1.MapReduce概念 1)mapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题. 2)MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程

1.MapReduce概念
1)mapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
2)MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
3)MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
4)两个函数的形参和返回值都是
2.MapReduce核心思想
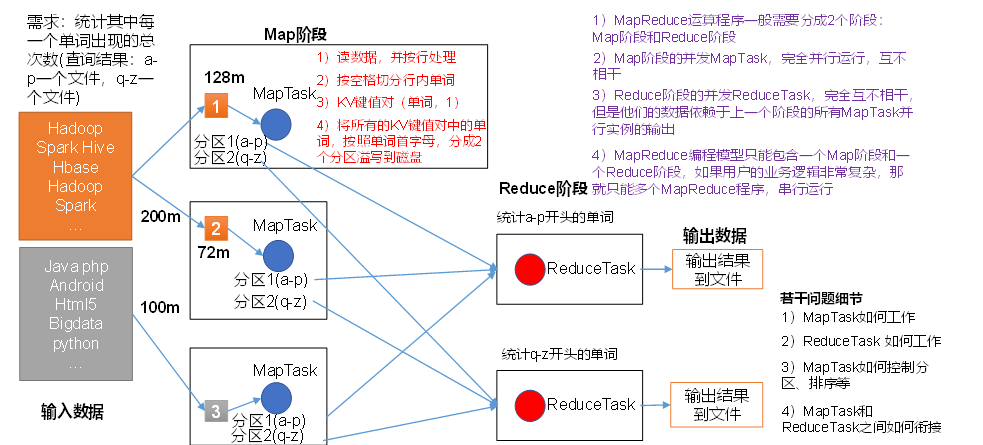
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。

3. MapReduce 中的shuffle

4.Mapreduce代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFORMat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
//分割任务
// 第一对kv,是决定数据输入的格式
// 第二队kv 是决定数据输出的格式
public static class MyMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
LongWritable longWritable = new LongWritable(1);
String s = value.toString();
context.write(new Text(s), longWritable);
}
}
//接收Map端数据
public static class MyReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//设置统计的初始值为0
long sum = 0l;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个job任务
Job job=Job.getInstance();
//指定job名称
job.setJobName("第一个mr程序");
//构建mr
//指定当前main所在类名(识别具体的类)
job.setjarByClass(WordCount.class);
//指定map端类
// 指定map输出的kv类型
job.setMapperClass(MyMapper.class);
job.setMapOutpuTKEyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reduce端类
//指定reduce端输出的kv类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定输入路径
Path in = new Path("/word");
FileInputFormat.addInputPath(job,in);
//输出路径指定
Path out = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
//如果文件存在
if(fs.exists(out)){
fs.delete(out,true);
}
//存在
FileOutputFormat.setOutputPath(job,out);
//启动
job.waitForCompletion(true);
System.out.println("MapReduce正在执行");
}
}
--结束END--
本文标题: MapReduce原理深入理解(一)
本文链接: https://lsjlt.com/news/8790.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0