在大数据处理和人工智能时代,数据工厂(Data Factory)无疑是一个非常重要的大数据处理平台。市面上也有成熟的相关产品,比如Azure Data Factory,不仅功能强大,而且依托微软的云计算平台Azure,为大数据处理提供了强
在大数据处理和人工智能时代,数据工厂(Data Factory)无疑是一个非常重要的大数据处理平台。市面上也有成熟的相关产品,比如Azure Data Factory,不仅功能强大,而且依托微软的云计算平台Azure,为大数据处理提供了强大的计算能力,让大数据处理变得更为稳定高效。由于工作中我的项目也与大数据处理相关,于是我就在思考,是否自己也可以设计打造一个数据工厂,以便寻求一些技术痛点的解决方案,并且引入一些有趣的新功能。 因此,我利用业余时间,逐步打造了一个基于spark的数据工厂,并取名为Abacuza(Abacus是中国的“算盘”的意思,隐喻它是一个专门做数据计算的平台,使用“算盘”一词的变体,也算是体现一点中国元素吧)。说是基于Spark,其实从整个架构来看,Abacuza并不一定非要基于Spark,只需要为其定制某种数据处理引擎的插件即可,所以,Spark其实仅仅是Abacuza的一个插件,当然,Spark是目前主流的数据处理引擎,Abacuza将其作为默认的数据处理插件。 Abacuza是开源的,项目地址是:https://GitHub.com/daxnet/abacuza。徒手打造?是的,没错,从前端界面都后端开发,从代码到持续集成,再到部署脚本和SDK与容器镜像的发布,都是自己一步步弄出来的。项目主页上有一个简单的教程,后面我会详细介绍一下。在介绍如何使用Abacuza之前,我们先了解一下它的整体架构和设计思想。虽然目前Abacuza还有很多功能没有完成,但并不影响整个数据处理流程的执行。
Abacuza和其它的数据工厂平台一样,它的业务流程就是分三步走:数据读入、数据处理、结果输出。Abacuza的整体架构图就很清楚地体现了这个业务流程: 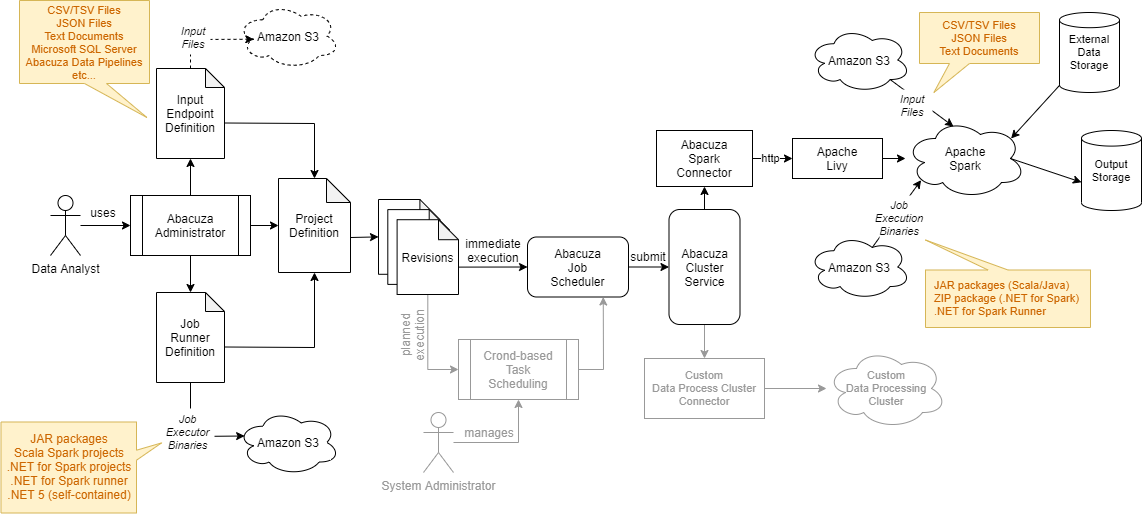
(点击查看大图)
数据的输入是由输入端点(Input Endpoints)来定义的。Abacuza支持多种数据类型的输入:CSV文件、JSON文件、TXT文本文件、Microsoft SQL Server(暂未完全实现)以及S3的对象存储路径,今后还可以继续扩展输入端点,以支持基于管道(Pipeline)的数据处理流程,这样一来,用户就不需要自己使用C#或者Scala来编写数据处理的逻辑代码,只需要一套jsON文件进行Pipeline定义就可以了。
当数据输入已经定义好以后,Abacuza会根据Input Endpoint的设置,将数据读入,然后转交给后端的数据处理集群(Cluster)进行处理。Abacuza可以以插件的形式支持不同类型的集群,如上文所说,Apache Spark是Abacuza所支持的一种数据处理集群,在上面的架构图中可以看到,Abacuza Cluster Service管理这些集群,工作任务调度器(Job Scheduler)会通过Abacuza Cluster Service将数据处理任务分配到指定类型的集群上进行处理。 对于Spark而言,具体的数据处理逻辑是由用户自己编写代码实现的。Spark原生支持Scala,也可以使用PySpark,Abacuza使用Microsoft .net for Spark项目实现从.NET到Spark的绑定(Binding),用户可以使用C#来编写Spark的数据处理逻辑,后面的演练部分我会详细介绍。 那么与Scala相比,通过.NET for Spark使用C#编写的数据处理程序会不会有性能问题?嗯,会有点性能问题,请看下图(图片来源:微软.NET for Spark官方网站): 
在这个Benchmark中,处理相同总量的数据,Scala使用了375秒,.NET花了406秒,python使用433秒,虽然与Scala相比有些差距,但是比Python要好一些。但是不用担心,如果在你的应用场景中,性能是放在第一位的,那么Abacuza的Job Runner机制允许你使用Scala编写数据处理程序,然后上传到Spark集群执行(也就是你不需要依赖于.NET和C#)。
与数据输入部分类似,处理之后的数据输出方式是由输出端点(Output Endpoints)来定义的。Abacuza也支持多种数据输出方式:将结果打印到日志、将结果输出到外部文件系统以及将结果输出到当前项目所在的S3对象存储路径。无论是数据输入部分还是输出部分,这些端点都是可以定制的,并且可以通过ASP.net core的插件系统以及Docker-compose或者kubernetes的volume/Block Storage来实现动态加载。
Abacuza有以下这些概念:
当一个用户准备使用Abacuza完成一次大数据处理的任务时,一般会按照下面的步骤进行:
Abacuza采用微服务架构风格,每个单独的微服务都在容器中运行,目前实验阶段采用docker-compose进行容器编排,今后会加入Kubernetes支持。现将Abacuza所使用的框架与相关技术简单罗列一下:
弱弱补一句:本人前端技术没有后端技术精湛,所以前端页面会有不少问题,样式也不是那么的专业美观,前端高手请忽略这些细节。;) Abacuza采用了插件化的设计,用户可以根据需要扩展下面这些组件:
在Abacuza的管理界面中,可以很方便地看到目前系统中已经被加载的插件:  因此,Abacuza数据工厂应该可以满足绝大部分大数据处理的业务场景。本身整个平台都是基于.NET开发,并且通过NuGet分发了Abacuza SDK,因此扩展这些组件是非常简单的,后面的演练部分可以看到详细介绍。
因此,Abacuza数据工厂应该可以满足绝大部分大数据处理的业务场景。本身整个平台都是基于.NET开发,并且通过NuGet分发了Abacuza SDK,因此扩展这些组件是非常简单的,后面的演练部分可以看到详细介绍。
以下是Abacuza的部署拓扑: 
(点击查看大图)
整个部署结构还是比较简单的:5个主要的微服务由基于Ocelot实现的API Gateway负责代理,Ocelot可以整合IdentityServer4,在Gateway的层面完成用户的认证(Gateway层面的授权暂未实现)。基于IdentityServer4实现的Identity Service并没有部署在API Gateway的后端,因为在这个架构中,它的认证授权策略与一般的微服务不同。API Gateway、Identity Service以及基于Angular实现的web app都由nginx反向代理,向外界(客户端浏览器)提供统一的访问端点。所有的后端服务都运行在docker里,并可以部署在Kubernetes中。
Word Count是Spark官方推荐的第一个案例程序,它的任务是统计输入文件中每个单词的出现次数。.NET for Spark也有一个相同的Word Count案例。在此,我仍然使用Word Count案例,介绍如何在Abacuza上运行数据处理程序。
你需要一台windows、MacOS或者linux的计算机,上面装有.NET 5 SDK、docker以及docker-compose(如果是Windows或者MacOS,则安装docker的桌面版),同时确保安装了git客户端命令行。
首先使用dotnet命令行创建一个控制台应用程序,然后添加相关的引用:
$ dotnet new console -f net5.0 -n WordCountApp
$ cd WordCountApp
$ dotnet add package Microsoft.Spark --version 1.0.0
$ dotnet add package Abacuza.JobRunners.Spark.SDK --prerelease
然后在项目中新加入一个class文件,实现一个WordCountRunner类:
using Abacuza.JobRunners.Spark.SDK;
using Microsoft.Spark.Sql;
namespace WordCountApp
{
public class WordCountRunner : SparkRunnerBase
{
public WordCountRunner(string[] args) : base(args)
{
}
protected override DataFrame RunInternal(SparkSession sparkSession, DataFrame dataFrame)
=> dataFrame
.Select(Functions.Split(Functions.Col("value"), " ").Alias("words"))
.Select(Functions.Explode(Functions.Col("words"))
.Alias("word"))
.GroupBy("word")
.Count()
.OrderBy(Functions.Col("count").Desc());
}
}
接下来修改Program.cs文件,在Main函数中调用WordCountRunner:
static void Main(string[] args)
{
new WordCountRunner(args).Run();
}
然后,在命令行中,WordCountApp.csproj所在的目录下,使用下面的命令来生成基于Linux x64平台的编译输出:
$ dotnet publish -c Release -f net5.0 -r linux-x64 -o published
最后,使用ZIP工具,将published下的所有文件(不包括published目录本身)全部打包成一个ZIP压缩包。例如,在Linux下,可以使用下面的命令将published目录下的所有文件打成一个ZIP包:
$ zip -rj WordCountApp.zip published/.
Word Count程序已经写好了,接下来我们就启动Abacuza,并在其中运行这个WordCountApp。
你可以使用git clone Https://github.com/daxnet/abacuza.git命令,将Abacuza源代码下载到本地,然后在Abacuza的根目录下,使用下面的命令进行编译:
$ docker-compose -f docker-compose.build.yaml build
编译成功之后,用文本编辑器编辑template.env文件,在里面设置好本机的IP地址(不能使用localhost或者127.0.0.1,因为在容器环境中,localhost和127.0.0.1表示当前容器本身,而不是运行容器的主机),端口号可以默认:

然后,使用下面的命令启动Abacuza:
$ docker-compose --env-file template.env up
启动成功后,可以使用docker ps命令查看正在运行的容器: 
用浏览器访问http://<你的IP地址>:9320,即可打开Abacuza登录界面,输入用户名super,密码P@ssw0rd完成登录,进入Dashboard(目前Dashboard还未完成)。然后在左侧菜单中,点击Cluster Connections,然后点击右上角的Add Connection按钮:

在弹出的对话框中,输入集群连接的名称和描述,集群类型选择spark,在设置栏中,输入用于连接Spark集群的JSON配置信息。由于我们本地启动的Spark在容器中,直接使用本机的IP地址即可,如果你的Spark集群部署在其它机器上,也可以使用其它的IP地址。在配置完这些信息后,点击Save按钮保存:

接下来就是创建任务执行器。在Abacuza管理界面,点击左边的Job Runners菜单,然后点击右上角的Add Job Runner按钮: 
在弹出的对话框中,输入任务执行器的名称和描述信息,集群类型选择spark,之后当该任务执行器开始执行时,会挑选任意一个类型为spark的集群来处理数据。 
填入这些基本信息后,点击Save按钮,此时会进入任务执行器的详细页面,用来进行进一步的设置。在Payload template中,输入以下JSON文本:
{
"file": "${jr:binaries:microsoft-spark-3-0_2.12-1.0.0.jar}",
"className": "org.apache.spark.deploy.dotnet.DotnetRunner",
"args": [
"${jr:binaries:WordCountApp.zip}",
"WordCountApp",
"${proj:input-defs}",
"${proj:output-defs}",
"${proj:context}"
]
}
大概介绍一下每个参数:
在上面的配置中,引用了两个binary文件:microsoft-spark-3-0_2.12-1.0.0.jar和WordCountApp.zip。于是,我们需要将这两个文件上传到任务执行器中。仍然在任务执行器的编辑界面,在Binaries列表中,点击加号按钮,将这两个文件附加到任务执行器上。注意:microsoft-spark-3-0_2.12-1.0.0.jar文件位于上文用到的published目录中,而WordCountApp.zip则是在上文中生成的ZIP压缩包。

配置完成后,点击Save & Close按钮,保存任务执行器。 接下来,创建一个数据处理项目,在左边的菜单中,点击Projects,然后在右上角点击Add Project按钮: 
在弹出的Add Project对话框中,输入项目的名称、描述,然后选择输入端点和输出端点,以及负责处理该项目数据的任务执行器:

在此,我们将输入端点设置为文本文件(Text Files),输出端点设置为控制台(Console),也就是直接输出到日志中。这些配置在后续的项目编辑页面中也是可以更改的。一个项目可以包含多个输入端点,但是只能有一个输出端点。点击Save按钮保存设置,此时Abacuza会打开项目的详细页,在INPUT选项卡下,添加需要统计单词出现次数的文本文件: 
在OUTPUT选项卡下,确认输出端点设置为Console:

然后点击右上角或者右下角的Submit按钮,提交数据处理任务,此时,选项卡会自动切换到REVISIONS,并且更新Job的状态: 
稍等片刻,如果数据处理成功,Job Status会从RUNNING变为COMPLETED:

点击Actions栏中的文件按钮,即可查看数据处理的日志输出:

从日志文件中可以看到,Abacuza已经根据我们写的数据处理程序,统计出输入文件input.txt中每个单词的出现次数。通过容器的日志输出也能看到同样的信息: 
本文介绍了自己纯手工打造的数据工厂(Data Factory)的设计与实现,并开发了一个案例来演示该数据工厂完成数据处理的整个过程。之后还有很多功能可以完善:Dashboard、认证授权的优化、用户与组的管理、第三方IdP的集成、Pipeline的实现等等,今后有空再慢慢弄吧。
欢迎访问本人的个人站点https://sunnycoding.cn,获得更好的阅读体验。
--结束END--
本文标题: 徒手打造基于Spark的数据工厂(Data Factory):从设计到实现
本文链接: https://lsjlt.com/news/8702.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0