这篇文章给大家介绍什么是主从复制,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。复制的方式在集群中实现复制主要通过两种方式:状态转移(State Transfer):主机(Primary
这篇文章给大家介绍什么是主从复制,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
复制的方式
在集群中实现复制主要通过两种方式:
状态转移(State Transfer):主机(Primary)将自己所有的状态,拷贝并发送给备机(Backup),一般是增量备份;
复制状态机(Replicated State Machine):将备机视为一个确定的状态机——client 发送操作到主机,主机按顺序发送到备机,所有备机执行所有的操作,如果从同一起始状态,以相同的顺序输入相同的操作,它们的输出将是相同的。
VMware FT 使用了复制状态机的方法。
状态转移传输的可能是内存,而复制状态机传输来自客户端的操作或者其他外部事件,人们倾向于使用复制状态机的原因是,外部操作或事件通常比服务的内存状态要小。例如,如果是一个数据库,它的内存状态可能达到 GB 级别。
复制的挑战
要考虑的几个 Big Question:
我们要复制哪些状态?
主机必须等待备机备份完吗?
什么时候切换到备机?
切换时能否看到异常情况?
如果有个副本故障了,我们需要重新添加一个新的副本,这可能是一个代价很高的行为,因为副本可能非常大,如何提升添加新副本的速度?
让我们看看虚拟化巨头 VMware 是怎么做的。
VMware FT 论文总结
总览
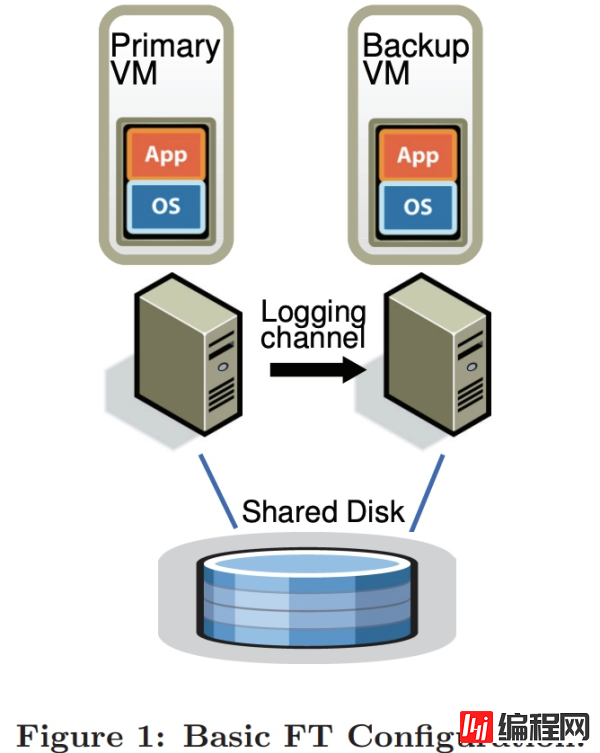
如图 1,约定:主虚拟机(Primary VM)简称为主机,Backup VM 简称为备机。
VMware FT 需要两台物理服务器,主机与备机保持同步,虚拟机的虚拟磁盘在共享存储上。
所有的输入(如网络、鼠标、键盘等)都会输入到主机,然后通过 Logging channel 转发到备机,对于非确定性的操作,还将发送额外的信息,确保备机以确定性的方式执行这些操作。
两台虚拟机都会执行输入操作,但只有主机的输出会返回客户端,备机的输出会被管理程序丢弃。
确定性重放(Deterministic replay)
不确定性(Non-Deterministic)事件比如虚拟中断,不确定性操作比如从处理器读取时钟周期计数器,可能会让主机和备机的运行结果不一样。
这带来三个挑战:
正确捕获所有输入和必要的不确定性输入来保证备机确定性执行;
正确在备机执行不确定性输入;
不降低系统的性能;
VMware 确定性重放(deterministic replay)能够捕获所有输入和可能的不确定性输入,并写到日志文件记录下来。通过读取日志文件,可以准确重放虚拟机的执行。
对于不确定性输入,必须记录足够的信息来重放,但是论文中没有描述具体的日志格式,Robert 教授猜测可能有三种记录:
事件发生时的指令序号;
日志类型。可能是普通的网络数据输入,也可能是怪异的指令;
数据。
FT 协议(FT Protocol)
VMware FT 通过确定性重放来产生相关的日志条目,但不将日志写入磁盘,而是通过 logging channel 发送给备机。备机实时重放日志项。
为了容错,必须在 loggin channel 上实现严格的容错协议,有以下要求:
输出要求:如果备机在主机故障后接管,备机将以和主机已经向外界发送的输出完全一致的方式继续运行。
最简单的方式是对每一个输出操作创建一个特殊的日志项。
但有一种情况,假设虚拟机运行的是数据库,主机备机的数据都是 10。现在客户端发送自增请求,主机做了 +1 并回复给客户端 11,之后马上宕机了,更糟糕的是主机发送给备机的 +1 操作也丢包了。这时候备机还是 10,并接管了主机的工作,客户端再次请求 +1,又会收到 11 的回复。客户端会得到一个怪异的结果(自增两次还是 11)。
所以要求:
输出规则:主机直到备机接收并确认了和输出相关的日志的时候,才发送输出给外界。
这样做的目的是,只要备机收到了所有的日志条目,即使主机宕机了,备机仍能够重放到客户端最后看到的状态。
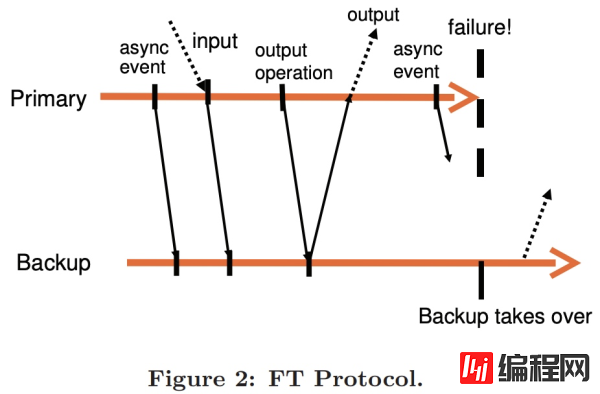
如图 2 所示,向外界的输出会被延迟,直到主机收到来自备机的确认。
几乎每一个复制系统都有这个问题:在某个时间点,主机必须停下来等待备机,这肯定会限制性能。
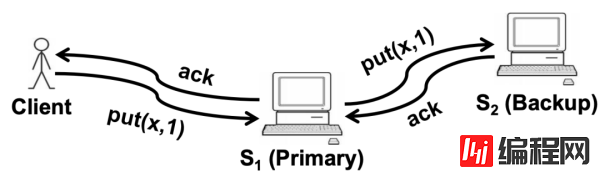
注意:因为没有两阶段提交事务,不能保证所有的输出只被生成一次。备机无法判断主机是在宕机之前还是之后发送了最后的输出,备机可能会重新执行一次输出操作。不过,VMware 通过其网络基础设施来检测重复数据包,并防止输出重传到客户端。
发现与处理故障
主机和备机必须快速知道另一方故障,通过 udp 心跳包和监控 logging channel 上的流量相结合来检测,如果心跳超时或 logging channel 流量停止则表明故障。
如果备机故障,主机就会停止向 logging channel 发送日志,继续正常运行。
在这之后备机怎么追上主机呢?VMware有一个工具叫 VMotion,它能够在最小程度上中断虚拟机的执行,克隆一个虚拟机。
如果主机故障,备机必须先重放,直到消耗完最后一个日志项。然后备机接替主机,开始向客户端生产输出。
为了确保一次只有一个虚拟机成为主机,避免出现脑裂,VMware 在共享存储上执行一个原子的 test-and-set 锁指令。该操作每次只能对其中一台机器返回成功,这在主机和备机因为网络分区都想接替工作时很有用。但如果共享存储因为网络问题不能访问,那么无论如何都不能正常工作。
当其中一台虚拟机发生故障时,VMware FT 会在另一台物理机上自动启动新的备份虚拟机来恢复冗余。
FT 的实际实现细节
上一节描述了容错的基础设计和协议,但为了创建一个可用的、健壮的自动化系统,还需要设计和实现许多其他组件。
启动和重启 FT VMs
一个挑战是,如何在主机运行时,以和主机相同的状态启动备机?为了解决这个问题,VMware 提供一个名为 VMware VMotion 的工具,允许在最小化中断的代价下,将运行中的虚拟机从一台服务器迁移到另一台服务器。为了容错,该工具被重新设计为 FT VMotion,以允许将虚拟机克隆到远程主机上,这种克隆操作打断主机的时间不超过 1 秒。
管理 Logging Channel
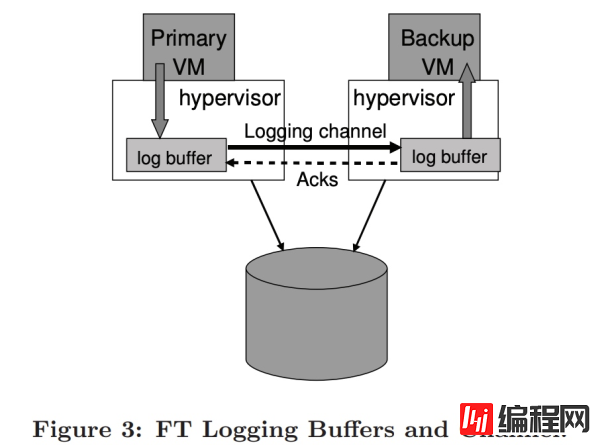
上图 3 说明了日志从主机产生到在备机上消费的过程。
虚拟机管理程序维护了一个大的日志缓冲(log buffer),保存主机和备机的日志。主机会产生日志项到日志缓冲,备机从日志缓冲消费日志。
如果备机读到空的日志缓冲,则会暂停运行直到日志缓冲有日志;如果主机写日志的时候发现日志缓冲满了,也会暂停运行直到日志项被清除——这种暂停会影响虚拟机的客户端。因此,我们的实现必须最小化主机日志缓冲写满的可能性。
通常,主机日志缓冲满的原因:
带宽太小,建议日志通道带宽 1Gbit/s;
备机执行速度太慢,从而消费日志太慢时,主机的日志缓冲也可能会被填满;
在 VMware FT 中已经实现了一种机制,当备机远远落后时(根据论文中的说法,落后超过1秒),可以减缓主机的执行速度。通过减少主机的 CPU 资源来减慢速度。
注意对于主机的减速是很罕见的,通常只在系统处于极端压力的情况下发生。
磁盘 IO 实现问题
有一些和磁盘 IO 相关的细微的实现问题。
问题 1:非阻塞的磁盘操作可以并行执行,因此对同一磁盘位置的同时访问可能导致不确定性。
解决方案:检测所有这类 IO 竞争,然后强制这些竞争的磁盘操作以相同的方式在主机和备机上顺序执行。
怎么检测?论文也没说。
问题 2:虚拟机上的应用程序(或操作系统)的磁盘操作也可能导致内存的竞争
解决方案:通过 Bounce buffer—— 一个和磁盘操作正在访问的内存大小一致的临时缓冲来解决。磁盘读操作被修改为在 bounce buffer 中读取特定数据,并且数据仅在IO操作完成并传递完成的时候拷贝到虚拟机内存。类似的,对于磁盘写操作,将要被发送的数据会先拷贝到 bounce buffer,磁盘写操作修改为写数据到 bounce buffer。
Bounce buffer 的使用会减慢磁盘操作,但是论文表示还没有看到任何明显的性能差异。
问题3:磁盘 IO 因主机故障在主机上没有完成,备份接管后怎么办?
解决方案:发送错误来表明 IO 失败,然后重试错误的 IO。
替代方案
本节讨论一些替代方案,以及他们所做的权衡。
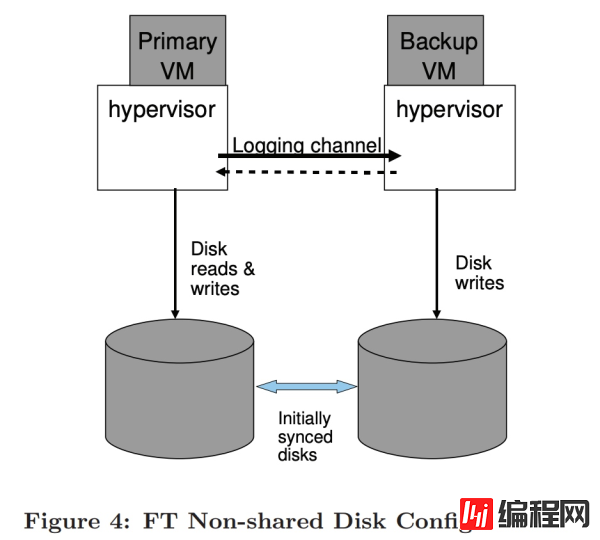
共享磁盘与非共享磁盘:VMware FT 使用了一个主备机都能访问的共享存储。一个替代方案是使用单独(非共享)的虚拟磁盘,主备机分别写入这些磁盘。这种设计可以用在共享存储不能同时被主、备机访问,或者共享存储太贵的情况下。缺点是需要做额外的工作,必须同步磁盘状态。
在备机上执行磁盘读取:在目前实现中,备机绝不会从磁盘进行读取,磁盘操作被认为是一种输入。一个替代的设计是,备机可以执行磁盘读取,当有大量磁盘读的工作负载时,这种方法可以帮助减少日志通道的流量。然而,这种方法有两个主要挑战:
可能会减慢备机的执行速度,因为备机必须执行所有的磁盘读;
如果读取在主机上成功,但在备机上失败(反之亦然)怎么办?必须做一些额外的工作来处理失败的磁盘读操作。
VMware 的性能评估显示,在备机上执行磁盘读取会降低 1-4% 的吞吐量,但同时也降低了日志带宽。
FAQ
来自:https://pdos.csail.mit.edu/6.824/papers/vm-ft-faq.txt
Q: GFS 和 VMware FT 都提供了容错性,哪一个更好?
FT 提供计算容错,你能用它为任何已有的网络服务器提供容错性。FT 提供了相当严格的一致性而且对客户端和服务器都是透明的。例如,你可以将 FT 应用于一个已有的邮件服务器并为其提供容错性。
GFS 只提供存储容错,因为 GFS 只针对特定的简单服务(存储)提供容错性,它的备份策略会比 FT 更高效。例如,GFS 不需要使中断都以完全相同的指令发生在所有的副本上。GFS 通常只会用于一个对外提供完整容错服务的系统的一部分。例如,VMware FT 本身也依赖了一个在主备机间共享的有容错性的存储服务,而你则可以用类似于 GFS 的东西来实现这个共享存储(虽然从细节上来讲 GFS 不太适用于 FT)。
Q: 共享存储上的原子 test-and-set 指令是什么?
在共享存储上的一个服务,最初状态为 false,主机或备机认为对方宕机了,自己应该接管的时候,首先要向共享存储发送一个 test-and-set 操作,伪代码是:
test-and-set() { acquire_lock() if flag == true: release_lock() return false else: flag = true release_lock() return true只有当返回 true 时才能接管主机。主要为了避免当主、备机出现网络分区,都想接管时出现脑裂(即同时有两个主机)的情况。
这有点像一个分布式锁。问题是:伪代码没有展示什么时候 flag会被设为 false!
老师解释:论文没有提及什么时候将 flag 重设为 false,也许是管理员人为的操作,也许是交给机器来清理。
关于什么是主从复制就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
--结束END--
本文标题: 什么是主从复制
本文链接: https://lsjlt.com/news/83415.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0