1.概述 最近有同学留言,kafka Eagle的分布式模式功能怎么使用,如何部署安装?今天笔者就为大家来详细介绍一下Kafka Eagle的分布式模式功能的安装和使用。 2.内容 首先,这里我们需要说明一下,Kafka Eagle已经更

最近有同学留言,kafka Eagle的分布式模式功能怎么使用,如何部署安装?今天笔者就为大家来详细介绍一下Kafka Eagle的分布式模式功能的安装和使用。
首先,这里我们需要说明一下,Kafka Eagle已经更名为EFAK(Eagle For Apache Kafka)。感谢Apache Kafka PMC的认可,EFAK将继续提供和开发新功能,来满足Kafka集群和应用的相关监控和管理功能。
当我们管理Kafka多集群或者一个规模较大的Kafka集群时,单机模式的EFAK部署时,运行的多线程任务,相关消费者、Topic、生产者、Broker & ZooKeeper的监控指标等内容调度时,部署EFAK的服务器如果配置较低,会造成很大的负载,对CPU的负载会很高。为了解决这类问题,EFAK开发了分布式模式的部署,可由多个低配置的服务器来组件一个EFAK集群。来对Kafka多集群进行监控和管理。
部署EFAK所需要的基础环境如下:
EFAK安装包,目前官网上以及发布了最新的v2.0.9版本,支持分布式模式部署。可以直接下载到Linux服务器进行安装和部署使用。如果需要自行编译部署,可以到GitHub下载源代码进行编译部署:
EFAK分布式模式部署,这里以5个节点为例子(1个Master和4个Slave),各个节点的角色如下如所示:
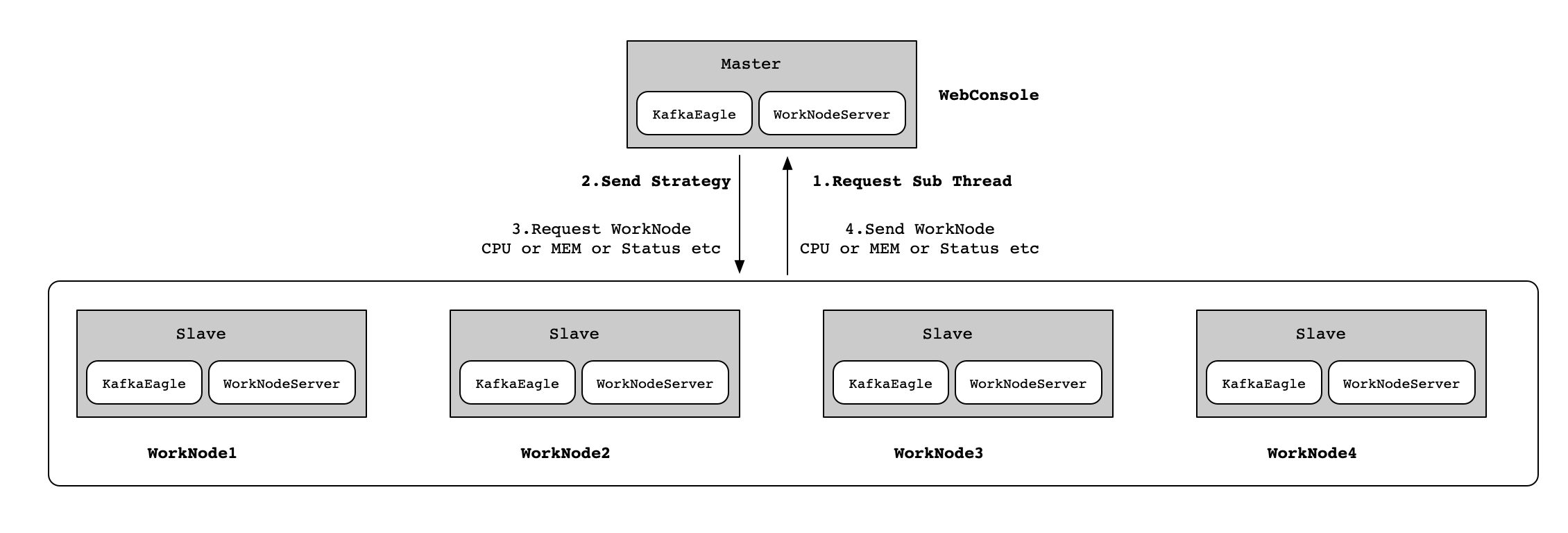
首先,我们定义一个服务器为Master节点,在Master节点上下载EFAK安装包,并配置EFAK所需要的环境变量,具体内容如下所示:
# 编辑环境变量文件
vi ~/.bash_profile
# 添加如下内容
# 添加JDK环境,建议使用JDK8以上
export JAVA_HOME=/data/soft/new/jdk
# 添加EFAK环境
export KE_HOME=/data/soft/new/efak
export PATH=$PATH:$JAVA_HOME/bin:$KE_HOME/bin然后执行source ~/.bash_profile命令使配置环境变量立即生效。
在EFAK的conf目录下有两个配置系统的文件,它们分别是:
works存储节点IP地址如下:
192.168.31.75
192.168.31.98
192.168.31.251
192.168.31.88EFAK配置信息如下所示:
######################################
# 配置Kafka集群别名和Zookeeper访问地址
######################################
efak.zk.cluster.alias=cluster1
cluster1.zk.list=192.168.31.127:2181
######################################
# Zookeeper是否启用ACL
######################################
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.passWord=test123
######################################
# 如果一个Kafka集群规模较大,可以配置该参数
# 例如:配置阀值为20,若当前Kafka集群节点超过20个,将启用离线统计
######################################
cluster1.efak.broker.size=20
######################################
# Zookeeper客户端线程数,单机模式设置16
# 分布式模式可以设置为4或者8(EFAK节点数大于5设置为4,若小于5设置为8即可)
######################################
kafka.zk.limit.size=8
######################################
# EFAK WEB页面启动端口
######################################
efak.webui.port=8048
######################################
# EFAK 是否启用分布式模式
######################################
efak.distributed.enable=true
# 在master节点上设置角色为master,其他节点设置为slave。
# 有个小技巧,就是从master节点同步配置到slave节点时,
# 将该属性先设置为slave,然后同步完成后,
# 将master节点上的slave值修改为master即可
efak.cluster.mode.status=master
# 设置master节点的IP地址
efak.worknode.master.host=192.168.31.199
# 设置一个可用的端口供WorkNodeServer使用
efak.worknode.port=8085
######################################
# kafka jmx 是否启用了ACL
######################################
cluster1.efak.jmx.acl=false
cluster1.efak.jmx.user=keadmin
cluster1.efak.jmx.password=keadmin123
cluster1.efak.jmx.ssl=false
cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststore
cluster1.efak.jmx.truststore.password=ke123456
######################################
# kafka offset 存储方式,
# 目前Kafka基本都是存储在Kafka的topic中,
# 可保留该默认值不变
######################################
cluster1.efak.offset.storage=kafka
######################################
# kafka jmx 地址,默认Apache发布的Kafka基本是这个默认值,
# 对于一些公有云Kafka厂商,它们会修改这个值,
# 比如会将jmxrmi修改为kafka或者是其它的值,
# 若是选择的公有云厂商的Kafka,可以根据实际的值来设置该属性
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka监控是否开启,以及存储的监控数据保留时间天数
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql 查询topic的单分区最近的条数,
# 以及在页面预览topic数据的最大记录条数
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# 删除topic的密钥,仅供管理员角色使用
######################################
efak.topic.token=keadmin
######################################
# kafka sasl 安全认证是否开启
######################################
cluster1.efak.sasl.enable=false
cluster1.efak.sasl.protocol=SASL_PLAINTEXT
cluster1.efak.sasl.mechanism=SCRAM-SHA-256
cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle";
cluster1.efak.sasl.client.id=
cluster1.efak.blacklist.topics=
cluster1.efak.sasl.cgroup.enable=false
cluster1.efak.sasl.cgroup.topics=
######################################
# kafka ssl 安全认证是否开启
######################################
cluster1.efak.ssl.enable=false
cluster1.efak.ssl.protocol=SSL
cluster1.efak.ssl.truststore.location=
cluster1.efak.ssl.truststore.password=
cluster1.efak.ssl.keystore.location=
cluster1.efak.ssl.keystore.password=
cluster1.efak.ssl.key.password=
cluster1.efak.ssl.endpoint.identification.alGorithm=https
cluster1.efak.blacklist.topics=
cluster1.efak.ssl.cgroup.enable=false
cluster1.efak.ssl.cgroup.topics=
######################################
# 生产环境建议使用Mysql来存储相关数据
######################################
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://localhost:3306/ke_prd?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456# 同步系统环境
for i in `cat $KE_HOME/conf/works`;do scp ~/.bash_profile $i:~/;done# 如果你的$KE_HOME环境地址为/data/soft/new/efak
for i in `cat $KE_HOME/conf/works`;do scp -r $KE_HOME $i:/data/soft/new/;done然后,修改Master节点上的属性值efak.cluster.mode.status,将Master节点上该属性值slave修改为master即可。其他Slave节点无需改动。
EFAK分布式模式新增了ke.sh cluster命令,该命令支持如下参数:
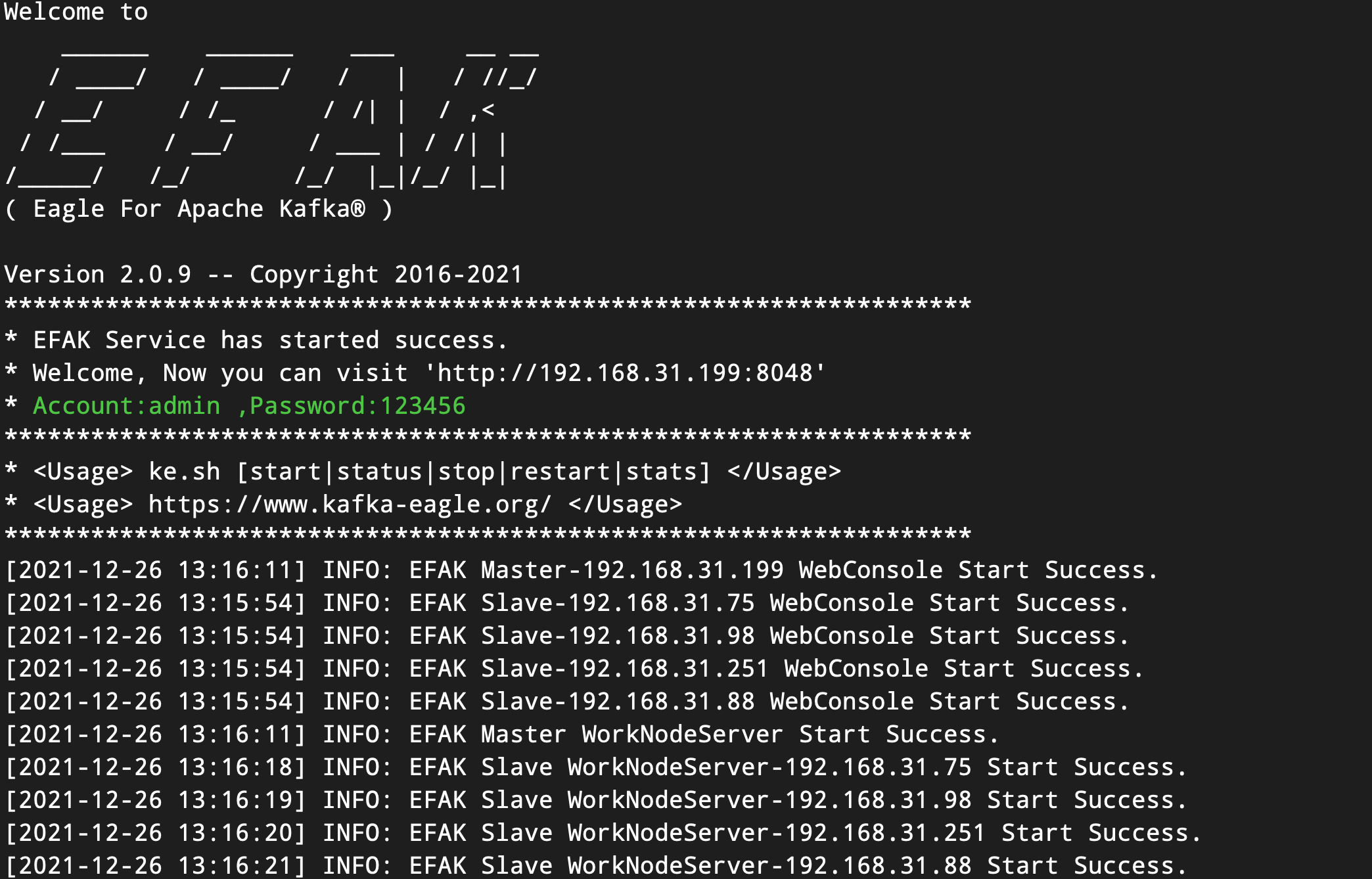
当我们完成EFAK系统环境和安装包的分发后,就可以执行ke.sh cluster start启动命令了。
# 启动 EFAK 分布式模式
ke.sh cluster start具体启动截图如下所示:
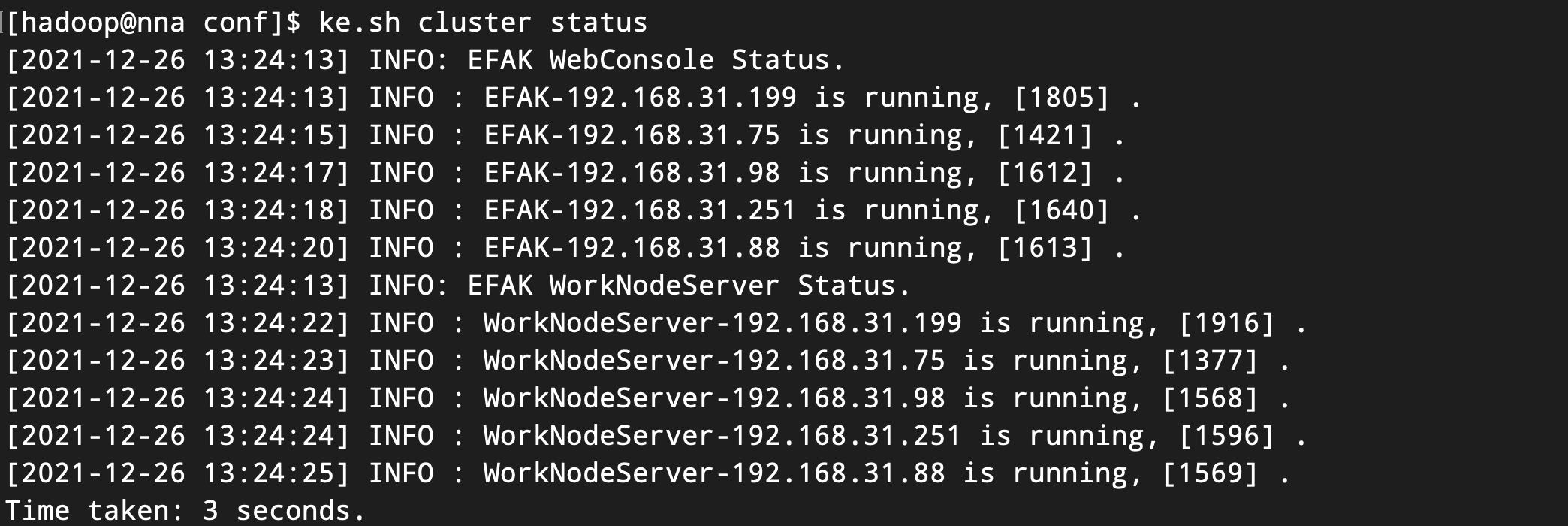
执行ke.sh cluster status命令查看各个节点的状态:
# 查看节点状态
ke.sh cluster status执行上述命令,具体截图如下所示:
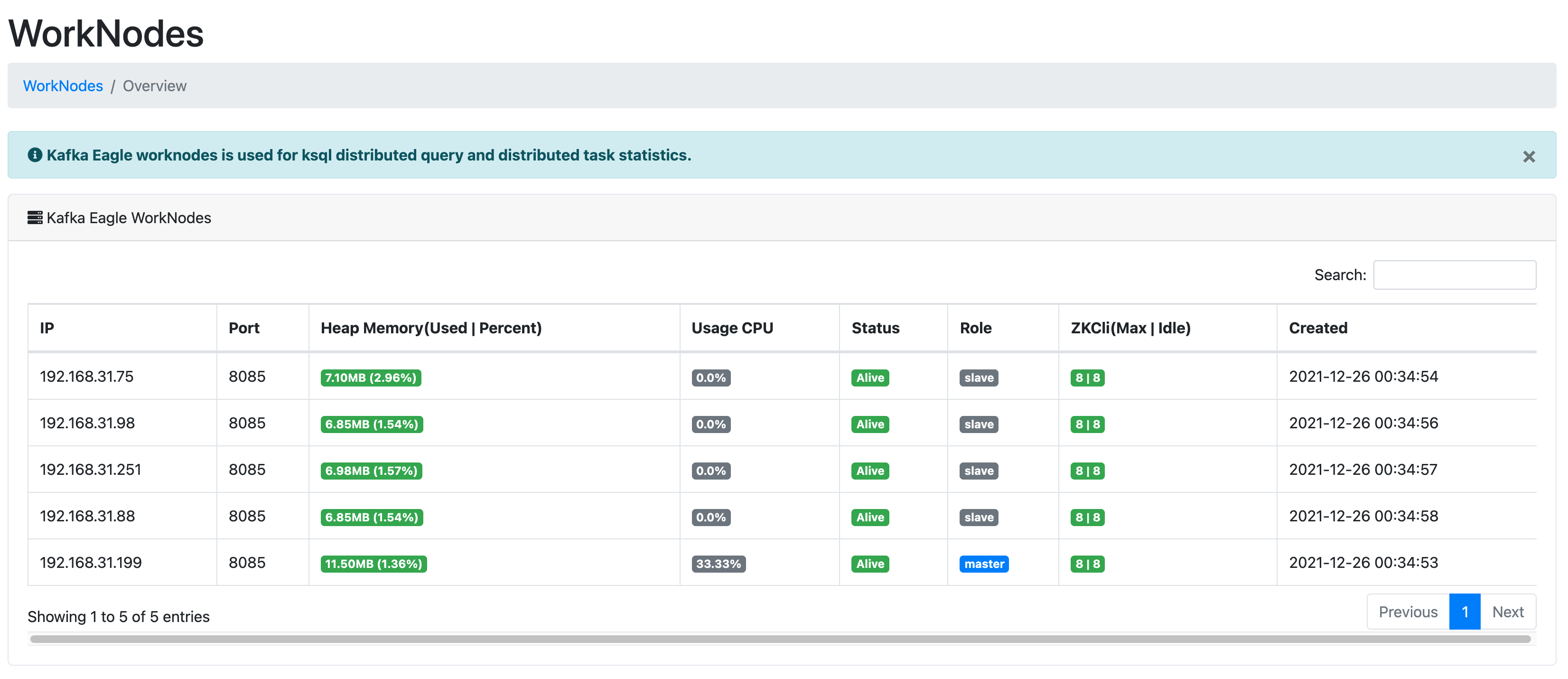
在EFAK分布式模式下,新增监控EFAK各个节点的功能(单击模式下也可以查看Master节点相关指标),具体监控内容如下图所示:
如果是Kafka集群规模较大或者管理的Kafka集群有多个,可以使用EFAK的分布式模式部署。如果管理的Kafka集群规模较小,Topic数量、消费者应用等较少,可以使用EFAK的单机模式部署即可。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
联系方式:
--结束END--
本文标题: Kafka Eagle分布式模式
本文链接: https://lsjlt.com/news/9025.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0