本篇内容介绍了“怎么使用Tarjan算法求解强连通分量”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!算法框
本篇内容介绍了“怎么使用Tarjan算法求解强连通分量”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
算法框架
我们来思考一个问题,对于强连通分量分解的算法来说,它的核心原理是什么?
如果你看过我们之前的文章,那么这个问题对你来说应该不难回答。既然是强连通分量,意味着分量当中每个点都可以互相连通。所以我们很容易可以想到,我们可以从一个点出发,找到一个回路让它再回到起点。这样途中经过的点就都是强连通分量的一部分。
但是这样会有一个问题,就是需要保证强连通分量当中的每个点都被遍历到,不能有遗漏。针对这个问题我们也可以想到解法,比如可以用搜索算法去搜索它所有能够达到的点和所有的路径。但是这样一来,我们又会遇到另外一个问题。这个问题就是强连通分量之间的连通问题。
我们来看个例子:
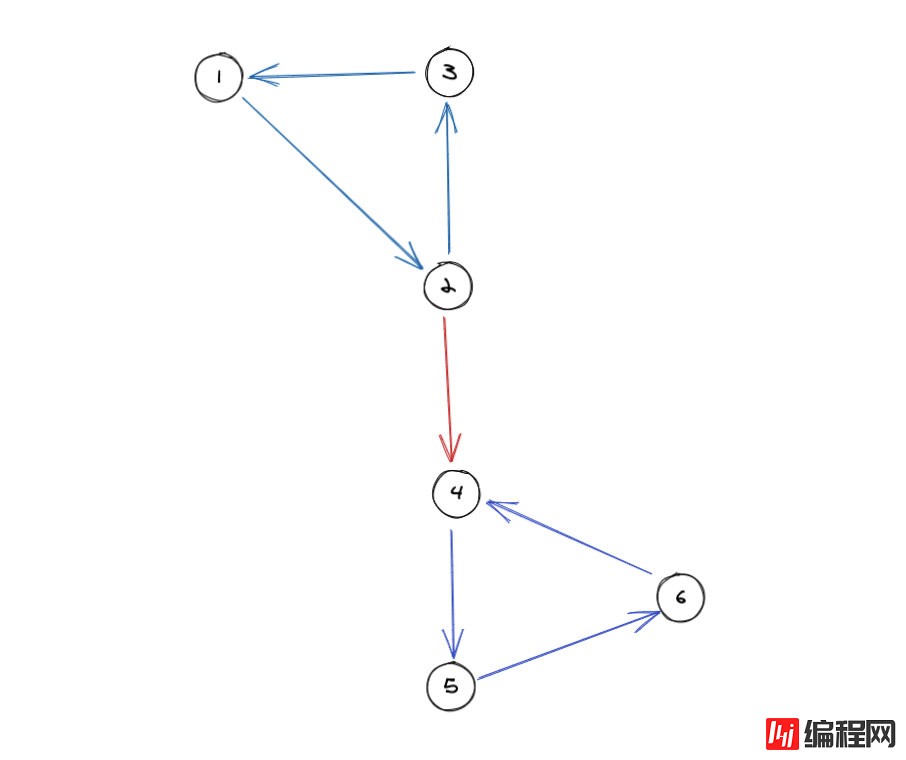
在上面这张图当中如果我们从点1出发,我们可以达到图中的每一个点。但是我们会发现1,2,3是一个强连通分量,4,5,6是另外一个。当我们寻找1所在的强连通分量的时候,很有可能会把4,5,6这三个点也带进来。但问题是它们是自成分量的,并不应该算在1的强连通分量当中。
我们整理一下上面的分析和思路可以发现强连通分量分解这个算法的核心其实就是解决这两个问题,就是完备性问题。完备意味着不能遗漏也不能冗余和错误,我们想明白核心问题所在之后就很容易搭建起思维框架,接下来我们再来看算法的描述会容易理解得多。
算法细节
Tarjan算法的第一个机制是时间戳,也就是在遍历的时候对每一个遍历到的点打上一个值。这个值表示这是第几个遍历的元素。
这个应该很好理解,我们只需要维护一个全局的变量,在遍历的时候去让它自增就可以了。我们来写下python代码给大家演示一下:
stamp = 0 stamp_dict = {}def dfs(u): stamp_dict[u] = stamp stamp += 1 for v in Graph[u]: dfs(v)通过时间戳我们可以知道每个点被访问的顺序,这个顺序是正向顺序。举个例子,比如说假设u和v两个点,u的时间戳比v小。那么它们之间的关系只有两种可能,第一种是u能够连通到v,说明从u到v的链路可以走通。第二种是u不能连通到v,这种情况不论反向的从v到u能否连通都不具有讨论意义,因为它们一定不能互相连通。
所以我们想要找到连通的通路还需要找到反向的路径,在Kosaraju算法当中我们是通过反向图来实现的。在Tarjan当中则采取了另外一种方法。因为我们已经知道各个点的时间戳了,我们完全可以通过时间戳来寻找反向的路径。什么意思呢?其实很简单,当我们在遍历u的时候如果遇到了一个比u时间戳更小的v,那么说明就存在一条反向的路径从u通向v。如果v这时候还没有出栈,意味着v是u的上游的话,那么也就说明存在一条路径从v通向u。这样就说明了u和v可以互相连通。
既然找到了一对互相连通的u和v,那么我们需要把它们记录下来。但问题是我们怎么知道记录到什么时候为止呢?这个边界在哪里?Tarjan算法设计了另外一个巧妙的机制解决了这个问题。
这个机制就是low机制,low[u]表示u这个点能够连通到的所有的点的时间戳的最小值。时间戳越小说明在搜索树当中的位置越高,也可以理解成u能够连通到的处在搜索树中最高的点。那么很明显了,这个点就是u这个点所在强连通分量所在搜索树某一棵子树的树根。
这里可能有一点点绕,我们再来看张图:
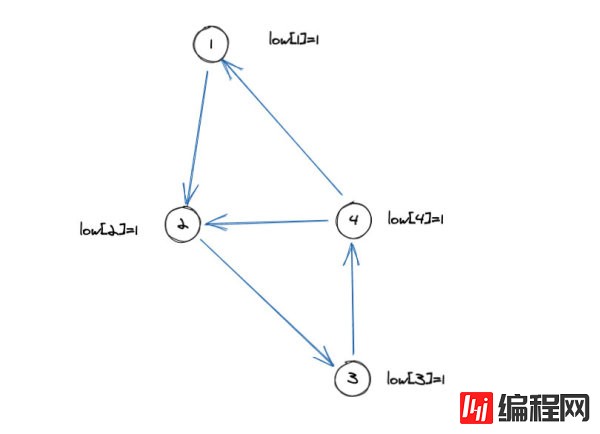
图中节点所在的序号就是递归遍历的时间戳,我们可以发现对于图上的每个点来说它们的low值都是1。很明显1这个点在搜索树当中是2,3,4这三个点的祖先。也就是说这一个强连通分量的遍历是从1这个点开始的。当1这个点出栈的时候,意味着以1位树根的子树已经遍历完了,所有可能存在的强连通分量也都已经找完了。
这就带来了另外一个问题,我们假设当前点是u,我们如何知道u这个点是否是图中1这样的树根呢?有没有什么办法可以标记出来呢?
当然是有的,这样的点有一个特性就是它们的时间戳等于它们的low。所以我们可以用一个数组维护找到的强连通分量,当这些强连通分量能够遍历到的树根出栈的时候,把数组清空。
我们把上面的逻辑整理一下就可以写出代码来了:
scc = [] stack = [] def tarjan(u): dfn[u], low[u] = stamp, stamp stamp += 1 stack.append(u) for v in Graph[u]: if not dfn[v]: tarjan(v) low[u] = min(low[u], low[v]) elif v in stack: low[u] = min(low[u], dfn[v]) if dfn[u] == low[u]: cur = [] # 栈中u之后的元素是一个完整的强连通分量 while True: cur.append(stack[-1]) stack.pop() if cur[-1] == u: break scc.append(cur)最后,我们来看一下之前讲过的经典例子:
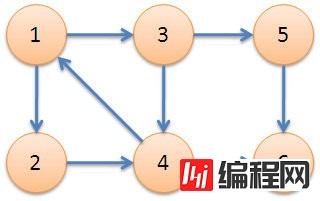
首先我们从1点开始,一直深搜到6结束,当遍历到6的时候,DFN[6]=4,low[6]=4,当6出栈时满足条件,6独立称为一个强连通分量。
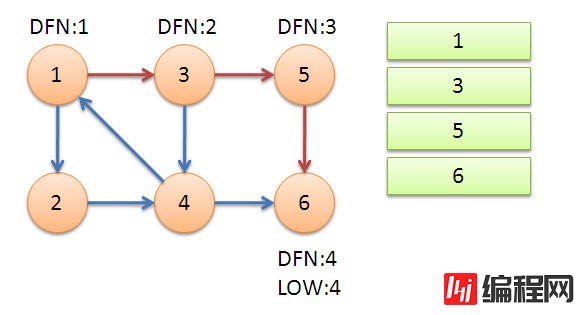
同理,当5退出的时候也同样满足条件,我们得到了第二个强连通分量。
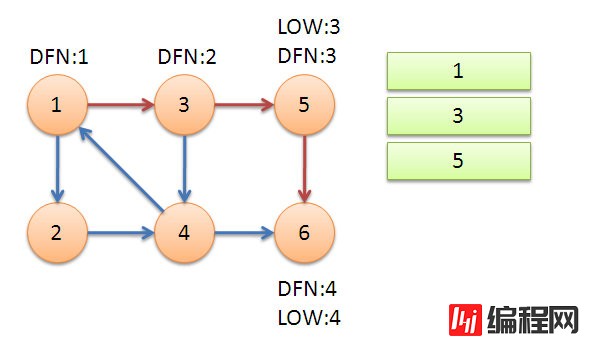
接着我们回溯到节点3,节点3还可以遍历到节点4,4又可以连向1。由于1点已经在栈中,所以不会继续递归1点,只会更新low[4] = 1,同样当4退出的时候又会更新3,使得low[3] = 1。
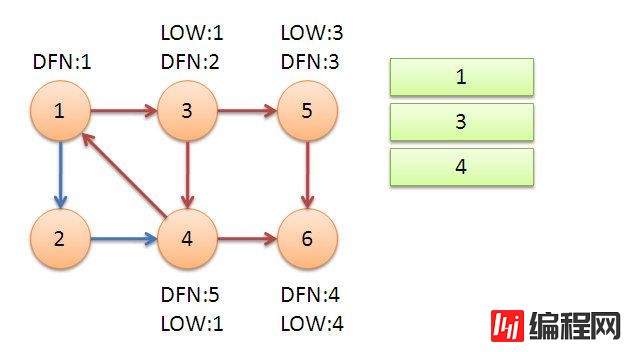
最后我们返回节点1,通过节点1遍历到节点2。2能连通的4点已经在栈中,并且DFN[4] > DFN[2],所以并不会更新2点。再次回到1点之后,1点没有其他点可以连通,退出。退出的时候发现low[1] = DFN[1],此时栈中剩下的4个元素全部都是强连通分量。
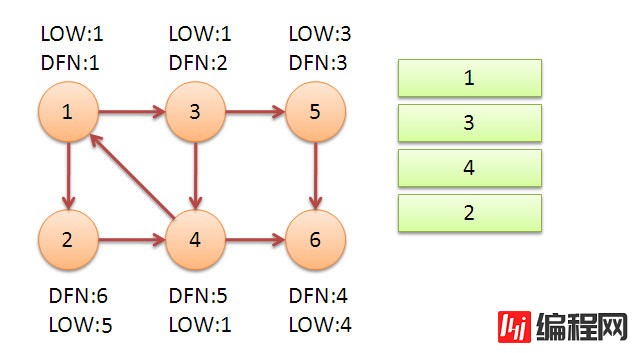
“怎么使用Tarjan算法求解强连通分量”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!
--结束END--
本文标题: 怎么使用Tarjan算法求解强连通分量
本文链接: https://lsjlt.com/news/84586.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-01-12
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0