如何Kotlin协程用法浅析用在京东APP业务中实践,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。协程定义及设计的目的:协程是
如何Kotlin协程用法浅析用在京东APP业务中实践,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
协程定义及设计的目的:协程是一种并发设计模式,是一套由 Kotlin 提供的线程框架。开发者使用协程框架可以通过结构化并发机制在同一作用域下,把运行的不同线程的代码写在同一个代码块里并执行,简化异步执行的代码,使得我们的代码显得线性。用法浅析
本文基于kotlinx-coroutines-Android V1.3.8版本协程库进行讲解。
使用协程前我们需要先了解几个概念:
协程作用域 CoroutineScope:定义新协程的范围,通过它的扩展函数可以创建、启动协程,并可以管理协程,比如取消该作用域下的协程,Kotlin 协程为我们提供了一组内置的 Scope: MainScope:使用 Dispatchers.Main 调度器的作用域 LifecycleScope:与 Lifecycle 生命周期绑定 ViewModelScope:与 ViewModel 生命周期绑定 GlobalScope:生命周期贯穿全局
协程构建器:CoroutineScope 的扩展函数,用于构建协程,比如 launch,async;
协程上下文 CoroutineContext:一个左向链表的实现,Job、Dispatcher 调度器都可以是它的元素,CoroutineContext 有一个非常好的作用就是可以很方便的通过其获取 Job、Dispatcher 调度器等数;
CoroutineStart启动模式:DEFAULT:立即调度,可以在执行前被取消 LAZY:需要时才启动,需要 start、join 等函数触发才可进行调度 ATOMIC:立即调度,协程肯定会执行,执行前不可以被取消 UNDISPATCHED:立即在当前线程执行,直到遇到第一个挂起
Dispatchers调度器:DEFAULT:默认调度器,适合 CPU 密集型任务调度器,比如逻辑计算 Main:UI 线程调度器 Unconfined:对协程执行的线程不做限制,协程恢复时可以在任意线程 io:IO调度器,适合 IO 密集型任务调度器 比如读写文件,网络请求等
suspending lambda:一个可挂起的 lambda 表达式,它的全定义为 suspend CoroutineScope.() -> Unit,这是一个被 suspend 修饰符修饰的"CoroutineScope 扩展函数类型",作为扩展函数,它的优势在于可以直接访问 CoroutineScope 内的属性;
suspension point 挂起点:一般对应挂起函数被调用的位置;
挂起函数:由 suspend 修饰的函数,挂起函数只能在挂起函数或者协程中调用;
开篇中概念章节中介绍了协程构建器用于协程的构建,协程的构建器是CoroutineScope的扩展函数。
coroutineScope.launch(Dispatchers.IO) { // 示例(1) // 运行在IO线程 } coroutineScope.launch(Dispatchers.Main) { // 示例(2) // 运行在UI线程 }在上述代码中,演示了一个协程的创建,我们以实例(1)为例,它的含义是通过 coroutineScope 作用域的扩展函数 launch 创建了一个运行在IO线程的协程,大家可以看到代码还是很清晰的,这时候就可以在协程中做一些耗时性的操作。同理实例(2)中创建了一个运行在UI线程的协程。
val job: Job = coroutineScope.launch(Dispatchers.IO, CoroutineStart.LAZY) { // 示例(1) // 运行在IO } job.start()在上述代码中,我们将示例(1)进行了改造,调用 launch 函数时,新增了一个参数 CoroutineStart.LAZY,并将返回的 Job 对象赋值给变量 job。
默认情况下,协程的启动模式为 CoroutineStart.DEFAULT,即协程创建完成之后会立即执行,示例中设置启动模式为 CoroutineStart.LAZY,这时候 launch 函数创建了协程,并没有启动它,此时协程的启动需要依靠 Job 的 start 等函数进行启动。
Job 是一个具有生命周期的并且可以被取消的后台工作或者说异步任务,Job 内提供了 isActive、isCompleted、isCancelled 属性用以判断协程的状态,以及启动协程 start()、取消协程 cancel() 等操作的 api。
假如现在有这个一个需求,存在两个接口,一个用于获取用户个人信息、一个用于获取企业信息,需要两个接口数据都获取到的时候才可以进行 UI 的刷新,这时候 async 并发就凸显它的优势;
coroutineScope.launch(Dispatchers.Main) { val async1 = async(Dispatchers.IO) { // 网络请求1 "模拟用户信息数据获取" } val async2 = async(Dispatchers.IO) { // 网络请求2 "模拟企业信息数据获取" } handleData(async1.await(), async2.await()) // 模拟合并数据 }在上述代码中通过 async 发起两个协程获取数据,并通过 await() 获取到请求结果,因为并行发起,所以速度也是挺快的。
通过 async 创建的协程返回值是一个 Deferred,Deferred 带有延迟的意思,可以通俗理解成要等一等才能拿到结果,Deferred 也是一个 Job,它是 Job 的一个子类,所以具有 Job 同样的功能。
当然 async 默认的启动模式和 launch 一样,也是 CoroutineStart.DEFAULT 立即执行,当将启动模式设置为 CoroutineStart.LAZY 时可以通过 await() 启动协程,也可以通过 Job 的 start() 函数启动。
在这一章节中,会通过几个示例对比,来体现Kotlin协程的优势在哪里,同时笔者建议阅读此章节的时候不要太在意实现的细节,关注不同方式的实现风格就好。
private fun getUserInfo() { // 示例(1) apiService.getUserInfo().enqueue(object : Callback<UserInfoEntry> { override fun onResponse(c: Call<UserInfoEntry>, re: Response<UserInfoEntry>) { runOnUiThread { tvName.text = response.body()?.userName } } override fun onFailure(call: Call<UserInfoEntry>, t: Throwable) { } }) } private fun getUserInfoByCoroutine() { // 示例(2) coroutineScope.launch(Dispatchers.Main) { val userInfo = coroutineApiService.getUserInfo() tvName.text = userInfo.userName } }这是一个获取用户信息的网络请求示例,通过普通的 CallBack 方式及 Kotlin协 程的方式分别实现。
示例(1)是比较常见的一个种方式,发起网络请求,通过 CallBack 回调数据,最后切换主线程刷新 UI,很常见的写法。
示例(2)是协程的实现方式,通过 scope 的扩展函数 launch 创建了一个运行在主线程的协程,协程的实现中,也是获取数据后刷新 UI。
现在我们对比一下两种方式的实现,看看协程的实现有什么优化的地方?首先在协程的实现中没有了 CallBack 的回调,其次在刷新UI的时候并没有切换到主线程的操作,最后代码量也是比较简洁的。
其实还好,第一种方式在我们在开发中,这种 CallBack 的回调,应该应用过无数次了,写起来也是分分钟的事情,并不会多么困难。确实,这样 Kotlin 协程的优势也不是那么明显了。
接下来我们看一个复杂一些的场景,以上文讲解 async 时提到过的合并用户信息数据和企业信息数据为例,我们看看更详细的实现,在这里复述一下场景:“存在两个接口,一个用于获取用户个人信息、一个用于获取企业信息,需要两个接口数据都获取到的时候才可以进行 UI 的刷新”。
private fun start() { getUserInfo() getCompanyInfo() } private fun getUserInfo() { apiService.getUserInfo().enqueue(object : Callback<UserInfoEntry> { override fun onResponse(c: Call<UserInfoEntry>, r: Response<UserInfoEntry>) { // 判断是不是已经拿到公司信息了 // 刷新UI handle.post() } override fun onFailure(call: Call<UserInfoEntry>, t: Throwable) { } }) } private fun getCompanyInfo() { apiService.getCompanyInfo().enqueue(object : Callback<UserInfoEntry> { override fun onResponse(c: Call<UserInfoEntry>, r: Response<UserInfoEntry>) { // 判断是不是已经拿到用户信息了 // 刷新UI handle.post() } override fun onFailure(call: Call<UserInfoEntry>, t: Throwable) { } }) }在这种方式中,我们将两个接口请求封装了两个 API,同时发起网络请求,相对使用上不能说不方便,关键在于数据的处理上,用户信息的数据拿到之后需要判断企业信息是不是也获取到了,同理企业信息的数据也是一样,现在只有两组数据的合并,如果涉及更多信息类型数据的获取,相应的逻辑处理就变的越来越复杂了。
当然如果改成串行的逻辑也是很好处理的,比如先获取用户信息数据,获取之后再进行企业信息数据的读取,但是这种方式牺牲了时间,本来可以并行的请求,变成串行,请求时间加长。
private fun getKotlinInfo() { coroutineScope.launch(Dispatchers.Main) { val userInfo = async { apiService.getUserInfo() } // 获取用户信息 val companyInfo = async { apiService.getCompanyInfo() } // 公司信息 MergeEntry(userInfo.await(), companyInfo.await()) } }这是 Kotlin 协程的实现方式,使用 CoroutineScope 的 async 构建器实现,在需要更多请求时,它的逻辑处理很方便,多一个请求多一个 async 即可,并行的请求节省时间,而且消除了回调,并且不需要切换线程。
在了解了协程的创建、启动及优势之后,现在有一个问题我们什么时候使用协程?当我们需要处理耗时数据的时候,这时候可以使用协程切换到子线程执行,当处理完数据需要刷新 UI 的时候可以使用协程切换到主线程,其实需要指定运行线程的时候就可以用协程处理。
coroutineScope.launch(Dispatchers.IO) { // 运行在IO线程 handleFileData() // 模拟读文件耗时操作 launch(Dispatchers.Main) { // 数据处理完成刷新UI tvName.text = "" } }在上述代码中,有一个耗时读文件操作,所以这里使用了协程,通过 launch 切换到 IO 线程处理耗时操作,处理完成之后通过 launch 函数切到 Main 线程刷新 UI,好像没毛病,我们继续看下一段代码。
coroutineScope.launch(Dispatchers.IO) {// 运行在IO线程 handleFileData() // 模拟读文件 launch(Dispatchers.Main) { // 数据处理完成刷新UI launch(Dispatchers.IO) { // 处理数据 launch(Dispatchers.Main) { // 数据处理完成刷新UI launch(Dispatchers.IO) { launch(Dispatchers.Main) { launch(Dispatchers.IO) { launch(Dispatchers.Main) { } } } } } } } }这个示例演示的场景比较极端,很少在开发中会遇到 IO 与 Main 线程切换如此频繁,在这里只是为了暴露问题。前面我们说过 Kolin 协程消除了回调,但在这个示例中却表现的很回调,层层嵌套。
因为单单使用 launch、async 协程构建器函数并不能很好的处理这种复杂的需要频繁切换线程的场景,为了解决示例中的问题,Kotlin 协程为我们提供了一些另外的函数来配合使用, 比如 withContext 挂起函数。
withContext 是 Kotlin 协程提供的挂起函数,它提供给的功能有:
可以切换到指定的线程运行;
函数体执行完之后,自动切回原来的线程。
coroutineScope.launch(Dispatchers.Main) { // 在主线程开启一个协程 val data = withContext(Dispatchers.IO) { // 切到IO线程处理耗时操作 handleFileData() // 在IO线程运行 } tvName.text = data // withContext函数体执行完,自定切换到主线程刷新UI } coroutineScope.launch(Dispatchers.Main) { withContext(Dispatchers.IO) { // **操作(1)** // 切换IO线程 // ... 在IO线程执行 } // .. 在UI线程执行 **操作(2)** withContext(Dispatchers.IO) { // 切换IO线程 // ... 在IO线程执行 } // .. 在UI线程执行 withContext(Dispatchers.IO) { // 切换IO线程 // ... 在IO线程执行 } // .. 在UI线程执行 // ...等等... }使用 withContext 改造之后,消除了嵌套,代码变得清晰,所以,Kotlin 协程除了 launch 等扩展函数之外,还需要 withContext 等挂起函数,才可体现它的优势。
这里有必要提一下,在没有使用协程的时候,开启一个线程,代码就会出现两个分支,比如上述代码中的操作(1),切到了IO线程执行,这是一个分支,紧接着是执行操作(2),这是另一个分支,这两个分支各走各的,“几乎同步执行”;
但在协程中,操作(1)使用withContext挂起函数切换到IO线程去执行它的操作后,并不会执行操作(2),而是等待操作(1)的withContext执行完成之后,切换线程回到Main线程中时,操作(2)才会执行,后续的supend章节会有讲解。

public suspend fun <T> withContext( context: CoroutineContext, block: suspend CoroutineScope.() -> T ): T {}在上面的示例中 getData() 是一个普通的函数,在其中调用的 withContext 挂起函数时,提示报错信息:suspend function 'withContext' should be called only from a coroutine or another supend function,意思是说 withContext 是一个被 suspend 修饰的函数,它应该在协程或者另一个 spspend 函数中调用。源码中 withContext 被 suspend 修饰。
suspend 是 Kotlin 协程的一个关键字,由 suspend 修饰的函数为挂起函数,挂起函数只能在协程或者另一个挂起函数中调用。
从开发者的层面说,suspend 关键字的作用就是一个提醒的作用,提醒什么?提醒函数的调用者,这是一个挂起函数,内部存在耗时操作,需要在协程或者另一个挂起函数中调用才行;
但从编译过程来说,被 suspend 修饰的函数,有特殊的解读,比如会新增一个参数 Continuation,这也是为什么在普通函数中无法调用挂起函数的原因。
刚才我们说被 suspend 修饰的函数是挂起函数,挂起从字面意思可以理解为不执行了或者说是暂停了,这里有一个疑问,挂起的是谁?是线程?函数?还是协程?
其实挂起的是协程,可以理解为在协程中执行到 suspend 挂起函数的时候,就会暂停协程后续代码的执行,我们分析一下下面代码的执行流程。
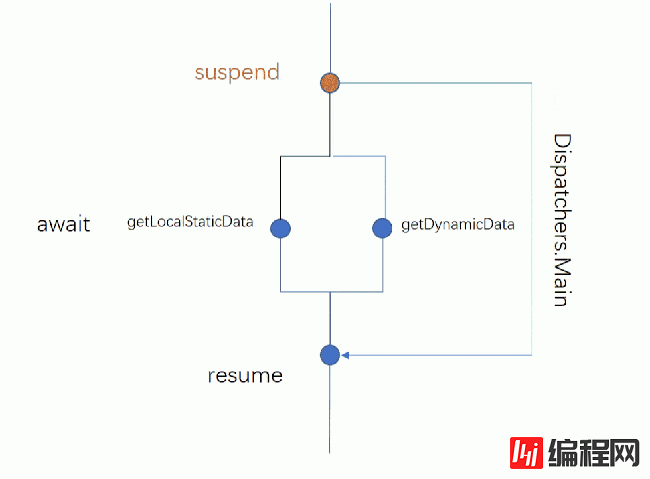
coroutineScope.launch(Dispatchers.Main) { // 在主线程开启一个协程 (1) val data = withContext(Dispatchers.IO) { // 切到IO线程处理耗时操作 (2) handleFileData() // 在IO线程运行 (3) } tvName.text = data // withContext函数体执行完,自定切换到主线程刷新UI (4) }通过 CoroutineScope 的扩展函数 launch 启动了一个运行在 Main 线程的协程,当协程执行到 withContext 挂起函数的时候,withCotext 切到的 IO 线程,执行自身函数体的耗时操作,同时协程后续的代码就会暂停执行,这里也是协程最神奇的地方。
那么后续的代码什么时候执行?协程挂起了,对应的也有恢复的操作,这里就涉及协程的恢复了,当 withContext 挂起函数执行完成之后,协程会重新切回原来的线程(如果挂起前的线程是一个子线程,有可能会因为线程空闲而被回收,切回来的线程并不一定百分百是原来的线程)继续执行剩余的代码,比如示例中刷新UI的操作。
总结一下 Kotlin 协程挂起的概念,什么是挂起?可以理解为两个操作:
协程被“暂停”执行;
协程被“恢复”执行。
另外说一下挂起的非阻塞式:
还是以上面的代码为例,操作(1)在 Main 线程中启动了一个协程,协程执行到操作(2)时,切到 IO 线程中执行操作(3),此时操作(4)被暂停,不执行了,但 Main 线程被阻塞了吗?并没有,主线程该干嘛就干嘛去了,这就是挂起的非阻塞式,虽然被挂起了,但挂起的是自己,是协程,并没有阻塞原来的线程。
本文以核心楼层数据处理进行讲解,该业务需要将兜底数据和接口下发的动态数据进行组装,最终整合成业务所需的数据源。
dependencies { implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.8' } private val scope = MainScope() private fun assembleDataList(response: PlatfORMResponse?) = scope.launch( CoroutineExceptionHandler { _, exception -> }) { val localStaticData: Deferred<MutableList<BaseTemplateEntity>?> = async(start = CoroutineStart.LAZY) { getLocalStaticData() } val dynamicData: Deferred<MutableList<BaseTemplateEntity>?> = async(start = CoroutineStart.LAZY) { getDynamicData(response) } getAssembleDataListFunc(localStaticData.await(), dynamicData.await()) }我们通过作用域构建器扩展函数 launch 在当前的 MainScope 下创建新的协程并启动,在 launch 函数的 lambda 表达式中,我们使用了 async 函数并声明 start 参数设置为 CoroutineStart.LAZY 惰性模式创建一个子协程(但该协程并不会立即执行),该函数会返回一个 Deferred 对象,Deferred 是带有返回值的 Job 扩展(类似于 Java 中的 Futuer 对象),只有当我们主动调用 Deferred 的 await 或 start 函数时,该子协程才会真正执行。
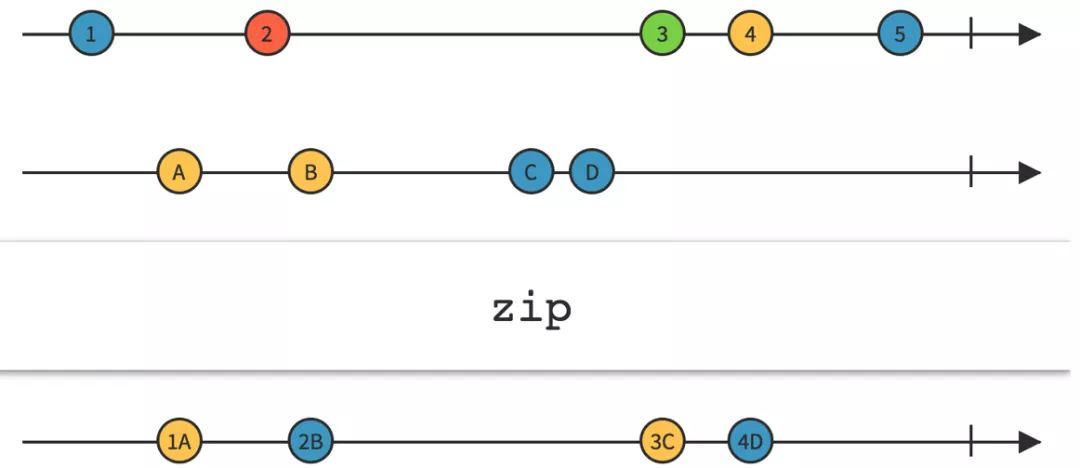
private void assembleDataList(PlatformResponse response) { Observable<List<BaseTemplateEntity>> localStaticData = getLocalStaticData(); Observable<List<BaseTemplateEntity>> assembleData = getDynamicData(response); Func2<List<BaseTemplateEntity>, List<BaseTemplateEntity>, List<BaseTemplateEntity>> assembleData = getAssembleDataListFunc(); Observable<List<BaseTemplateEntity>> observable = Observable.zip(localStaticData, assembleData, assembleData); subscribe(observable, callback); }通过实现代码可以看出,我们使用 zip 操作符,将 localStaticData 和 assembleData 这两个观察者发送的事件序列,在组合后生成一个新的事件序列并发送(此处我们不讨论 localStaticData 和 assembleData 这两个事件序列是串行还是并行执行)。
zip操作符事件流向图(图片来自ReactiveX官网)
对比 针对我们的业务场景,协程和 RxJava 实现方式都能满足我们的需求,那他们之前有什么区别呢:我们先来说一说 RxJava 的优点:解决了 Java 异步实现回调嵌套问题,提高了代码的可读性及维护性;链式调用将事件的配置阶段、运行阶段、订阅阶段的调用变得扁平化;线程调度使得切换线程轻松又优雅。RxJava 的缺点:
Observable firstObservable = Observable.create(new Observable.OnSubscribe<CacheBean>() { @Override public void call(Subscriber<? super CacheBean> subscriber) { if (subscriber != null && !subscriber.isUnsubscribed()) { subscriber.onNext(handleCacheBean()); subscriber.onCompleted(); RxUtil.unSubscribeSafely(subscriber); } } }); Observable secondObservable = Observable.just(new CacheBean(null, "0")); firstObservable.timeout(TIME_OUT, TimeUnit.SECONDS) .onErrorResumeNext(secondObservable) .subscribe();RxJava 的行为并不可预期,太容易出错。如上所示示例中,如果 firstObservable 运行时超时并不会结束 firstObservable 的序列继续发射,如果不调用其 onCompleted() 事件,你会发现订阅事件会先后有接收到2次不同的事件序列,而非我们希望的当超时后只订阅到 secondObservable 发射的事件序列。
RxJava 门槛太高。大部分开发者可能不会过多深入研究,但是如果不了解这些,那么而几乎可以说不可能融会贯通 RxJava 的一些概念,这也就增加了学习成本及维护成本。
背压策略难以理解。
堆栈日志可读性差,增加开发调试成本。
协程的优点:用同步的方式写异步执行的代码,使得代码逻辑更加简洁和清晰;轻量级,占用更少的系统资源;执行效率高;挂起函数较于实现 Runnable 或 Callable 接口更加方便可控;线程切换很简单。协程的缺点:有一定学习成本,由于是基于 Kotlin 语言,需有一定语言基础。
经过协程和 RxJava 的对比,我们也对各框架有所了解,但谈到应该如何选择这个话题,笔者以为如果你已经对 RxJava 重度使用,其实没必要刻意迁移到协程,RxJava 功能强大目前仍是很流行的异步编程框架,基于 RxJava 的拓展库 RxKotlin 也可以满足在 kotlin 语言环境下使用 RxJava 开发。如果你已经有一定 Kotlin 开发经验,又喜欢尝试新鲜事物,协程是个不错的选择,其非阻塞时的挂起可以让开发人员用同步的风格编写异步代码,提高开发效率同时也降低了维护成本。协程的概念越来越普及,尤其已在 Flutter 跨平台框架中广泛使用,势必会成为趋势。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注编程网VUE频道,感谢您对编程网的支持。
--结束END--
本文标题: 如何Kotlin协程用法浅析用在京东APP业务中实践
本文链接: https://lsjlt.com/news/81654.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0