开始之前明确一下死锁和锁等待这两个事件的异同相同的之处:两者都是当前事物在试图请求被其他事物已经占用的锁,从而造成当前事物无法执行的现象不同的之处:死锁是相关session双方或者多方中必然要牺牲(回滚)至少一个事务,否则双方
开始之前明确一下死锁和锁等待这两个事件的异同
相同的之处:两者都是当前事物在试图请求被其他事物已经占用的锁,从而造成当前事物无法执行的现象
不同的之处:死锁是相关session双方或者多方中必然要牺牲(回滚)至少一个事务,否则双方(或者多方)都无法执行;锁等待则不然,对于暂时无法申请到的锁,尝试持续地“等待一段时间”,这个等待的时间就是“锁等待”参数决定,超出之后就不等了。 当事物锁等待超时后,当前事物已经持有的锁如何处理,是一个非常考究的问题,
对于Mysql来说,可以选择回滚整个事务,或者是仅回滚当前锁超时的语句,具体参考这里:https://www.cnblogs.com/wy123/p/12724252.html
下文对postgresql中锁超时之后当前Session中事务和语句的处理进行一个验证。
锁等待有可能是发展成死锁,也有可能不是死锁,可能继续等待一段时间之后就可以正常申请到所需要的锁了。
发生死锁的情况下,一定会产生锁等待,因为此时的锁等待没有任何意义,所以必须(立刻)牺牲其中一个事务。
在MySQ中有一个死锁自动检测开关,没有死锁等待时间一说,因为一旦死锁的条件生成,则没有任何缓冲的余地,必须至少牺牲(回滚)其中一个事物,释放其占用的锁,来打断这个死锁的闭环。
但是在Postgresql中,有一个死锁等待事件的参数,默认是1s中,也就是是说Postgresql后台进程会以1s的频率来检测是否存在死锁。
换句话说就是,在Postgresql的死锁检测机制中,不是以mysql中那种实时监测方式来处理死锁的。
为什么postgresql中对于死锁要以类似于定时轮训的方式来实现死锁检测而不是实时监测?
回答这个问题之前,先回到MySQL中:
上面提到MySQL中的死锁自动检测机制是有一个开关的,当然这个开关是可以关闭的,也就是系统不检测死锁信息,那么在死锁发生后也就无法自动牺牲其中一个事务。
那为什么还要允许这个开关设置为关闭呢?其实死锁检测也是需要代价的,尤其是实时监测,参考这里:Https://mp.weixin.qq.com/s/Lc_tQEK55r_syapebSu0Cg,提到过通过关闭死锁检测来提升性能的最佳实践。
然后回到Postgresql中:
在Postgresql中,deadlock_timeout是进行死锁检测之前在一个锁上等待的总时间(以毫秒计)。Postgresql的理念中认为死锁检测代价是比较高的,因此服务器不会在每次等待锁时都运行这个它(是不是死锁)。我们乐观地假设在生产应用中死锁是不常出现的,并且只在开始检测死锁之前等待一会儿。增加这个值就减少了浪费在无用的死锁检测上的时间(频率),但是降低了报告真正死锁错误的速度。默认是 1 秒(1s),这可能是实际中你想要的最小值。在一个高负载的服务器上,你可能需要增大它。这个值的理想设置应该超过你通常的事务时间,这样就可以减少在锁释放之前就开始死锁检查的机会。同理,对于高并发小事务处理系统上,默认的1秒已经足够了。只有超级用户可以更改这个设置。
参考:https://postgresqlco.nf/zh/doc/param/deadlock_timeout/
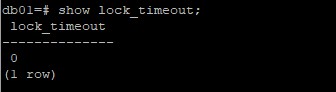
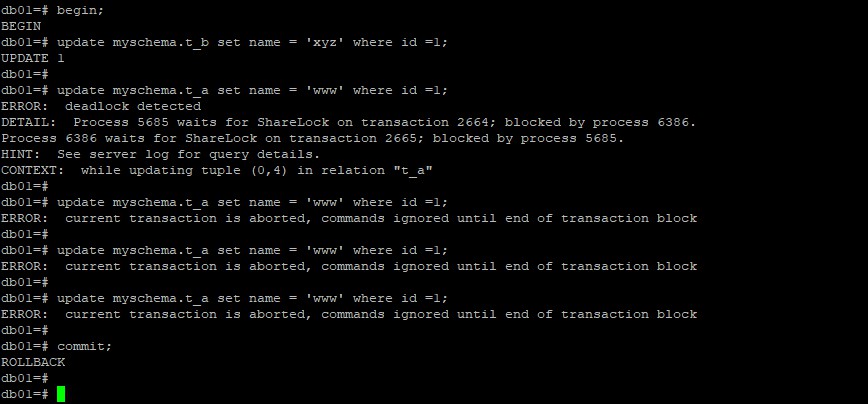
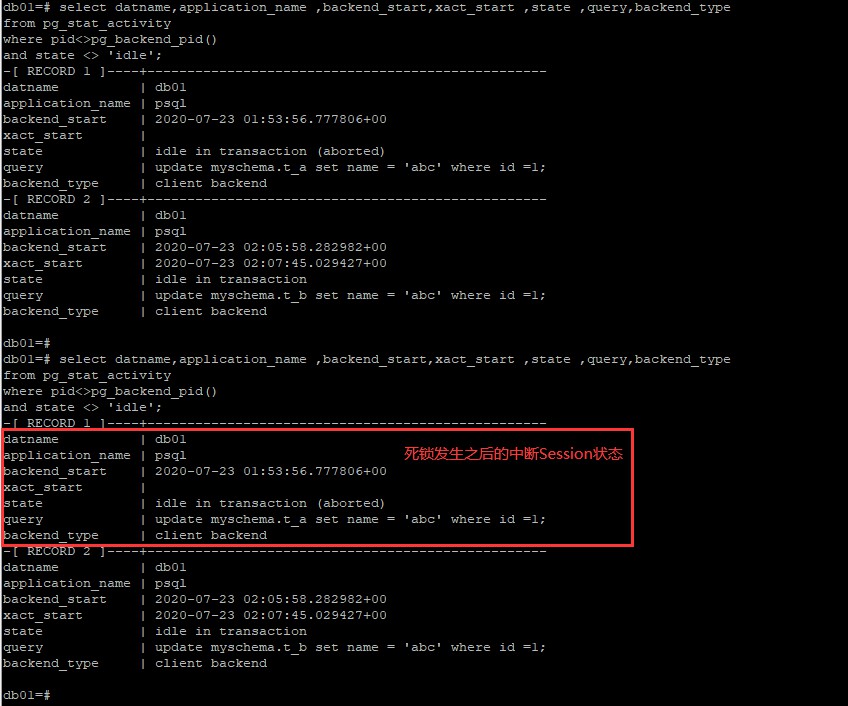 对于锁超时之后当前Session的情况呢,设置一个锁超时的时间
对于锁超时之后当前Session的情况呢,设置一个锁超时的时间

锁超时之后的Session状态
可见,默认情况下,Postgresql在当前Session锁超时之后,会回滚整个事务,而不是当前语句,这样其实更加的科学合理,MySQL也是这么建议的。
--结束END--
本文标题: PostgreSQL中的死锁和锁等待
本文链接: https://lsjlt.com/news/7410.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0