这篇文章主要介绍“如何理解Go编译器代码优化bug定位和修复”,在日常操作中,相信很多人在如何理解Go编译器代码优化bug定位和修复问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解
这篇文章主要介绍“如何理解Go编译器代码优化bug定位和修复”,在日常操作中,相信很多人在如何理解Go编译器代码优化bug定位和修复问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何理解Go编译器代码优化bug定位和修复”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
缘起
某日,一位友人在群里招呼我,“看到有人给 Go 提了个编译器的 bug,挺有意思,感觉还挺严重的,要不要来看看?”于是我打开了 issue 40367[1] 。彼时,最新一条评论是 这条[2] :

提到将循环体中的一个常数从 1 改成 2 就无法复现问题,这顿时勾起了我的兴趣,于是我准备研究一番。
bug 代码跟现象如下图,正常来看,代码应该在输出 "5 6" 后停止,然而实际上却无限执行了下去,只能强行终止或等待程序触碰到无权限内存地址之后崩溃。

首先,我们要定位到这个问题具体的直接原因。简单来说,这个 bug 是 for-range loop 越界,原本循环应该在循环次数到达数组长度后终止,但是这个复现程序中的循环无限执行了下去。乍一看,问题像是有 bound check 被优化掉了,那么我们来实锤一下。有一个方便的网站,可以在线观察给定程序编译产出的汇编结果,我用 这个网站[3] 分别生成了原复现程序和将第六行的 +1 改为 +2 后不复现程序的汇编,供大家对比。抛开无关细节不提,可以很容易地看到前者的汇编相较于后者的确少了一次判断,导致循环无法终止,具体的位置是第二段代码的 105 行:

既然直接原因已经定位到了,那接下来我们就要想办法追进编译器来查看为什么汇编结果有问题了。对很多同学来说,追进编译器查问题的过程可能比较陌生,听起来就令人望而却步,那么我们如何来排查这个问题呢?
背景知识
在追踪这个具体问题之前,我们需要先了解一些相关知识背景。
Go 编译器的大体运行流程
想要追查 Go 编译器的问题,首先就需要了解 Go 编译器的大致运行流程。其实 Go 的编译器的实现中规中矩,相比于 GCC/Clang 等老牌编译器甚至有些简陋,许多优化并未实现。一个 Go 程序在生成汇编前的工作大概分为这几步:
语法解析。由于 Go 语言语法相当简单,所以 Go 编译器使用的是一个手写的 LALR (1) 解析器,这部分跟今天的 bug 无关,细节略过不提。
类型检查。Go 是强类型静态类型语言,在编译期会对赋值、函数调用等过程做类型检查,判断程序是否合法。另外,这个步骤会将一些 Go 自带的泛型函数变换成具体类型的函数调用,比方说 make 函数,在类型检查阶段会根据类型检查的结果变换成具体的 makeslice/makemap 等。这部分也跟今天的 bug 无关。
中间代码 (IR)生成。为方便做跨平台代码生成,也为方便做编译优化,现代编译器通常会将语法树变成一个中间代码表示形式,这个表示形式的抽象程度通常是介于语法树和平台汇编之间。Go 选择的是一种静态单赋值 (SSA)形式的中间代码。这部分较为重要,接下来一个小节会展开详述一下。
编译优化。在生成了 SSA IR 之后,编译器会基于这个 IR 跑很多趟(pass)代码分析和改写,每个 pass 会完成一个优化策略。另外值得一提的是,Go 中很多强度削减类的策略是使用一种 DSL 描述,然后代码生成出实际的 pass 代码来的,不过这块跟今天内容没什么关系,感兴趣的同学可以下来看看。在文章的后续内容中,我们就会定位到导致本文中这个 bug 的具体的 pass,并看到那个 pass 中有问题的逻辑。
这几步之后,编译器就已经准备好生成最终的平台汇编代码了。
静态单赋值形式
静态单赋值的含义是,在这种类型的 IR 中,每一个变量只会被赋值一次。这种形式的好处我们不再赘述,仅以一段简单的 Go 代码作为实例帮助大家理解 SSA IR 的含义。
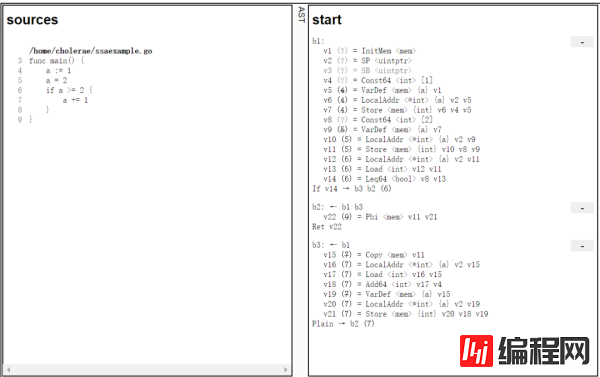
这里是一个简单的例子,右侧是 Go 代码所对应的 SSA IR。可以看到,整个代码被切分成了多块,每个代码块 (block)的代码以 bXX 作为开头,另外在缩进所对应的结尾能够看到这个 block 会跳转到哪个 block。在 block 内部,可以看到包括常量在内的每个值都会有一个单独的名字,比如变量 a 在 Go 代码的 4、5 行的两次赋值,在 SSA IR 中对应了 v7 和 v11 两个值。
但是,如果是代码中包含了 if 等语句,在编译时不能确定需要使用哪个值,在 SSA IR 中如何表示呢?例子中正好有这样的代码,可以看到 Go 代码中第六行的 if。实际上,SSA IR 中有一个专门的 phi 操作符,就是为了这种情况设计,phi 操作符的含义是,返回值可能是参数的多个值中的任意一个,但是具体究竟是哪个值,需要取决于这个 block 此次运行是从哪个 block 跳转而来。在上图中,可以看到 b2 就有一个 phi 运算符,v22 可能等于 v11 或 v21,具体等于哪个值需要看 b2 的上一个块究竟是 b1 还是 b3,实际上就对应了 if 条件的成立或不成立。当然,这个例子中 if 显然成立,只不过我们这里看到的 SSA IR 是未经过优化的 IR,在实际的编译过程中,这里会被优化掉。
Go 编译器提供了非常方便的功能,可以查看各个优化 pass 前后的 SSA IR,只需要在编译时,增加一个 GOSSAFUNC=xxx 环境变量即可,xxx 即为想要分析的函数的名字,因为 Go 编译器内部的优化都是函数级别的。比如上图的例子,只需要运行 GOSSAFUNC=main go build ssaexample.go,编译器就会将 SSA IR 结果输出到当前目录的 ssa.html 中,用浏览器打开即可。
排查过程
追查出问题的优化策略
了解了这么多前置知识,我们终于可以来追查这个具体的 bug 成因了。第一步,我们要首先通过 Go 编译器 dump 出来的 SSA IR,查看究竟是哪一个 pass 出了问题。用上一节中讲到的方式,我们可以观察 issue 中的复现程序的所有 SSA IR。由于 Go 编译器的优化 pass 不少,所以在 ssa.html 中记录了大量的 SSA IR,我们如何找到有问题的 pass 呢。对于我个人来说,由于我之前有所了解,能够大致猜到这种问题是 prove pass 的 bug。但是即使大家没有相关背景,由于我们已经知道这个 bug 的直接原因是少了一条比较判断,所以也可以通过二分法查看哪个 pass 少了一条比较指令来进行定位。需要注意的是,大家可能会定位到 generic deadcode pass,因为这个 pass 中少了一条 Less64 指令,如图(我这里使用的是 Go 1.15rc1,具体输出与编译器版本相关,可能有所不同),右侧是 generic deadcode pass:

可以看到相比于左侧,右侧中 b4 里的 Less64 消失了,再观察这条 Less64 的参数,v11 就是常量 6,也即代码中数组的长度,可以确定这条指令就是那个消失的边界判断。那么我们是否可以确定 bug 出在 generic deadcode pass 呢?并不能。因为这个 pass 只是把前面 pass 中已经变成死代码的部分删除掉,实际上这行 Less64 在前面已经变成死代码了,从左侧这条指令的浅灰色可以看出来,也就是说 generic deadcode pass 其实是背锅的。不过从这里开始,往前查具体是哪个 pass 变成的死代码,就容易很多了,只需要在浏览器中点击这行指令,就能将这条指令的变迁高亮出来,往前追几个 pass 很容易看到是 prove pass 出了问题:

右侧是 prove pass,可以看到这行在 prove pass 变成了灰色。
prove pass 简介
定位了出问题的策略是 prove pass,那么接下来我们就需要看看 prove pass 究竟是干什么用的。实际上,prove pass 的功能是对全局中 SSA 值的取值范围做一个推断,这样就可以消除掉许多不必要的分支判断,是不是听起来就跟今天的 bug 脱不了干系?实际上,这是在 Go 编译器中非常重要的一个 pass,很多优化都依赖于这个 pass 之后得到的结果。比如,由于 Go 是内存安全的语言,所以所有的 slice 取元素操作都需要做一个检查,来判断取元素用的下标是否超出了 slice 的范围,这个操作叫做 bound check。但是实际上,很多代码中在编译期就能确定这个下标是否越界,那么我们就可以将原本需要在运行期做 bound check 的检查给消除掉,这步优化叫做 bound check elimination,具体代码示例比如下面这段,是从 Go 标准库[4] 拿来的代码:
func (bigEndian) PutUint64(b []byte, v uint64) { _ = b[7] // early bounds check to guarantee safety of writes below b[0] = byte(v >> 56) b[1] = byte(v >> 48) b[2] = byte(v >> 40) b[3] = byte(v >> 32) b[4] = byte(v >> 24) b[5] = byte(v >> 16) b[6] = byte(v >> 8) b[7] = byte(v) }可以看到,这个函数中首先进行了 b[7] 的操作,这样一来,编译器在 prove pass 就可以了解到,当程序运行到第三行及之后时,slice b 的长度是必然大于等于 7 的,因此后续操作的 bound check 都可以被 eliminate 掉。 但是,prove pass 不止会做 bound check elimination 这一个特定 pattern 的优化,还有许多其他 pattern 也会在 prove pass 被优化掉。那么今天的这个 bug 究竟是 prove pass 中什么地方出了问题呢?
prove pass 问题排查
说起代码问题的定位方法,可能大体上能够分成三个流派。第一是打日志,通过在日志中加信息来定位问题;第二是通过 gdb 等 debugger 下断点、单步运行来排查问题;第三是动态追踪,通过 perf/systemtap/ebpf 之类的手段来动态观测程序运行时的行为。具体到 Go 编译器这里,其实开发 Go 编译器的 Go team 大牛们也需要日常排查问题,也不外乎这几种手段,但是在编译优化的问题上他们更青睐第一种打日志的方式,所以他们已经在各个 pass 中预埋了许多 debug 日志,只是这些日志平常不会开启,需要特殊的编译开关。既然 prove pass 相当复杂,我们不妨通过查日志的方式来进一步缩小问题排查范围。prove pass 的 debug 日志开关是 -d=ssa/prove/debug=1,其中 debug 后面跟的数字越大日志越详细,我们只需要在编译时执行 go tool compile -d=ssa/prove/debug=1 bug.go 就能看到对应的日志。具体到这个 bug,用 debug=1 的级别能够看到对比。如下图,左侧为复现程序的日志,右侧为修改常量后不复现的程序的日志:
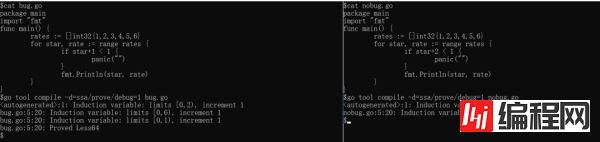
可以很清楚地看到,bug 程序明显多证出了一个关系。进一步地,通过 grep 编译器代码中这段日志关键词,就能找到只有 findIndVar 和 addLocalInductiveFacts 这两个函数中会打这条日志,结合上下文和相关注释不难看出实际上问题是出在 addLocalInductiveFacts 这个函数上。addLocalInductiveFacts 具体是什么功能呢?从注释中不难看出,这里的功能是匹配到一种特殊的代码 pattern,即类似 repeat until 的逻辑,在循环末尾判断某个条件是否成立。具体这个函数中的 bug 出在何处,我们还需要进一步用更高级别的 debug=3 来看其运行细节:
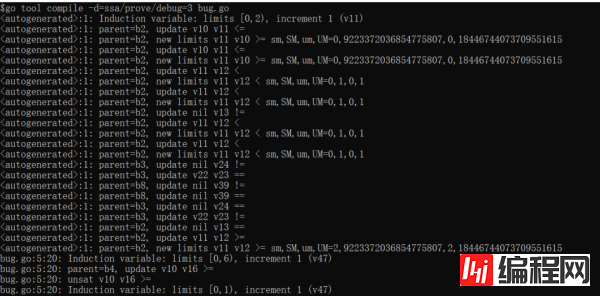
我这里只截到了相关日志部分。能看到,在出问题的 induction 之前,首先证得了 v10 >= v16 不成立。结合 addLocalInductiveFacts 可以发现,实际上编译器是将 v10 和 v16 分别当作了循环变量的上下界,也就是代码中的 min 和 max 变量。但是,结合 SSA IR 不难看出,其实 v16 根本不是循环变量的上界,那么问题究竟出在哪呢?

读 addLocalInductiveFacts 的 抽取 max 的相关代码[5](如上图片段)可以看出,这里的意图其实就是从条件判断结束后循环头部的 phi 操作所在 block 出发,一路向前追溯,找到条件判断的 block(if block),然后如代码中 1104 行,判断 phi 操作究竟是 if 的条件成立分支逻辑,还是 else 逻辑,根据分支来判断是否应当对条件进行取反,因为如果是 else 分支逻辑,那么意味着条件判断结果是 false,我们需要对条件取反才能得到真正成立的逻辑条件。看到这里的代码,相信大家已经知道了这个 bug 的根因所在。1104-1113 行代码写的很清楚,如果是条件成立分支,那么 br 为 positive,如果是 else 分支,那么 br 为 negative。但是,这里并没有判断 phi 操作跟 if block 的间接关联,如果 phi 操作跟 if block 没有直接联系,那么即使我们追溯到了 if block,也没法知道 br 变量究竟是 positive 还是 negative,取值就是 unknown。但是在后续逻辑中,并没有判断 unknown,而是直接默认按照 positive 的流程走;恰好在这个 bug 复现程序中,phi 操作所在 block 跟 if block 的 else 分支有间接关联,走 positive 流程自然就出了问题。
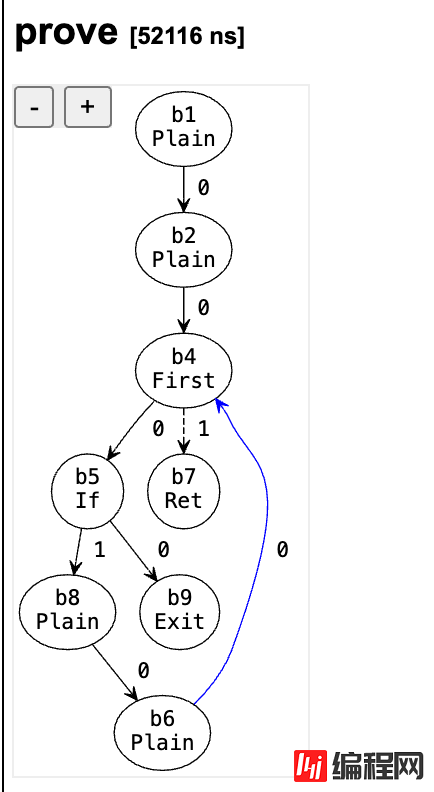
上图为问题复现代码的 ssa cfg 图,能够清楚地看出,b6 没有与对应的 b5 有直接关联,而是间接关联,命中了代码的错误路径。
结尾
定位到了问题,那么如何修复呢?一个很简单的方式,就是直接在 br 求值的逻辑后面,增加一个 unknown 判断逻辑,当 br == unknown 就直接退出判断。这样一来,prove pass 显然会变得保守,但是可以保证正确性。加了这个检查之后 bug 复现程序就运行正常了,但是作为更加 general 的修复,我们在函数的入口处增加对入口 block 的判断,确保入口 block 的确是一个循环开头块,而不是什么别的恰好也能匹配上当前 pattern 的东西。我将这个修复提交给了上游。这个 bug 由于非常严重,而且这个修复对性能实测基本没有太大影响,所以很快合入了 master,即 commit 7f8608047644ca34bad1728d5e2dbef041a1b3f2[6] ,并且将要 cherry pick 到仍然承诺维护的前两个大版本 1.13 和 1.14 中。前面提到,这个 patch 会让优化器更加保守,所以后续会通过其他修改让优化器恢复到之前的水平,我也已经提交了对应的 patch,不过由于 1.15 开发周期已经冻结,所以预计会在 1.16 cycle 合入 master。
到此,关于“如何理解Go编译器代码优化bug定位和修复”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: 如何理解Go编译器代码优化bug定位和修复
本文链接: https://lsjlt.com/news/84343.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0