这篇文章将为大家详细讲解有关如何在javascript应用程序中执行语音识别,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。语音识别是计算机科学和计算语言学的
这篇文章将为大家详细讲解有关如何在javascript应用程序中执行语音识别,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。

语音识别是计算机科学和计算语言学的一个跨学科子领域。它可以识别口语并将其翻译成文本,它也被称为自动语音识别(ASR),计算机语音识别或语音转文本(STT)。
机器学习(ML)是人工智能(ai)的一种应用,它使系统能够自动学习并从经验中进行改进,而无需进行明确的编程。机器学习在本世纪提供了大多数语音识别方面的突破。如今,语音识别技术无处不在,例如Apple Siri,Amazon Echo和Google Nest。
语音识别以及语音响应(也称为语音合成或文本到语音(TTS))由WEB speech api提供支持。
在本文中,我们重点介绍JavaScript应用程序中的语音识别。另一篇文章介绍了语音合成。
SpeechRecognition 是识别服务的控制器接口,在Chrome中称为 webkitSpeechRecognition。SpeechRecognition 处理从识别服务发送的 SpeechRecognitionEvent。SpeechRecognitionEvent.results 返回一个SpeechRecognitionResultList 对象,该对象表示当前会话的所有语音识别结果。
可以使用以下几行代码来初始化 SpeechRecognition:
// 创建一个SpeechRecognition对象 const recognition = new webkitSpeechRecognition(); // 配置设置以使每次识别都返回连续结果 recognition.continuous = true; // 配置应返回临时结果的设置 recognition.interimResults = true; // 正确识别单词或短语时的事件处理程序 recognition.onresult = function (event) { console.log(event.results); };ognition.start() 开始语音识别,而 ognition.stop() 停止语音识别,它也可以中止( recognition.abort)。
当页面正在访问您的麦克风时,地址栏中将显示一个麦克风图标,以显示该麦克风已打开并且正在运行。
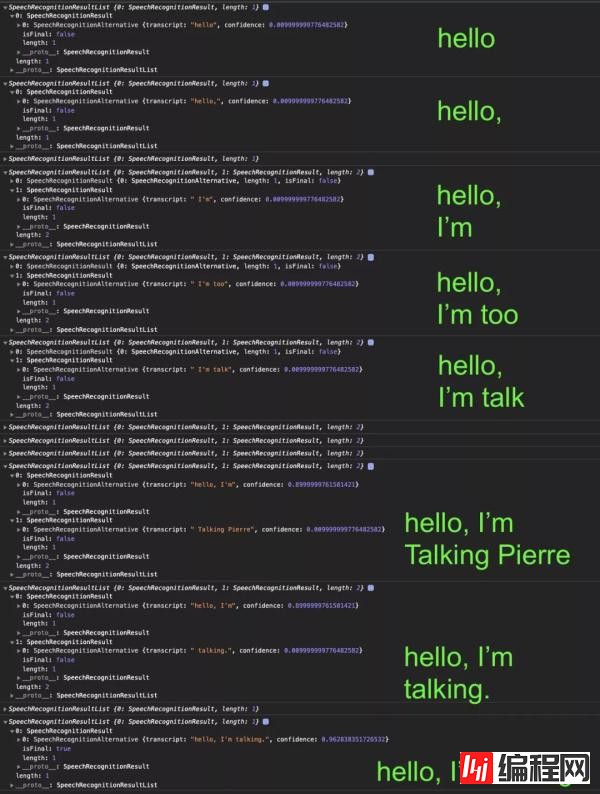
我们用句子对页面说。“hello comma I'm talking period.” onresult 在我们说话时显示所有临时结果。
这是此示例的html代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Speech Recognition</title> <script> window.onload = () => { const button = document.getElementById('button'); button.addEventListener('click', () => { if (button.style['animation-name'] === 'flash') { recognition.stop(); button.style['animation-name'] = 'none'; button.innerText = 'Press to Start'; content.innerText = ''; } else { button.style['animation-name'] = 'flash'; button.innerText = 'Press to Stop'; recognition.start(); } }); const content = document.getElementById('content'); const recognition = new webkitSpeechRecognition(); recognition.continuous = true; recognition.interimResults = true; recognition.onresult = function (event) { let result = ''; for (let i = event.resultIndex; i < event.results.length; i++) { result += event.results[i][0].transcript; } content.innerText = result; }; }; </script> <style> button { background: yellow; animation-name: none; animation-duration: 3s; animation-iteration-count: infinite; } @keyframes flash { 0% { background: red; } 50% { background: green; } } </style> </head> <body> <button id="button">Press to Start</button> <div id="content"></div> </body> </html>第25行创建了 SpeechRecognition 对象,第26和27行配置了 SpeechRecognition 对象。
当一个单词或短语被正确识别时,第28-34行设置一个事件处理程序。
第19行开始语音识别,第12行停止语音识别。
在第12行,单击该按钮后,它可能仍会打印出一些消息。这是因为 Recognition.stop() 尝试返回到目前为止捕获的SpeechRecognitionResult。如果您希望它完全停止,请改用 ognition.abort()。
您会看到动画按钮的代码(第38-51行)比语音识别代码长。这是该示例的视频剪辑:https://youtu.be/5V3bb5YOnj0

以下是浏览器兼容性表:

网络语音识别依赖于浏览器自己的语音识别引擎。在Chrome中,此引擎在云中执行识别。因此,它仅可在线运行。
有一些开源语音识别库,以下是基于npm趋势的这些库的列表:
1. Annyang
Annyang是一个JavaScript语音识别库,用于通过语音命令控制网站。它建立在SpeechRecognition Web API之上。在下一节中,我们将举例说明annyang的工作原理。
2. artyom.js
artyom.js是一个JavaScript语音识别和语音合成库。它建立在Web语音API的基础上,除语音命令外,它还提供语音响应。
3. Mumble
Mumble是一个JavaScript语音识别库,用于通过语音命令控制网站。它建立在SpeechRecognition Web API之上,这类似于annyang的工作方式。
4. julius.js
Julius是面向语音相关研究人员和开发人员的高性能,占用空间小的大词汇量连续语音识别(LVCSR)解码器软件。它可以在从微型计算机到云服务器的各种计算机和设备上执行实时解码。Julis是使用C语言构建的,而julius.js是Julius自以为是JavaScript的移植版。
5.voice-commands.js
voice-commands.js是一个JavaScript语音识别库,用于通过语音命令控制网站。它建立在SpeechRecognition Web API之上,这类似于annyang的工作方式。
Annyang初始化一个 SpeechRecognition 对象,该对象定义如下:
var SpeechRecognition = root.SpeechRecognition || root.webkitSpeechRecognition || root.mozSpeechRecognition || root.msSpeechRecognition || root.oSpeechRecognition;有一些API可以启动或停止annyang:
annyang.start:使用选项(自动重启,连续或暂停)开始监听,例如 annyang.start({autoRestart:true,Continuous:false})。
annyang.abort:停止收听(停止SpeechRecognition引擎或关闭麦克风)。
annyang.pause:停止收听(无需停止SpeechRecognition引擎或关闭麦克风)。
annyang.resume:开始收听时不带任何选项。
这是此示例的HTML代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Annyang</title> <script src="//cdnjs.cloudflare.com/ajax/libs/annyang/2.6.1/annyang.min.js"></script> <script> window.onload = () => { const button = document.getElementById('button'); button.addEventListener('click', () => { if (button.style['animation-name'] === 'flash') { annyang.pause(); button.style['animation-name'] = 'none'; button.innerText = 'Press to Start'; content.innerText = ''; } else { button.style['animation-name'] = 'flash'; button.innerText = 'Press to Stop'; annyang.start(); } }); const content = document.getElementById('content'); const commands = { hello: () => { content.innerText = 'You said hello.'; }, 'hi *splats': (name) => { content.innerText = `You greeted to ${name}.`; }, 'Today is :day': (day) => { content.innerText = `You said ${day}.`; }, '(red) (green) (blue)': () => { content.innerText = 'You said a primary color name.'; }, }; annyang.addCommands(commands); }; </script> <style> button { background: yellow; animation-name: none; animation-duration: 3s; animation-iteration-count: infinite; } @keyframes flash { 0% { background: red; } 50% { background: green; } } </style> </head> <body> <button id="button">Press to Start</button> <div id="content"></div> </body> </html>第7行添加了annyang源代码。
第20行启动annyang,第13行暂停annyang。
Annyang提供语音命令来控制网页(第26-42行)。
第27行是一个简单的命令。如果用户打招呼,页面将回复“您说‘你好’。”
第30行是带有 splats 的命令,该命令会贪婪地捕获命令末尾的多词文本。如果您说“hi,爱丽丝e”,它的回答是“您向爱丽丝致意。”如果您说“嗨,爱丽丝和约翰”,它的回答是“您向爱丽丝和约翰打招呼。”
第33行是一个带有命名变量的命令。一周的日期被捕获为 day,在响应中被呼出。
第36行是带有可选单词的命令。如果您说“黄色”,则将其忽略。如果您提到任何一种原色,则会以“您说的是原色名称”作为响应。
从第26行到第39行定义的所有命令都在第41行添加到annyang中。
我们已经了解了JavaScript应用程序中的语音识别,Chrome对Web语音API提供了最好的支持。我们所有的示例都是在Chrome浏览器上实现和测试的。
在探索Web语音API时,这里有一些提示:如果您不想在日常生活中倾听,请记住关闭语音识别应用程序。
关于如何在Javascript应用程序中执行语音识别就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
--结束END--
本文标题: 如何在Javascript应用程序中执行语音识别
本文链接: https://lsjlt.com/news/81602.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0