执行一个shell方法,其内部还是调用了spawn ,不过他有最大缓存限制。
只有一个字符串命令
和 shell 一模一样
const cp = require('child_process');
cp.exec(`cat ${__dirname}/messy.txt | sort | uniq`, (err, stdout, stderr) => {
console.log(stdout);
});适用场景
比较适合开销小的任务,更关注结果,比如ls等;
通过流可以使用有大量数据输出的外部应用,节约内存
使用流提高数据响应效率
spawn 方法返回一个 I/O 的流接口
单一任务
const cp = require('child_process');
const child = cp.spawn('echo', ['hello', 'world']);
child.on('error', console.error);
# 输出是流,输出到主进程stdout,控制台
child.stdout.pipe(process.stdout);
child.stderr.pipe(process.stderr);多任务串联
const cp = require('child_process');
const path = require('path');
const cat = cp.spawn('cat', [path.resolve(__dirname, 'messy.txt')]);
const sort = cp.spawn('sort');
const uniq = cp.spawn('uniq');
# 输出是流
cat.stdout.pipe(sort.stdin);
sort.stdout.pipe(uniq.stdin);
uniq.stdout.pipe(process.stdout);适用场景
spawn是流式的,所以适合耗时任务,比如执行npm install,打印install的过程
在进程已结束并且子进程的标准输入输出流(sdtio)已关闭之后,则触发 'close' 事件。这个事件跟exit不同,因为多个进程可以共享同个stdio流。
参数:
code(退出码,如果子进程是自己退出的话)
signal(结束子进程的信号)
问题:code一定是有的吗?
(从对code的注解来看好像不是)比如用kill杀死子进程,那么,code是?
参数:
code、signal,如果子进程是自己退出的,那么code就是退出码,否则为null;
如果子进程是通过信号结束的,那么,signal就是结束进程的信号,否则为null。
这两者中,一者肯定不为null。
注意事项:exit事件触发时,子进程的stdio stream可能还打开着。(场景?)此外,nodejs监听了SIGINT和SIGTERM信号,也就是说,nodejs收到这两个信号时,不会立刻退出,而是先做一些清理的工作,然后重新抛出这两个信号。(目测此时js可以做清理工作了,比如关闭数据库等。)
SIGINT:interrupt,程序终止信号,通常在用户按下CTRL+C时发出,用来通知前台进程终止进程。SIGTERM:terminate,程序结束信号,该信号可以被阻塞和处理,通常用来要求程序自己正常退出。shell命令kill缺省产生这个信号。如果信号终止不了,我们才会尝试SIGKILL(强制终止)。
当发生下列事情时,error就会被触发。当error触发时,exit可能触发,也可能不触发。(内心是崩溃的)
无法衍生该进程。
进程无法kill。
向子进程发送消息失败。
当采用process.send()来发送消息时触发。
参数:message,为json对象,或者primitive value;sendHandle,net.Socket对象,或者net.Server对象(熟悉cluster的同学应该对这个不陌生)
.connected:当调用.disconnected()时,设为false。代表是否能够从子进程接收消息,或者对子进程发送消息。
.disconnect() :关闭父进程、子进程之间的IPC通道。当这个方法被调用时,disconnect事件就会触发。如果子进程是node实例(通过child_process.fork()创建),那么在子进程内部也可以主动调用process.disconnect()来终止IPC通道。
应对单线程问题,通常使用多进程的方式来模拟多线程
对 cpu 利用不足
某个未捕获的异常可能会导致整个程序的退出
Node 进程占用了 7 个线程
Node 中最核心的是 v8 引擎,在 Node 启动后,会创建 v8 的实例,这个实例是多线程的
主线程:编译、执行代码
编译/优化线程:在主线程执行的时候,可以优化代码
分析器线程:记录分析代码运行时间,为 Crankshaft 优化代码执行提供依据
垃圾回收的几个线程
JavaScript 的执行是单线程的,但 Javascript 的宿主环境,无论是 Node 还是浏览器都是多线程的。
Javascript 为什么是单线程?
这个问题需要从浏览器说起,在浏览器环境中对于 DOM 的操作,试想如果多个线程来对同一个 DOM 操作是不是就乱了呢,那也就意味着对于DOM的操作只能是单线程,避免 DOM 渲染冲突。在浏览器环境中 UI 渲染线程和 JS 执行引擎是互斥的,一方在执行时都会导致另一方被挂起,这是由 JS 引擎所决定的。
Node 中有一些 IO 操作(DNS,FS)和一些 CPU 密集计算(Zlib,Crypto)会启用 Node 的线程池
线程池默认大小为 4,可以手动更改线程池默认大小
process.env.UV_THREADPOOL_SIZE = 64Node 10.5.0 的发布,给出了一个实验性质的模块 worker_threads 给 Node 提供真正的多线程能力
worker_thread 模块中有 4 个对象和 2 个类
isMainThread: 是否是主线程,源码中是通过 threadId === 0 进行判断的。
MessagePort: 用于线程之间的通信,继承自 EventEmitter。
MessageChannel: 用于创建异步、双向通信的通道实例。
threadId: 线程 ID。
Worker: 用于在主线程中创建子线程。第一个参数为 filename,表示子线程执行的入口。
parentPort: 在 worker 线程里是表示父进程的 MessagePort 类型的对象,在主线程里为 null
workerData: 用于在主进程中向子进程传递数据(data 副本)
const {
isMainThread,
parentPort,
workerData,
threadId,
MessageChannel,
MessagePort,
Worker
} = require('worker_threads');
function mainThread() {
for (let i = 0; i < 5; i++) {
const worker = new Worker(__filename, { workerData: i });
worker.on('exit', code => { console.log(`main: worker stopped with exit code ${code}`); });
worker.on('message', msg => {
console.log(`main: receive ${msg}`);
worker.postMessage(msg + 1);
});
}
}
function workerThread() {
console.log(`worker: workerDate ${workerData}`);
parentPort.on('message', msg => {
console.log(`worker: receive ${msg}`);
}),
parentPort.postMessage(workerData);
}
if (isMainThread) {
mainThread();
} else {
workerThread();
}const assert = require('assert');
const {
Worker,
MessageChannel,
MessagePort,
isMainThread,
parentPort
} = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
const subChannel = new MessageChannel();
worker.postMessage({ hereIsYourPort: subChannel.port1 }, [subChannel.port1]);
subChannel.port2.on('message', (value) => {
console.log('received:', value);
});
} else {
parentPort.once('message', (value) => {
assert(value.hereIsYourPort instanceof MessagePort);
value.hereIsYourPort.postMessage('the worker is sending this');
value.hereIsYourPort.close();
});
}进程是资源分配的最小单位,线程是CPU调度的最小单位
IPC (Inter-process communication) 即进程间通信,由于每个进程创建之后都有自己的独立地址空间,实现 IPC 的目的就是为了进程之间资源共享访问。
实现 IPC 的方式有多种:管道、消息队列、信号量、Domain Socket,Node.js 通过 pipe 来实现。
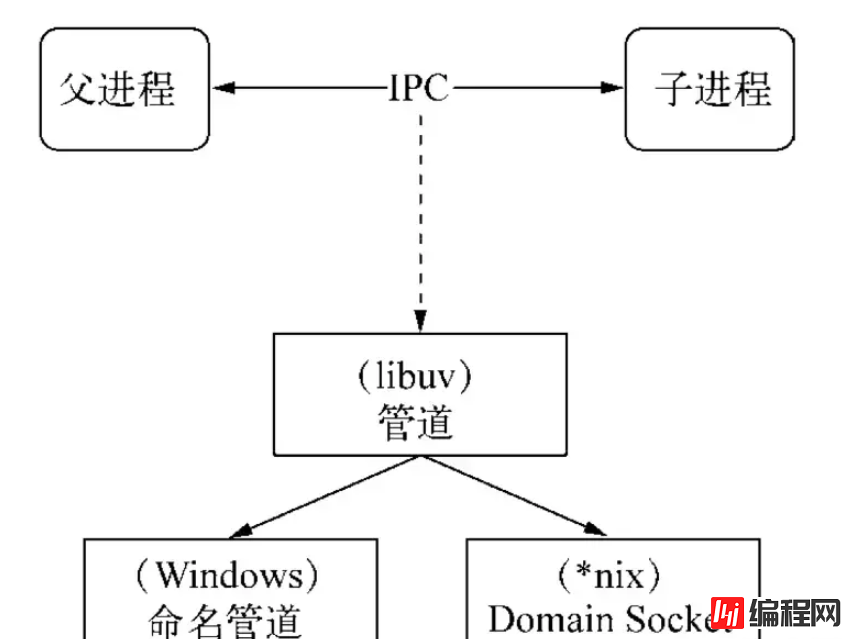
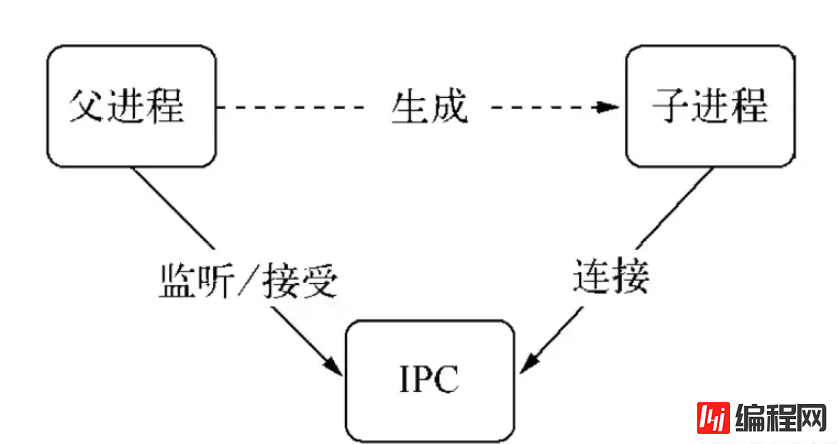
实际上,父进程会在创建子进程之前,会先创建 IPC 通道并监听这个 IPC,然后再创建子进程,通过环境变量(NODE_CHANNEL_FD)告诉子进程和 IPC 通道相关的文件描述符,子进程启动的时候根据文件描述符连接 IPC 通道,从而和父进程建立连接。
句柄是一种可以用来标识资源的引用的,它的内部包含了指向对象的文件资源描述符。
一般情况下,当我们想要将多个进程监听到一个端口下,可能会考虑使用主进程代理的方式处理:

然而,这种代理方案会导致每次请求的接收和代理转发用掉两个文件描述符,而系统的文件描述符是有限的,这种方式会影响系统的扩展能力。
所以,为什么要使用句柄?原因是在实际应用场景下,建立 IPC 通信后可能会涉及到比较复杂的数据处理场景,句柄可以作为 send() 方法的第二个可选参数传入,也就是说可以直接将资源的标识通过 IPC 传输,避免了上面所说的代理转发造成的文件描述符的使用。

以下是支持发送的句柄类型:
net.Socket
net.Server
net.Native
dgram.Socket
dgram.Native
父进程创建子进程之后,父进程退出了,但是父进程对应的一个或多个子进程还在运行,这些子进程会被系统的 init 进程收养,对应的进程 ppid 为 1,这就是孤儿进程。通过以下代码示例说明。
# worker.js
const http = require('http');
const server = http.createServer((req, res) => {
res.end('I am worker, pid: ' + process.pid + ', ppid: ' + process.ppid);
// 记录当前工作进程 pid 及父进程 ppid
});
let worker;
process.on('message', function (message, sendHandle) {
if (message === 'server') {
worker = sendHandle;
worker.on('connection', function(socket) {
server.emit('connection', socket);
});
}
});# master.js
const fork = require('child_process').fork;
const server = require('net').createServer();
server.listen(3000);
const worker = fork('worker.js');
worker.send('server', server);
console.log('worker process created, pid: %s ppid: %s', worker.pid, process.pid);
process.exit(0);
// 创建子进程之后,主进程退出,此时创建的 worker 进程会成为孤儿进程控制台进行测试,输出当前工作进程 pid 和 父进程 ppid

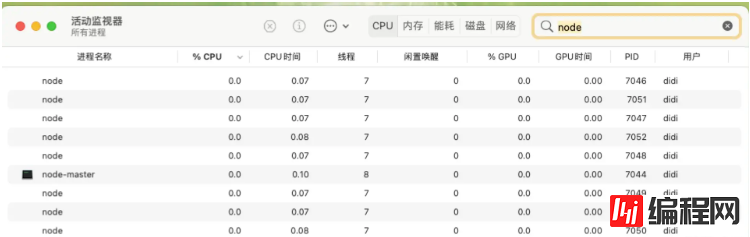
由于在 master.js 里退出了父进程,活动监视器所显示的也就只有工作进程。

再次验证,打开控制台调用接口,可以看到工作进程 5611 对应的 ppid 为 1(为 init 进程),此时已经成为了孤儿进程

守护进程运行在后台不受终端的影响,什么意思呢?
Node.js 开发的同学们可能熟悉,当我们打开终端执行 node app.js 开启一个服务进程之后,这个终端就会一直被占用,如果关掉终端,服务就会断掉,即前台运行模式。
如果采用守护进程进程方式,这个终端我执行 node app.js 开启一个服务进程之后,我还可以在这个终端上做些别的事情,且不会相互影响。
创建子进程
在子进程中创建新会话(调用系统函数 setsid)
改变子进程工作目录(如:“/” 或 “/usr/ 等)
父进程终止
index.js 文件里的处理逻辑使用 spawn 创建子进程完成了上面的第一步操作。
设置 options.detached 为 true 可以使子进程在父进程退出后继续运行(系统层会调用 setsid 方法),这是第二步操作。
options.cwd 指定当前子进程工作目录若不做设置默认继承当前工作目录,这是第三步操作。
运行 daemon.unref() 退出父进程,这是第四步操作。
// index.js
const spawn = require('child_process').spawn;
function startDaemon() {
const daemon = spawn('node', ['daemon.js'], {
cwd: '/usr',
detached : true,
stdio: 'ignore',
});
console.log('守护进程开启 父进程 pid: %s, 守护进程 pid: %s', process.pid, daemon.pid);
daemon.unref();
}
startDaemon()daemon.js 文件里处理逻辑开启一个定时器每 10 秒执行一次,使得这个资源不会退出,同时写入日志到子进程当前工作目录下
/usr/daemon.js
const fs = require('fs');
const { Console } = require('console');
// custom simple logger
const logger = new Console(fs.createWriteStream('./stdout.log'), fs.createWriteStream('./stderr.log'));
setInterval(function() {
logger.log('daemon pid: ', process.pid, ', ppid: ', process.ppid);
}, 1000 * 10);

在实际工作中对于守护进程并不陌生,例如 PM2、Egg-Cluster 等,以上只是一个简单的 Demo 对守护进程做了一个说明,在实际工作中对守护进程的健壮性要求还是很高的,例如:进程的异常监听、工作进程管理调度、进程挂掉之后重启等等,这些还需要去不断思考。
目录是什么?
进程的当前工作目录可以通过 process.cwd() 命令获取,默认为当前启动的目录,如果是创建子进程则继承于父进程的目录,可通过 process.chdir() 命令重置,例如通过 spawn 命令创建的子进程可以指定 cwd 选项设置子进程的工作目录。
有什么作用?
例如,通过 fs 读取文件,如果设置为相对路径则相对于当前进程启动的目录进行查找,所以,启动目录设置有误的情况下将无法得到正确的结果。还有一种情况程序里引用第三方模块也是根据当前进程启动的目录来进行查找的。
// 示例
process.chdir('/Users/may/Documents/test/') // 设置当前进程目录
console.log(process.cwd()); // 获取当前进程目录到此,关于“NodeJS中的进程管理怎么实现”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: NodeJS中的进程管理怎么实现
本文链接: https://lsjlt.com/news/98695.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0