这篇文章主要讲解了“kubernetes网络的四种场景是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Kubernetes网络的四种场景是什么”吧!在实
这篇文章主要讲解了“kubernetes网络的四种场景是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Kubernetes网络的四种场景是什么”吧!
在实际的业务场景中,业务组件之间的关系十分复杂,特别是微服务概念的提出,应用部署的粒度更加细小和灵活。为了支持业务应用组件的通信联系,Kubernetes网络的设计主要致力于解决以下场景:
(1)紧密耦合的容器到容器之间的直接通信;
(2)抽象的Pod到Pod之间的通信;
(3)Pod到Service之间的通信;
(4)集群外部与内部组件之间的通信。
1. 容器到容器的通信
在同一个Pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命名空间,共享同一个linux协议栈。所以对于网络的各类操作,就和它们在同一台机器上一样,它们甚至可以用localhost地址访问彼此的端口。这么做的结果是简单、安全和高效,也能减少将已经存在的程序从物理机或者虚拟机移植到容器的难度。
如下图中的阴影部分就是node上运行着的一个Pod实例。容器1和容器2共享了一个网络的命名空间,共享一个命名空间的结果就是它们好像在一台机器上运行似的,它们打开的端口不会有冲突,可以直接用Linux的本地IPC进行通信。它们之间互相访问只需要使用localhost就可以。
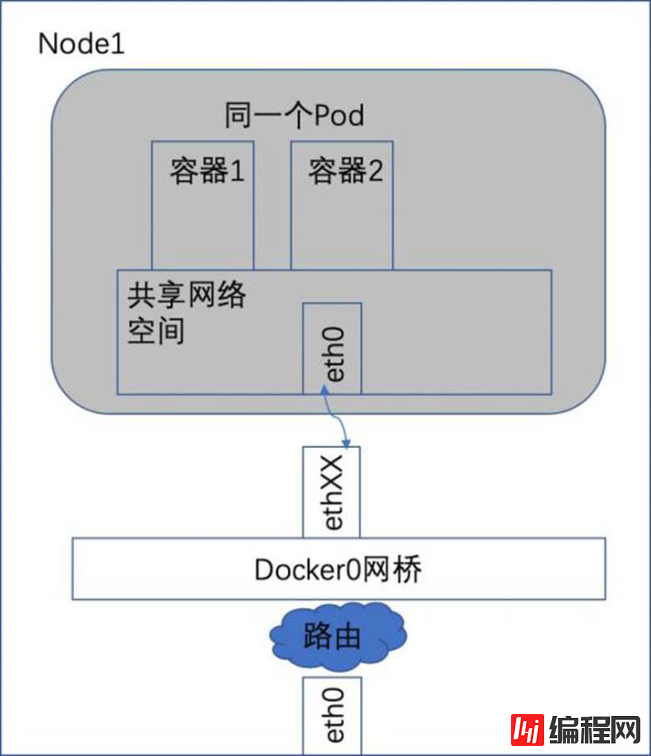
容器到容器间通信
2. Pod之间的通信
每一个Pod都有一个真实的全局IP地址,同一个Node内的不同Pod之间可以直接采用对房Pod的IP地址通信,而不需要使用其他发现机制,例如DNS、Consul或者etcd。Pod既有可能在同一个Node上运行,也有可能在不用的Node上运行,所以通信也分为两类:同一个Node内的Pod之间的通信和不同Node上的Pod之间的通信。
1)同一个Node内的Pod之间的通信
如图,可以看出,Pod1和Pod2都是通过Veth连接在同一个Docker0网桥上的,它们的IP地址IP1、IP2都是从Docker0的网段上自动获取的,它们和网桥本身的IP3是同一个网段的。另外,在Pod1、Pod2的Linux协议栈上,默认路由都是Docker0的地址,也就是说所有非本地的网络数据,都会被默认发送到Docker0网桥上,由Docker0网桥直接中转,它们之间是可以直接通信的。
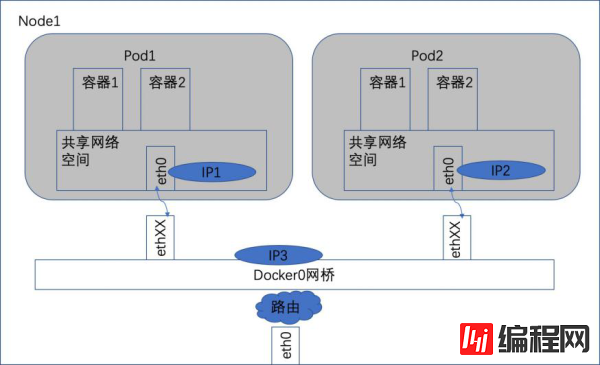
同一个Node内的Pod关系
2)不同Node上的Pod之间的通信
Pod的地址是与Docker0在同一个网段内的,我们知道Docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同Node之间的通信只能通过宿主机的物理网卡进行,因此要想实现位于不同Node上的Pod容器之间的通信,就必须想办法通过主机的这个IP地址来进行寻址和通信。另外一方面,这些动态分配且藏在Docker0之后的所谓“私有”IP地址也是可以找到的。Kubernetes会记录所有正在运行Pod的IP分配信息,并将这些信息保存在etcd中(作为Service的Endpoint)。这些私有IP信息对于Pod到Pod的通信也是十分重要的,因为我们的网络模型要求Pod到Pod使用私有IP进行通信。之前提到,Kubernetes的网络对Pod的地址是平面的和直达的,所以这些Pod的IP规划也很重要,不能有冲突。综上所述,想要支持不同Node上的Pod之间的通信,就要达到两个条件:
(1)在整个Kubernetes集群中对Pod分配进行规划,不能有冲突;
(2)找到一种办法,将Pod的IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问。
根据条件1的要求,我们需要在部署Kubernetes的时候,对Docker0的IP地址进行规划,保证每一个Node上的Docker0地址没有冲突。我们可以在规划后手工分配到每个Node上,或者做一个分配规则,由安装的程序自己去分配占用。例如Kubernetes的网络增强开源软件Flannel就能够管理资源池的分配。
根据条件2的要求,Pod中的数据在发出时,需要有一个机制能够知道对方Pod的IP地址挂在哪个具体的Node上。也就是说要先找到Node对应宿主机的IP地址,将数据发送到这个宿主机的网卡上,然后在宿主机上将相应的数据转到具体的Docker0上。一旦数据到达宿主机Node,则哪个Node内部的Docker0便知道如何将数据发送到Pod。
具体情况,如下图所示。
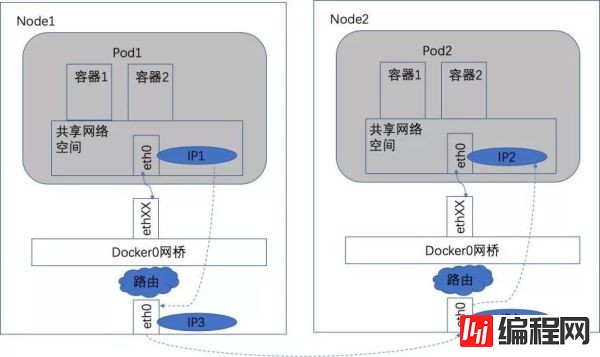
跨Node的Pod通信
在图6中,IP1对应的是Pod1,IP2对应的是Pod2。Pod1在访问Pod2时,首先要将数据从源Node的eth0发送出去,找到并到达Node2的eth0。也就是说先要从IP3到IP4,之后才是IP4到IP2的送达。
3. Pod 到Service之间的通信
为了支持集群的水平扩展、高可用,Kubernetes抽象出Service的概念。Service是对一组Pod的抽象,它会根据访问策略(LB)来访问这组Pod。
Kubernetes在创建服务时会为服务分配一个虚拟的IP地址,客户端通过访问这个虚拟的IP地址来访问服务,而服务则负责将请求转发到后端的Pod上。这个类似于反向代理,但是,和普通的反向代理有一些不同:首先它的IP地址是虚拟的,想从外面访问需要一些技巧;其次是它的部署和启停是Kubernetes统一自动管理的。
Service在很多情况下只是一个概念,而真正将Service的作用落实的是背后的kube-proxy服务进程。在Kubernetes集群的每个Node上都会运行一个kube-proxy服务进程,这个进程可以看作Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。对每一个tcp类型的Kubernetes Service,kube-proxy都会在本地Node上建立一个SocketServer来负责接收请求,然后均匀发送到后端某个Pod的端口上,这个过程默认采用RoundRobin负载均衡算法。Kube-proxy和后端Pod的通信方式与标准的Pod到Pod的通信方式完全相同。另外,Kubernetes也提供通过修改Service的service.spec.-sessionAffinity参数的值来实现会话保持特性的定向转发,如果设置的值为“ClientIP”,则将来自同一个ClientIP的请求都转发到同一个后端Pod上。此外,Service的ClusterIP与NodePort等概念是kube-proxy通过Iptables和NAT转换实现的,kube-proxy在运行过程中动态创建与Service相关的Iptables规则,这些规则实现了ClusterIP及NodePort的请求流量重定向到kube-proxy进程上对应服务的代理端口的功能。由于Iptables机制针对的是本地的kube-proxy端口,所以如果Pod需要访问Service,则它所在的那个Node上必须运行kube-proxy,并且在每个Kubernetes的Node上都会运行kube-proxy组件。在Kubernetes集群内部,对Service Cluster IP和Port的访问可以在任意Node上进行,这个因为每个Node上的kube-proxy针对该Service都设置了相同的转发规则。
综上所述,由于kube-proxy的作用,在Service的调用过程中客户端无需关心后端有几个Pod,中间过程的通信、负载均衡及故障恢复都是透明的,如下图所示。
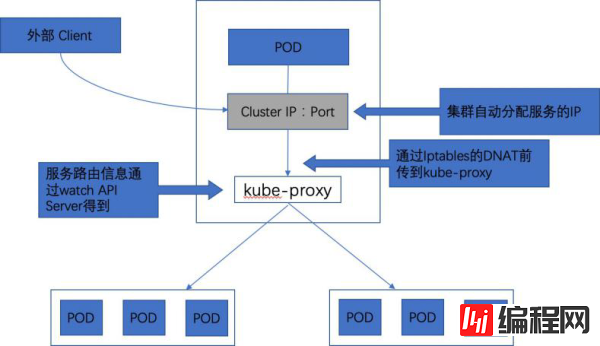
Service的负载均衡转发
访问Service的请求,不论是用Cluster IP+Target Port的方式,还是用节点机IP+Node Port的方式,都会被节点机的Iptables规则重定向到kube-proxy监听Service服务代理端口。Kube-proxy接收到Service的访问请求后,会如何选择后端Pod?
首先,目前kube-proxy的负载均衡只支持Round Robin算法。该算法按照成员列表逐个选取成员,如果一轮循环完,便从头开始下一轮,如此循环往复。Kube-proxy的负载均衡器在Round Robin算法的基础上还支持Session保持。如果Service在定义中指定了Session保持,则kube-proxy接收请求时会从本地内存中查找是否存在来自该请求IP的affinityState对象,如果存在该对象,且Session没有超时,则kube-proxy将请求转向该affinityState所指向的后端Pod。如果本地存在没有来自该请求IP的affinityState对象,记录请求的IP和指向的Endpoint。后面的请求就会粘连到这个创建好的affinityState对象上,这就实现了客户端IP会话保持的功能。
接下来我们深入分析kube-proxy的实现细节。kube-proxy进程为每个Service都建立了一个“服务代理对象”,服务代理对象是kube-proxy程序内部的一种数据结构,它包括一个用于监听此服务请求的Socket-Server,SocketServer的端口是随机选择的一个本地空闲端口。此外,kube-proxy内部也建立了一个“负载均衡器组件”,用来实现SocketServer上收到的连接到后端多个Pod连接之间的负载均衡和会话保持能力。
kube-proxy通过查询和监听api Server中Service与Endpoint的变化来实现其主要功能,包括为新创建的Service打开一个本地代理对象(代理对象是kube-proxy程序内部的一种数据结构,一个Service端口是一个代理对象,包括一个用于监听的服务请求的SocketServer),接收请求,针对发生变化的Service列表,kube-proxy会逐个处理。下面是具体的处理流程:
(1)如果该Service没有设置集群IP(ClusterIP),则不做任何处理,否则,获取该Service的所有端口定义列表(spec.ports域)
(2)逐个读取服务端口定义列表中的端口信息,根据端口名称、Service名称和Namespace判断本地是否已经存在对应的服务代理对象,如果不存在就新建,如果存在且Service端口被修改过,则先删除Iptables中和该Service相关的的规则,关闭服务代理对象,然后走新建流程,即为该Service端口分配服务代理对象并为该Service创建相关的Iptables规则。
(3)更新负载均衡器组件中对应Service的转发地址表,对于新建的Service,确定转发时的会话保持策略。
(4)对于已经删除的Service则进行清理。
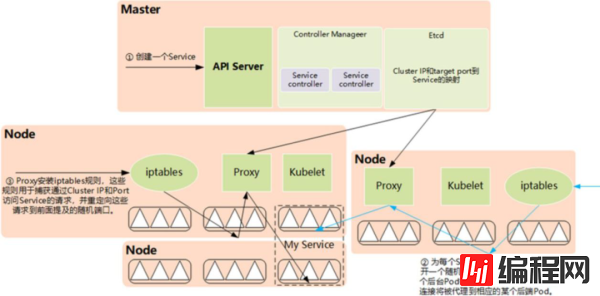
Kube-proxy与APIServer的交互过程
4. 外部到内部的访问
Pod作为基本的资源对象,除了会被集群内部的Pod访问,也会被外部使用。服务是对一组功能相同Pod的抽象,以它为单位对外提供服务是最合适的粒度。
由于Service对象在Cluster IP Range池中分配到的IP只能在内部访问,所以其他Pod都可以无障碍地访问到它。但如果这个Service作为前端服务,准备为集群外的客户端提供服务,就需要外部能够看到它。
Kubernetes支持两种对外服务的Service的Type定义:NodePort和LoadBalancer。
(1)NodePort
在定义Service时指定spec.type=NodePort,并指定spec.ports.nodePort的值,系统就会在Kubernetes集群中的每个Node上打开一个主机上的真实端口号。这样,能够访问Node的客户端就能通过这个端口号访问到内部的Service了。
(2)LoadBalancer
如果云服务商支持外接负载均衡器,则可以通过spec.type=LoadBalancer定义Service,同时需要指定负载均衡器的IP地址。使用这种类型需要指定Service的NodePort和ClusterIP。
对于这个Service的访问请求将会通过LoadBalancer转发到后端Pod上去,负载分发的实现方式依赖于云服务商提供的LoadBalancer的实现机制。
(3)外部访问内部Service原理
我们从集群外部访问集群内部,最终都是落在具体的Pod上。通过NodePort的方式就是将kube-proxy开放出去,利用Iptables为服务的NodePort设置规则,将对Service的访问转到kube-proxy上,这样kube-proxy就可以使用和内部Pod访问服务一样的方式来访问后端的一组Pod了。这种模式就是利用kube-proxy作为负载均衡器,处理外部到服务进一步到Pod的访问。而更常用的是外部均衡器模式。通常的实现是使用一个外部的负载均衡器,这些均衡器面向集群内的所有节点。当网络流量发送到LoadBalancer地址时,它会识别出这是某个服务的一部分,然后路由到合适的后端Pod。
所以从外面访问内部的Pod资源,就有了很多种不同的组合。
外面没有负载均衡器,直接访问内部的Pod
外面没有负载均衡器,直接通过访问内部的负载均衡器来访问Pod
外面有负载均衡器,通过外部负载均衡器直接访问内部的Pod
外面有负载均衡器,通过访问内部的负载均衡器来访问内部的Pod
第一种情况的场景十分少见,只是在特殊的时候才需要。我们在实际的生产项目中需要逐一访问启动的Pod,给它们发送一个刷新指令。只有这种情况下才使用这种方式。这需要开发额外的程序,读取Service下的Endpoint列表,逐一和这些Pod进行通信。通常要避免这种通信方式,例如可以采取每个Pod从集中的数据源拉命令的方式,而不是采取推命令给它的方式来避免。因为具体到每个Pod的启停本来就是动态的,如果依赖了具体的Pod们就相当于绕开了Kubernetes的Service机制,虽然能够实现,但是不理想。
第二种情况就是NodePort的方式,外部的应用直接访问Service的NodePort,并通过Kube-proxy这个负载均衡器访问内部的Pod。
第三种情况是LoadBalancer模式,因为外部的LoadBalancer是具备Kubernetes知识的负载均衡器,它会去监听Service的创建,从而知晓后端的Pod启停变化,所以它有能力和后端的Pod进行通信。但是这里有个问题需要注意,那就是这个负载均衡器需要有办法直接和Pod进行通信。也就是说要求这个外部的负载均衡器使用和Pod到Pod一样的通信机制。
第四种情况也很少使用,因为需要经历两级的负载均衡设备,而且网络的调用被两次随机负载均衡后,更难跟踪了。在实际生产环境中出了问题排错时,很难跟踪网络数据的流动过程。
(4)外部硬件负载均衡器模式
在很多实际的生产环境中,由于是在私有云环境中部署Kubernetes集群,所以传统的负载均衡器都对Service无感知。实际上我们只需要解决两个问题,就可以将它变成Service可感知的负载均衡器,这也是实际系统中理想的外部访问Kubernetes集群内部的模式。
通过写一个程序来监听Service的变化,将变化按照负载均衡器的通信接口,作为规则写入负载均衡器。
给负载均衡器提供直接访问Pod的通信手段。
如下图,说明了这个过程。
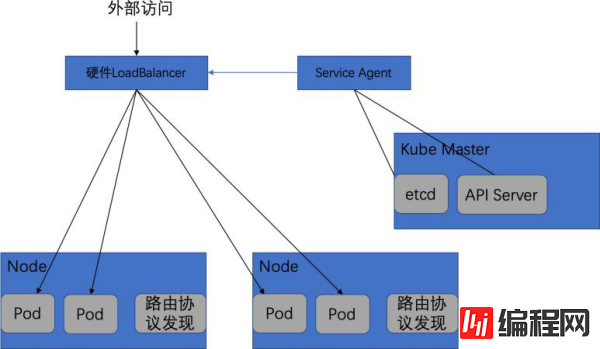
自定义外部负载均衡器访问Service
这里提供了一个Service Agent来实现Service变化的感知。该Agent能够直接从etcd中或者通过接口调用API Server来监控Service及Endpoint的变化,并将变化写入外部的硬件负载均衡器中。
同时,每台Node上都运行着有路由发现协议的软件,该软件负责将这个Node上所有的地址通过路由发现协议组播给网络内的其他主机,当然也包含硬件负载均衡器。这样硬件负载均衡器就能知道每个Pod实例的IP地址是在哪台Node上了。通过上述两个步骤,就建立起一个基于硬件的外部可感知Service的负载均衡器。
感谢各位的阅读,以上就是“Kubernetes网络的四种场景是什么”的内容了,经过本文的学习后,相信大家对Kubernetes网络的四种场景是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: Kubernetes网络的四种场景是什么
本文链接: https://lsjlt.com/news/84342.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0