准备工作: 安装jdk 克隆2台虚拟机完成后:新的2台虚拟机,请务必依次修改3台虚拟机的ip地址和主机名称【建议三台主机名称依次叫做:master、node1、node2 】(虚拟机的克隆,前面的博客,三台虚拟机都要开机) 这里我们安装的

准备工作:
安装jdk
克隆2台虚拟机完成后:新的2台虚拟机,请务必依次修改3台虚拟机的ip地址和主机名称【建议三台主机名称依次叫做:master、node1、node2 】(虚拟机的克隆,前面的博客,三台虚拟机都要开机)
这里我们安装的是hadoop2.7.6版本:https://hadoop.apache.org/releases.html
1、设置主机名与ip的映射,修改配置文件命令:vi /etc/hosts
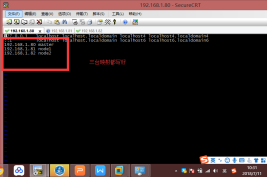
2、将hosts文件拷贝到node1和node2节点
命令:
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
这里我们可以在bin目录下面写一个分发的脚本
cd /bin/
vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in master node1 node2
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本 xsync 具有执行权限:chmod 777 xsync
注意:完成上述操作后,三台需要刷新一下配置环境变量的文件:source /etc/profile
4、关闭防火墙(三台都要操作),使用命令:service iptables stop
5、关闭防火墙的自动启动(三台都要操作),使用命令:chkconfig iptables off
6、设置ssh免密码登录(只在Master 这台主机操作)
主节点执行命令 ssh-keygen -t rsa 产生密钥 一直回车
执行命令
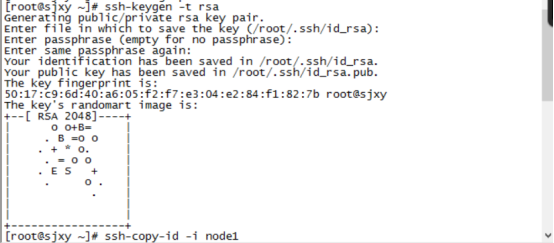
7、将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i node1
ssh-copy-id -i node2
实现免密码登录到子节点。
8、将hadoop的jar包先上传到虚拟机/usr/local/module,使用xftp来上传

9、解压Hadoop
tar -xvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
10、配置环境变量
这是我配置的环境变量,一定要有jdk和Hadoop
vim /etc/profile
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
export Redis_HOME=/usr/local/soft/redis/
export PATH=$PATH:$REDIS_HOME/bin
export HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin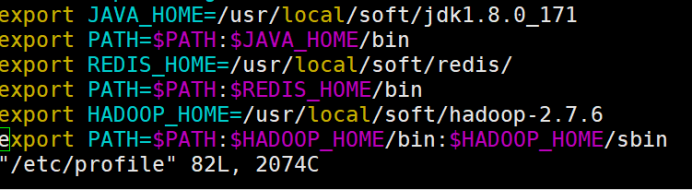
分发给node1与node2:xsync /etc/profile
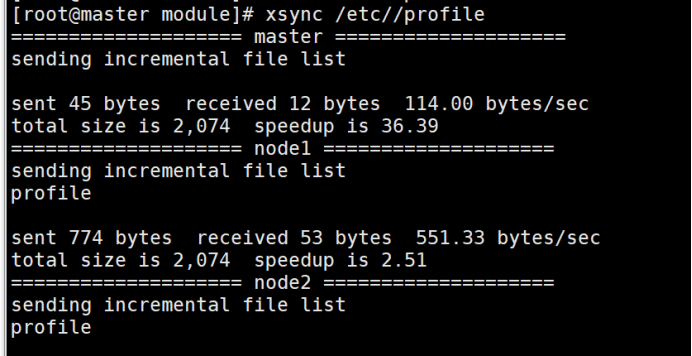
三台都需要:source /etc/profile
11、修改配置文件
hadoop 配置文件在/usr/local/soft/hadoop-2.7.6/etc/hadoop/
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
11.1、hadoop-env.sh : Hadoop 环境配置文件
vim hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

11.2、slaves : 从节点列表(datanode)
vim slaves
增加node1, node2

11.3、core-site.xml : hadoop核心配置文件
vim core-site.xml
在configuration中间增加以下内容
>fs.defaultFS
>hdfs://master:9000
</property>
>
>hadoop.tmp.dir
>/usr/local/soft/hadoop-2.7.6/tmp
</property>
>
>fs.trash.interval
>1440
</property> 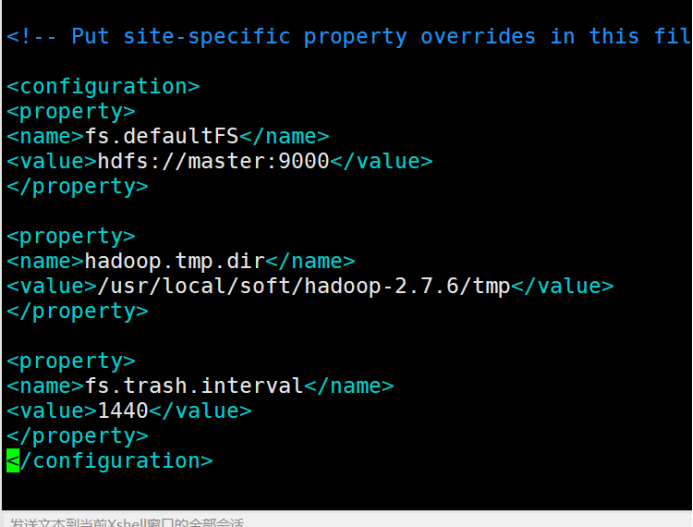
11.4、hdfs-site.xml : hdfs配置文件
vim hdfs-site.xml
在configuration中间增加以下内容
>dfs.replication
>1
</property>
>
>dfs.permissions
>false
</property> 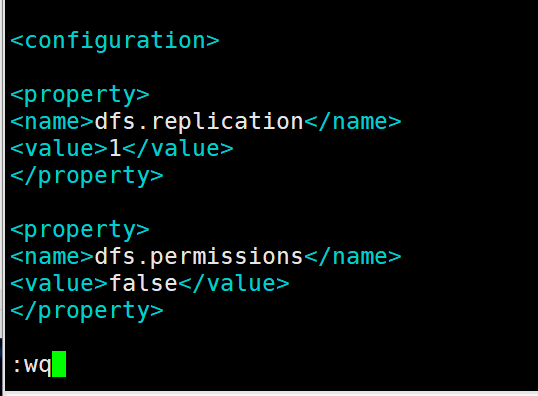
11.5、yarn-site.xml: yarn配置文件
vim yarn-site.xml
在configuration中间增加以下内容
>yarn.resourcemanager.hostname
>master
</property>
>
>yarn.nodemanager.aux-services
>mapReduce_shuffle
</property>
>
>yarn.log-aggregation-enable
>true
</property>
>
>yarn.log-aggregation.retain-seconds
>604800
</property>
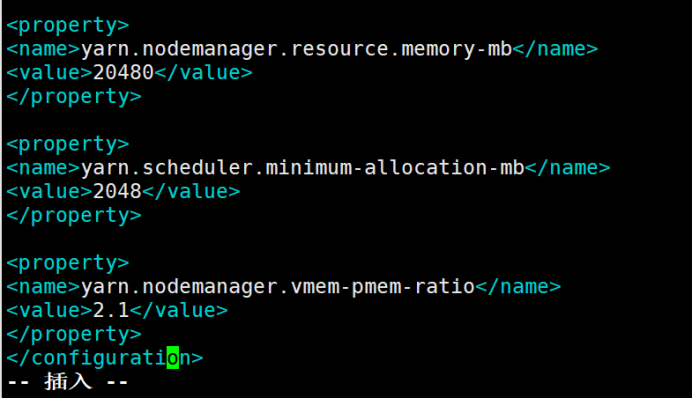
>
>yarn.nodemanager.resource.memory-mb
>20480
</property>
>
>yarn.scheduler.minimum-allocation-mb
>2048
</property>
>
>yarn.nodemanager.vmem-pmem-ratio
>2.1
</property> 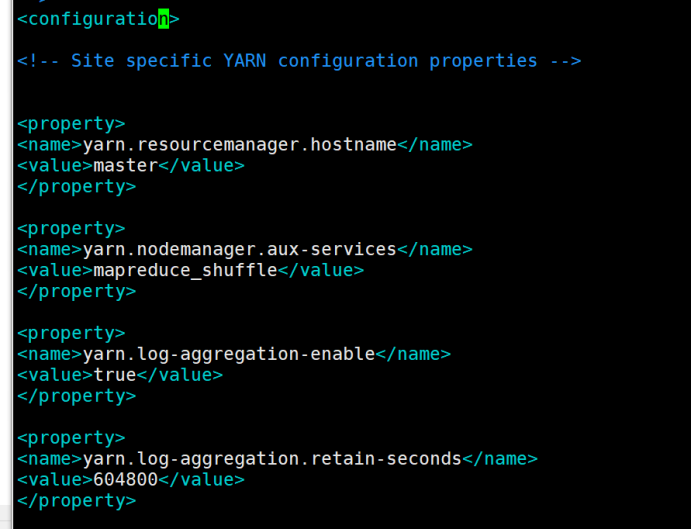
11.6、mapred-site.xml: mapreduce配置文件
在这里需要重命名mapred-site.xml.template
命令:mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在configuration中间增加以下内容
>mapreduce.framework.name
>yarn
</property>
>
>mapreduce.jobhistory.address
>master:10020
</property>
>
>mapreduce.jobhistory.WEBapp.address
>master:19888
</property> 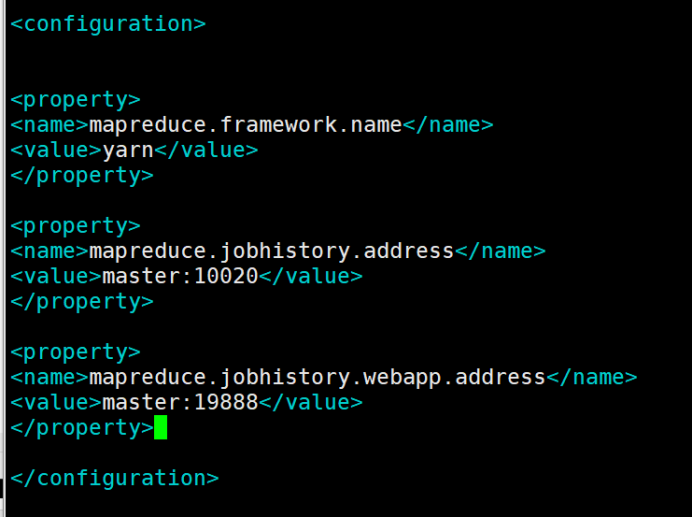
12、将hadoop安装文件同步到子节点
xsync /usr/local/soft/hadoop-2.7.6
13、格式化namenode
hdfs namenode -fORMat
14、启动hadoop
在Hadoop的sbin目录下执行:
/usr/local/soft/hadoop-2.7.6/sbin
启动命令:start-all.sh
15、访问hdfs页面验证是否安装成功
Http://master:50070
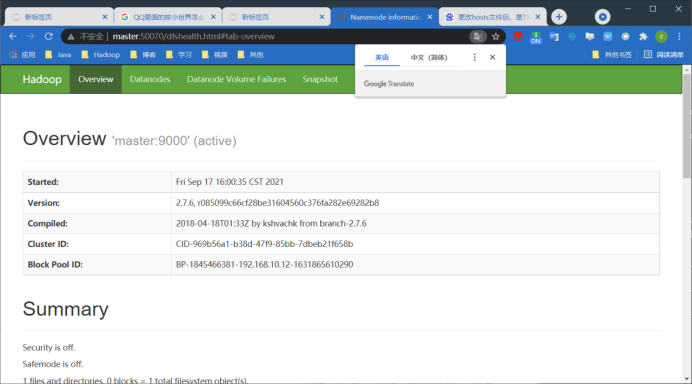
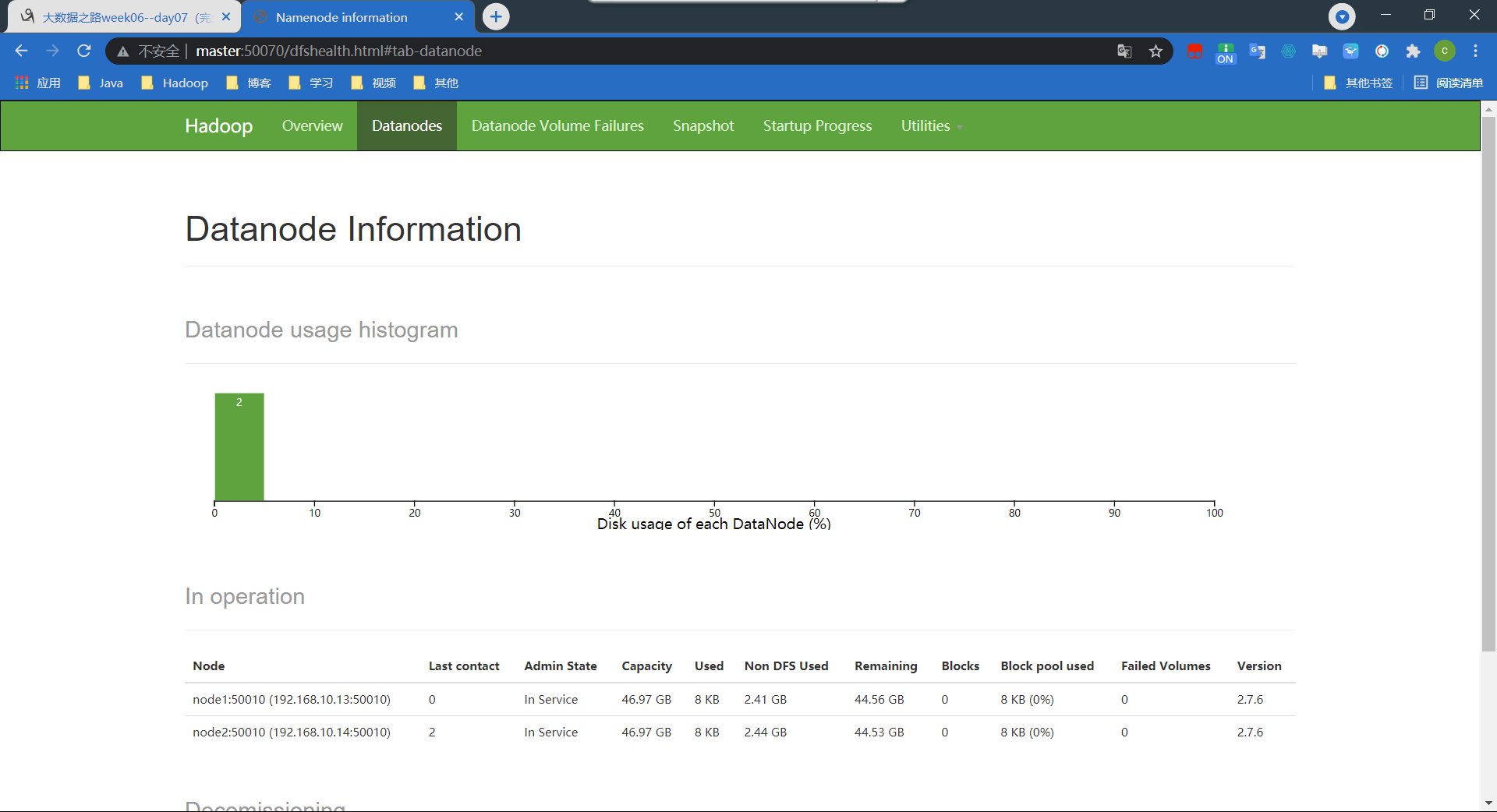
用Java内部命令jps来看是否成功
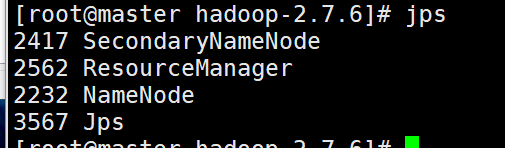

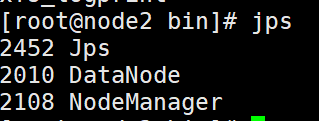
这里同样我们可以使用脚本查看三台节点的jps
在cd /bin/ 目录下 vim jpsall
#!/bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo =============== $i ===============
ssh $i "$*" "/usr/local/soft/jdk1.8.0_212/bin/jps"
done修改脚本 jpsall 具有执行权限:chmod 777 jpsall

16、如果安装失败
stop-all.sh
再次重启的时候
1需要手动将每个节点的tmp目录删除: 所有节点都要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
然后执行将namenode格式化
2在主节点执行命令:
hdfs namenode -format
3启动hadoop
start-all.sh
--结束END--
本文标题: 完全分布式Hadoop2.X的搭建
本文链接: https://lsjlt.com/news/8773.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0