这篇文章主要介绍如何实现node.js基于cheerio的爬虫工具,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!先上代码'use strict'; //&n
这篇文章主要介绍如何实现node.js基于cheerio的爬虫工具,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
先上代码
'use strict';
// 引入模块
const superagent = require('superagent');
const cheerio = require('cheerio');
const excel = require('exceljs');
var baseUrl = '';
var Cookies = 'PHPSESSID=1c948cafb361cb5dce87122846e649cd'; //伪装的cookie
let pageDatas = [];
let count = 1;
let limit = 3;
for (count; count < limit; count++) {
baseUrl = `Http://bxjd.henoo.com/policy/policyList?page=${count}`;
loadPage(baseUrl);
}
function loadPage(baseUrl) {
getPageLoad(baseUrl);
}
async function getPageLoad(baseUrl) {
try {
let body = await superagent.get(baseUrl)
.set("Cookie", Cookies)
var $ = cheerio.load(body.text);
var trList = $("#tableList").children("tr");
for (var i = 0; i < trList.length; i++) {
let item = {};
var tdArr = trList.eq(i).find("td");
var id = tdArr.eq(0).text();
item.sortId = id;
var detailUrl = `http://bxjd.henoo.com/policy/view?id=${id}`;
item.policyId = tdArr.eq(1).text();
item.policyProductName = tdArr.eq(2).text();
item.policyName = tdArr.eq(3).text();
item.policyMoney = tdArr.eq(4).text();
let detailBody = await superagent.get(detailUrl)
.set("Cookie", Cookies);
var $$ = cheerio.load(detailBody.text);
var detailT = $$(".table-view");
//投保人证件号
item.policyIdNum = detailT.find("tr").eq(11).find("td").eq(1).text();
//投保人手机号
item.policyPhone = detailT.find("tr").eq(10).find("td").eq(1).text();
//被保人手机号
item.bePoliciedPhone = detailT.find("tr").eq(16).find("td").eq(1).text();
//被保人姓名
item.bePoliciedName = detailT.find("tr").eq(13).find("td").eq(1).text();
console.log(item.bePoliciedName)
//被保人证件号
item.bePoliciedIdNum = detailT.find("tr").eq(17).find("td").eq(1).text();
pageDatas = [...pageDatas,item];
}
if (pageDatas.length / 15 == (count - 1)) {
writeXLS(pageDatas)
}
} catch (error) {
}
}
function writeXLS(pageDatas) {
const workbook = new Excel.Workbook();
const sheet = workbook.addWorksheet('My Sheet');
const reColumns=[
{header:'序号',key:'sortId'},
{header:'投保单号',key:'policyId'},
{header: '产品名称', key: 'policyProductName'},
{header: '投保人姓名', key: 'policyName' },
{header: '投保人手机号', key: 'policyPhone' },
{header: '投保人证件号', key: 'policyIdNum'},
{header: '被保人姓名', key: 'bePoliciedName' },
{header: '被保人手机号', key: 'bePoliciedPhone' },
{header: '被保人证件号', key: 'bePoliciedIdNum' },
{header:'保费',key:'policyMoney'},
];
sheet.columns = reColumns;
for(let trData of pageDatas){
sheet.addRow(trData);
}
const filename = './projects.xlsx';
workbook.xlsx.writeFile(filename)
.then(function() {
console.log('ok');
}).catch(function (error) {
console.error(error);
});
}代码使用方式
一、npm install 相关的依赖二、代码修改
1、修改为自己的baseUrl
2、如果不需要携带cookie时将set("Cookie", Cookies)代码去掉
3、修改自己的业务代码
三、运行 node index四、部分代码说明
所有代码不过90行不到,操作了表格数据获取和单条数据详情的获取

接口请求的框架使用superagent的原因是拼接伪装的cookie的操作比较简单。因为有的时候我们需要获取登录后的页面数据。
这个时候可能需要请求是携带登录cookie信息。返回后的body对象通过cheerio.load之后就能拿到一个类似Jquery的文档对象。
后面就可以很方便的使用jquery的dom操作方式去拿到页面内自己想要的数据了。

数据写入到excel中。
五、结果
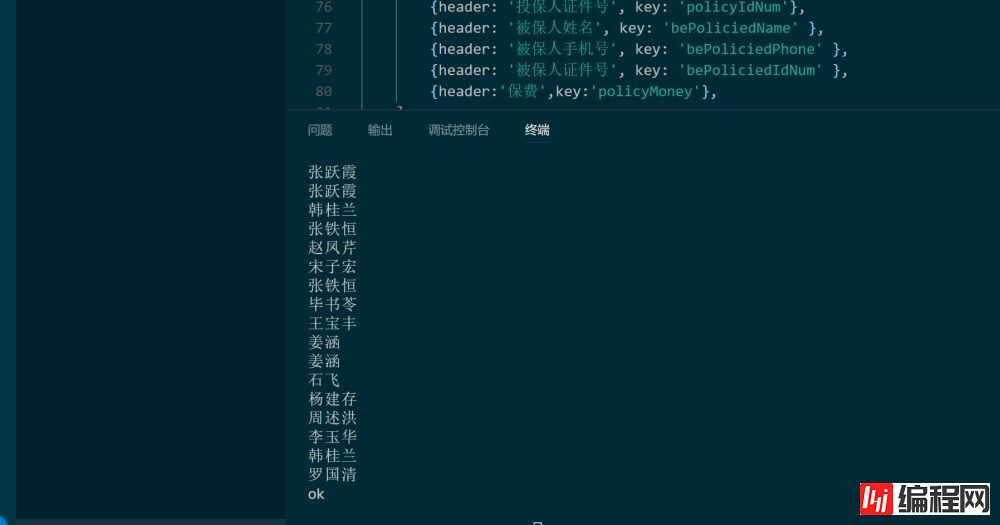
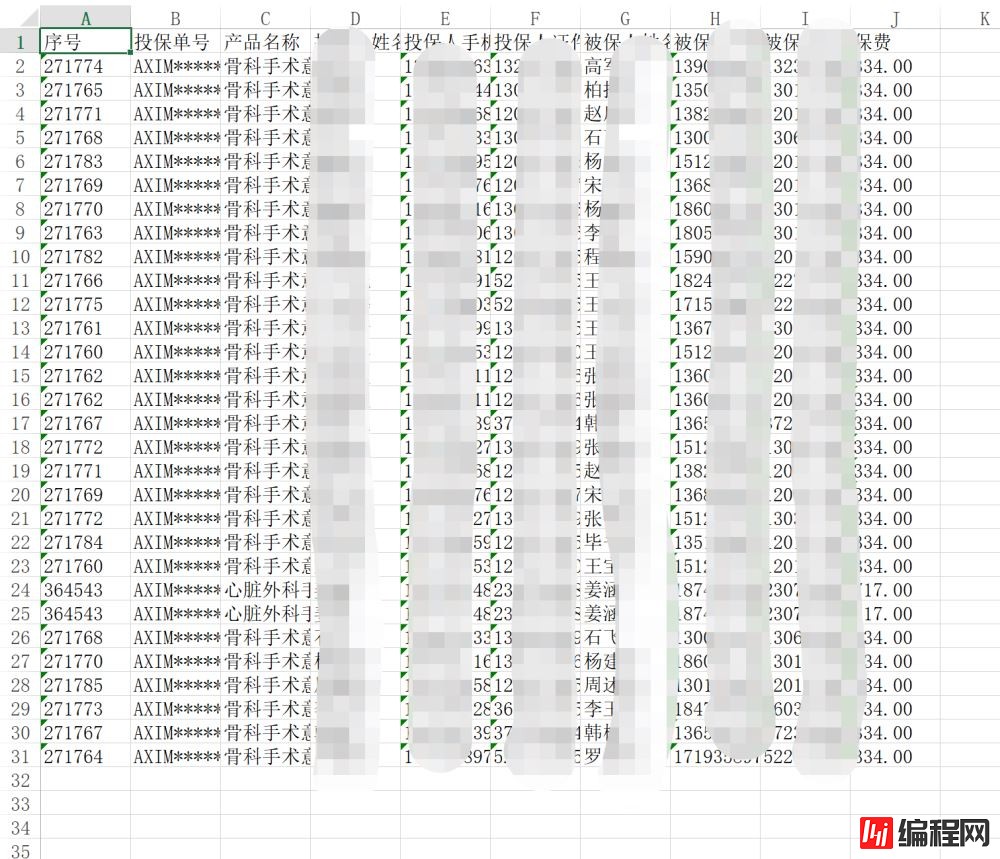
以上是“如何实现node.js基于cheerio的爬虫工具”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注编程网JavaScript频道!
--结束END--
本文标题: 如何实现node.js基于cheerio的爬虫工具
本文链接: https://lsjlt.com/news/77055.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-01-12
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0