我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟! 囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点!!! 本期主要面试考点 面试官考点之什么情况下会索引失效? 本期验证以下索引失效

我是肥哥,一名不专业的面试官!
我是囧囧,一名积极找工作的小菜鸟!
囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点!!!
本期主要面试考点
面试官考点之什么情况下会索引失效?
本期验证以下索引失效的常见场景
like通配符,左侧开放情况下,全表扫描
2、or条件筛选,可能会导致索引失效
3、where中对索引列使用Mysql的内置函数,一定失效
4、where中对索引列进行运算(如,+、-、*、/),一定失效
5、类型不一致,隐式的类型转换,导致的索引失效
6、where语句中索引列使用了负向查询,可能会导致索引失效。负向查询包括:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,其中:!< !> sqlServer语法。
7、索引字段可以为null,使用is null或is not null时,可能会导致索引失效
8、隐式字符编码转换导致的索引失效
9、联合索引中,where中索引列违背最左匹配原则,一定会导致索引失效
10、mysql优化器的最终选择,不走索引


准备数据表,同时建立普通索引 idx_user_name
CREATE TABLE `t_user` (
`id` int(11) NOT NULL,
`user_name` varchar(32) CHARACTER DEFAULT NULL COMMENT "用户名",
`address` varchar(255) CHARACTER DEFAULT NULL COMMENT "地址",
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT "创建时间",
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入1万条数据(注意:数据多些,mysql不走索引情况之一是数据量非常少,MySQL查询优化器认为全表扫描比使用索引更快,导致索引失效,explain检查是否使用索引时,发现无法走索引)
-- 创建存储过程,插入10000用户信息
CREATE PROCEDURE user_insert()
-- 定义存储过程开始
BEGIN
-- 定义变量 i ,int 类型,默认值为 1
DECLARE i INT DEFAULT 1;
WHILE i <= 10000
-- 定义循环内执行命令
DO INSERT INTO t_user(id, user_name, address, create_time) VALUES(i, CONCAT("mayun", i), CONCAT("浙江杭州", i), now());
SET i=i+1;
END WHILE;
COMMIT;
END;
-- 定义存储过程结束
-- 调用存储工程
CALL user_insert();
好多人说where条件中使用 or ,那么索引一定失效,是否正确?
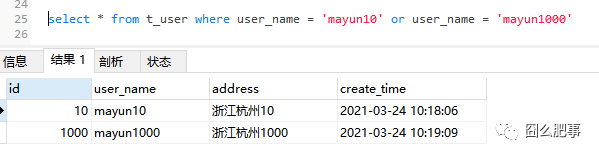
OR 连接的是同一个字段,相同走索引
explain select * from t_user where user_name = "mayun10" or user_name = "mayun1000"

OR 连接的是两个不同字段,不同索引失效
explain select * from t_user where user_name = "mayun10" or address = "浙江杭州12"

给address列增加索引
alter table t_user add index idx_address (address)
OR 连接的是两个不同字段,如果两个字段皆有索引,走索引

验证总结
or 可能会导致索引失效,并非一定,这里涉及到MySQL index merge 技术。
MySQL5.0之前,查询时一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。
但是从5.1开始,MySQL引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。然后将它们各自的结果进行合并(intersect/uNIOn)。
or索引生效有哪些情况?
第一种 or两边连接的是同一个索引字段
第二种 or两边连接的是两个索引字段,即两个字段分别都建立了索引
一个最常见的查询场景,建立idx_user_name索引
select * from t_user where user_name like "%mayun100%";
这条查询是否走索引?

select * from t_user where user_name like "mayun100%";
这条查询是否走索引?

验证总结
like 通配符特性是可以左右开闭匹配查询当左边开放使用 % 或者 _ 匹配的时候都不会走索引,会进行全表扫描
为什么左开情况下会索引失效?请介绍一下原理!
我们知道建立索引后,MySQL会建立一棵有序的B+Tree,索引树是有序的,索引列进行查询匹配时是从左到右进行匹配。使用 % 和 _ 匹配,这表示左边匹配值是不确定的。不确定,意味着充满可能,怎么比较?
当然只能一个一个的比较,那就相当于,全匹配了,全匹配在优化器看来,与其走索引树查询,再进行不断的回表操作,还不如直接进行全表扫描划算!
建立 idx_age 索引,
alter table t_user add index idx_age(age);
不使用内置函数
explain select * from t_user where age = 80

使用内置函数
explain select * from t_user where abs(age) = 80

验证总结
如果对索引字段做了函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
MySQL 无法再使用索引快速定位功能,而只能使用全索引扫描。
不涉及索引列的运算
alter table t_user add index idx_age(age);explain select * from t_user where age = 80;
索引列进行运算操作
explain select * from t_user where age + 5 = 80

alter table t_user add index idx_user_name(user_name);explain select * from t_user where user_name = "mayun1";

修改数据,再次explain
update t_user set user_name = "100" where user_name = "mayun1";explain select * from t_user where user_name = 100;
user_name = 100 ,因为user_name 字段定义的是varchar,索引在where进行匹配时会先隐式调用 case() 函数进行类型转换 将匹配条件变成,user_name = "100"

负向查询包括:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,其中:!< !> SQLServer语法。
alter table t_user add index idx_age(age);explain select * from t_user where age in (100, 50);

explain select * from t_user where age not in (100, 50);

第一种情况,表结构规定允许user_name 字段可以为null

explain select * from t_user where user_name is null;

explain select * from t_user where user_name is not null;

第二种情况,表结构规定user_name 字段不可以为null

explain select * from t_user where user_name is null;

explain select * from t_user where user_name is not null;

当两个表进行连接JOIN 时,如果两张表的字符编码不同,可能会导致索引失效。
这个索引失效场景尚未遇到,网上很多文章说会导致索引失效,查阅发现大量的博客说UTF8mb4字符集的表mb4与UTF8字符集的表utf8 关联会产生索引失效的问题,但是我根据大量博文所述操作,发现暂时还是无法复现,读者可自行查阅。
如果读者复现到此场景,欢迎评论讨论或关注如果读者复现到此场景,欢迎评论或关注公众号
囧么肥事讨论
创建联合做引 idx_user_name_deposit, 遵循最左匹配原则
alter table t_user add index idx_user_name_deposit(user_name, deposit);explain select * from t_user where user_name like "mayun86%"

遵循最左匹配之 a b 类型
explain select * from t_user where user_name like "mayun86%" and deposit = 5620.26;

调换索引位置,测试联合索引书写规则
explain select * from t_user where deposit = 5620.26 and user_name like "mayun86%";

违反最左匹配原则
explain select * from t_user where deposit = 5620.26;

验证总结
联合索引依据最左匹配原则建立索引树,在查询时依据联合索引顺序依次匹配索引值,查询时如果违背最左匹配原则,将导致索引失效。
假设建立索引 idx_a_b_c,相当于建立了 (a), (a,b), (a,b,c)三个索引查询匹配时匹配顺序是 a b c 查询时如果没有 a 字段筛选,那么索引将失效
举栗子,走索引情况
select * from test where a=1 select * from test where a=1 and b=2 select * from test where a=1 and b=2 and c=3
索引失效呢?
select * from test where b=2 and c=3
联合索引如果要走索引,查询条件中必须要包含第一个索引,否则索引失效
select * from test where b=1 and a=1select * from test where m="222" and a=1
这两条查询走索引的原因是什么?
最左前缀指的是查询时匹配索引列要按照联合索引创建的顺序,但是在书写时不需要严格按照联合索引创建的顺序,MySQL优化器会自动调整,所以上面两条查询索引有效!
explain select * from t_user where age > 59;

explain select * from t_user where age > 99;

验证总结
MySQL查询索引失效的情况有很多,即使其他情况都规避,但是在经过了优化器的确定查询方案的时候,依然可能索引失效。
优化器会考虑查询成本,来确认它认为的最佳方案来执行查询
当数据量较少,或者需要访问行很多的时候
优化器会认为走索引树来进行回表,还不如直接进行全表扫描的时候,优化器将会抛弃走索引树。
随缘更新,大神请绕路!
更多精彩内容,欢迎关注微信公众号:囧么肥事 (或搜索:jiongmefeishi)

--结束END--
本文标题: 《MySQL面试小抄》索引失效场景验证
本文链接: https://lsjlt.com/news/8530.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0