【开发】sql优化思路(以oracle为例) powered by wanglifeng https://www.cnblogs.com/wanglifeng717 单表查询的优化思路 单表查询是最简单也是最重要的模块,它是多表等查询的

powered by wanglifeng https://www.cnblogs.com/wanglifeng717
单表查询是最简单也是最重要的模块,它是多表等查询的基础。
能一次扫描拿到的数据,不要重复扫描,查一次库能解决的问题,最好不要多次查。数据的读取非常消耗资源,减少对数据块的扫描。
例如:
SELECT COUNT (*)
FROM employees
WHERE salary < 2000;
SELECT COUNT (*)
FROM employees
WHERE salary BETWEEN 2000 AND 4000;
SELECT COUNT (*)
FROM employees
WHERE salary>4000;
统计任务经常用的语句。其实每个语句基本都把全表或索引扫了一遍,既然要全扫,就把握机会,能一次搞定的就一次搞定。
改写成
SELECT COUNT (CASE WHEN salary < 2000 THEN 1 ELSE null END) count1,COUNT (CASE WHEN salary BETWEEN 2001 AND 4000 THEN 1 ELSE null END) count2,COUNT (CASE WHEN salary > 4000 THEN 1 ELSE null END) count3 FROM employees;
严格来说,我们不推荐写过度复杂“炫技”的SQL,不要生搬硬套示例,只是为了让大家有个“节省持家”的意识。
例如如下经典写法,通过object_id字段上的索引全扫一遍,拿到了多种类别信息,不要分三次查询。
select max(object_id),min(object_id),sum(object_id),avg(object_id),count(object_id) from t where object_id is not null;
从大选小,索引是你的不二选择。
例如:select t.name,t.status from t where t.pay_order_id = 101803309910017574;
索引利用B+树的原理可以快速找到某条数据,所以如果你想在大表中找到某条数据,索引是你必须要使用的技术。如上例所示,通过在pay_order_id上索引快速锁定这条数据的rowid,通过回表找到其他字段 t.name,t.status。这条语句就可以迅速执行,即使是千万级别表。原因还是全表扫描读的块非常多,而索引锁定数据快,读的块非常少,所以时间很快。
如果表记录数很少,使用索引效率反而低。例如,只有几十条记录,所有数据在一个
block 内。则全表扫描只需 1 个 block 的 io,而索引读由于回表等可能需要几个 block。
例如:select t.name,t.status from t where t.pay_order_id < 101803309910017574;
上例所示,执行计划可能是全表扫描,也可能走索引。
主要决定因素之一是oracle的代价计算(cost),如果数据量比较大,走索引读,每条数据都伴随着一次回表操作。而全表扫描可以一次读多个块进内存。两种方式相比之下,哪条路径的代价低,oracle就会选择哪条。
所以,全表扫描的速度不一定慢。如果上述的SQL没有满足你的性能需求,且需求不能变,导致SQL已经不能修改时,我们可以考虑能否消除索引的回表操作。无论表多大,结果集多大,一旦所要的数据在索引块中都能找到,就不需要回表。因为索引全扫的块肯定比全表扫的块少的多的多,oracle肯定走索引全扫。
例如:
create index t_uNIOn_uuid_order_id on t(pay_order_id,uuid);
select uuid,pay_order_id from t where t.pay_order_id<101803300910017574;
如上例所示,所要字段数据在组合索引块中都能找到,所以没有回表操作。而索引块的数量远远小于全表数据的块数量,即使索引全扫,性能也非常好。
绝大多数情况下,这条select t.name,t.status from t where t.pay_order_id < 101809910017574语句我们可以控制下结果集,让索引即使回表,代价也远低于全表扫描。
组合索引不推荐三个及以上的字段建立组合索引,如果需要的字段非常多,不方便建立组合索引,建议控制结果集,少量快速多次,索引或两字段组合索引,多手段结合使用。具体使用要具体问题具体分析。宗旨就是控制结果集,使得走索引的代价低于全表扫描,然后利用索引快速,读块少的优点提高效率。这样分批几次拿数据,可能速度比一次全拿还快。事实是结果集控制的好,往往全表扫描的效率都能满足需求,更何况是索引扫描。
这种场景首先要反问的就是这个需求是否存在问题,是否真的适合用关系型数据库?如果确实有这种需求。大表的数据量往往是惊人的,只能分页去拿。而ORACLE的三层select分页会越分越慢。
SELECT *
FROM (SELECT TA.*, ROWNUM ROW_NUM
FROM (select UUID, pay_order_id
from t
order by pay_order_id) TA
WHERE ROWNUM <= 100)
WHERE ROW_NUM > 0;
主要矛盾就是内层的WHERE ROWNUM <= 100,随着页数增加,结果集越来越大。2.order by的排序非常耗费性能,尤其大结果集的排序。3. 外层的WHERE ROW_NUM > 0随着页数越来越大,需要过滤的结果集也越来越大。
推荐方式:
SELECT t.*
FROM (select uuid, pay_order_id
from t
where t.pay_order_id is not null【*注】如果没有非空约束必须显示标明,否则索引失效
and t.pay_order_id >= "101809020001428452"
order by t.pay_order_id) t
WHERE ROWNUM <= 100;
pay_order_id 字段的需求是只增不减,为了不重不漏必须排序。索引是有序的,我们想用索引抵消掉排序,所以要查看执行计划,必须要走到索引。WHERE ROWNUM <= 100在oracle优化中会被推到内层语句中。所以实际结果集是t.pay_order_id >= "101809020001428452"之后的100条数据。所以结果集控制住了,索引代价肯定低于全表扫描,肯定走索引,索引又抵消了排序,同时 WHERE ROWNUM <= 100;每页都是100,rownum的性能损耗也控制住了。
这样额外的代价是,程序每次要记住最后一条pay_order_id,下次分页的时候将其带入。
推广到其他应用则可以选择表中的create_time字段代替pay_order_id。
多表查询和单表查询,唯一不同的就是把握住连接方式,只要连接方式把握住,多表查询其实就是多次单表查询。
三种连接方式:
nested loops join拿驱动表的结果集,去连接另外一个表,类似于两重嵌套循环(典型使用:小表驱动大表)。
hash join 拿驱动表的结果集去做hash表,PGA区,结果集大了,会到磁盘里。
merge join 无驱动表的概念,较少用到,对于连接键有序。
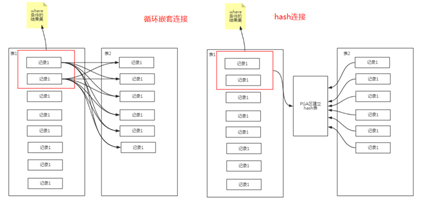
powered by wanglifeng Https://www.cnblogs.com/wanglifeng717
从原理图可以看出,循环嵌套连接和hash连接中驱动表非常关键,准确说驱动表的结果集非常关键。循环嵌套连接的结果集大了,双层循环非常低效,哈希连接结果集大了可能导致排序开销变大,PGA区放不下等问题。
驱动表是oracle自动选择的,默认是加了过滤条件后,结果集小的那个表。如果查看执行计划,驱动表不如你所愿,你需要检查结果集是否相比另一个表结果集来说,明显是小结果集。或者自动收集信息不准确,需要更新。
如果是多表连接查询少量数据,推荐走循环嵌套连接。
create index n_index_order_id on n(order_id);
create index t_index_query_id on t(query_id);
select t.id ,t.name,n.address from n, t where t.pay_order_id=n.order_id and t.query_id="261801163544557068";
在驱动表的过滤条件上建立索引,快速锁定需要的少量数据行,在被驱动表的连接字段上建立索引,方便连接条件迅速匹配。这样的配合,就算两个表都是千万级别的表,只要索引不失效,速度都非常快。
如果是多表连接要查询出一部分数据,推荐走哈希连接
首先过滤条件过滤出小结果集,小结果集是个相对的概念,有时1000条算小结果集,有时10条也算大结果集,这里的小结果集一般在百条量级。
哈希连接的特点就是,无论驱动表的结果集在一定范围内如何变化,理论上,一次查询的时间近似等于扫一遍被驱动表的时间。性能表现相当高效和稳定。
控制驱动表的结果集,在被驱动表的连接字段上建立索引,忽略回表等细节,确认走到索引,这样一次查询的时间近似等于被驱动表的索引全扫时间,而我们知道,索引块相对全表块是非常少的,索引全扫非常高效。
走哪种连接方式,是oracle自动选择的,oracle选择的规则就是基于上述原理,所以我们决定不了走哪种执行计划,但是我们能让oracle”不得不走”哪种执行计划。
控制结果集,不仅体现在单表查询的索引选择问题,还有体现在多表查询的连接方式和效率上。
除此之外还存在很多误区。结果集的概念并不是简单的数据量,而是一种意识,有控制结果集的意识,而不是教条主义的定义多少数量算大结果集。
结果集经典示例:
把in换成exists就完事了,性能就优化了,这是常犯的误区。
in是判断一个值是否在某个列中,而exists是判断一个值是否存在
Select * from tab where id in ( select id from tabel );
In 是先产生子查询结果集,然后主查询区结果集中寻找符合要求的字段列表,符合要求的输出。
Exists不返回列表值,而是true或者false,运行方式为,先运行主查询一次,在去子查询中查询与之对应的结果,如果子查询返回true则输出,反之不输出,在根据主查询的每一行去子查询中查询。
从原理可以看出,如果in的子查询结果集很大,外层的结果集也很大,相当于两个大结果集在连接运算,很耗性能。
Exists的运算比in优化了,但是就是搜索内层子查询的时候优化了,但是关键点是要把握住内外层的结果集,如果结果集很大,exists同样很慢,结果集控制的好,in操作也能符合要求。
--结束END--
本文标题: sql索引优化思路
本文链接: https://lsjlt.com/news/9105.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0