这篇文章主要介绍“Mysql数据库基础知识点有哪些”,在日常操作中,相信很多人在mysql数据库基础知识点有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Mysql数据库
这篇文章主要介绍“Mysql数据库基础知识点有哪些”,在日常操作中,相信很多人在mysql数据库基础知识点有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Mysql数据库基础知识点有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!

原子性 (Atomicity)
整个事务中的所要操作要么全部提交成功,要么全部失败回滚。
一致性(Consistency)
保证数据库中的数据操作之前和操作之后的一致性。(比如用户多个账户之间的转账,但是用户的总金额是不变的)
隔离性(Isolation)
隔离性要求一个事务对数据库中数据的修改,在未提交完成前对于其它事务是不可见的。(即事务之间要串行执行)
持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
SQL标准定义了四种隔离性:(下面隔离性是由低到高,并发性由高到低)
未提交读。
最低的隔离等级,允许其他事务看到没有提交的数据,会导致脏读。
已提交读。
由于数据库是读写分离,事务读取的时候获取读锁,但是在读完之后立即释放,释放读锁之后,就可能被其他事务修改数据,再进行读是就发现前后读取数据的结果不同,造成不可重复读。(读锁不需要事务提交后释放,而写锁需要事务提交后释放。)
可重复读。
所有被select获取的数据都不能被修改,这样就可以避免一个事务前后读取不一致的情况。但是没有办法控制幻读,因为这个时候其他事务不能更改所选的数据,但是可以增加数据;
可串行化。
所有事务一个接着一个执行,这样可以避免幻读,对于基于锁来实现并发控制的数据库来说,串行化要求在执行范围查询的时候,需要获取范围锁,如果不是基于锁实现并发控制的数据库,则检查到有违反串行操作的事务时,需回滚该事务。
总结:四个级别逐渐增强,每个级别解决问题,事务级别越高,性能越差。
隔离级别 脏读 不可重复读 幻读
未提交读(read uncommitted) 可能 可能 可能
已提交读(read committed) 不可能 可能 可能
可重复读(repeatable read) 不可能 不可能 可能
可串行化(serializable) 不可能 不可能 不可能
总结:未提交读会造成脏读—>已提交读解决脏读,但会造成不可重复读—>可重复读解决读取结果前后不一致的情况,但是造成幻读(以前没有,现在有)—>可串行化解决了幻读,但是增加很多范围锁,可能会造成锁超时;
脏读(针对回滚的操作):事务T1更新了一行记录的内容,但是并没有提交所做的修改,事务T2读取更新后的行,然后T1执行了回滚操作,取消了刚才所做的修改。现在T2读取的行数就无效了(一个事务读取了另一个事务);
不可重复读(针对修改的操作):事务T1读取了一行记录,紧接着T2修改了T1刚才读取的那一行记录,然后T1又再次读取这行记录,发现与刚才读取的结果不同。
幻读(针对更新的操作):事务T1读取一条指定的where子句所返回的结果集,然后T2事务新插入一行记录,这行记录恰好可以满足T1所使用的查询条件。然后T1再次对表进行检索,但又看到了T2插入的数据。(第一次没看到,第二次看到了)
可以加快数据库检索速度;
只能创建在表上,不能创建到视图上;
既可以直接创建又可以间接创建;
可以在优化隐藏中使用索引;
使用查询处理器执行sql语句,在一个表上,一次只能使用一个索引。
创建唯一性索引,保证数据库表中每一行数据的唯一性;
大大加快数据检索速度,这是创建索引的最主要原因;
加速数据库表之间的链接,特别是在实现数据库参考完整性方面特别有意义;
在使用分组和排序子句进行检索时,同样可以显著减少查询中分组和排序的时间;
通过使用索引,可以在查询中使用优化隐藏器,提高系统性能;
创建和维护索引耗费时间,这种时间随着数量的增加而增加;
索引需要占用物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果建立聚集索引,那么需要的空间就会更大;
当对表中的数据进行增加、删除和修改的时候,索引也需要维护,降低数据维护速度;
(1)普通索引(它没有任何限制。)
(2)唯一性索引(索引列的值必须唯一,但允许有空值。)
(3)主键索引(一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。)
(4)组合索引
(5)聚集索引 按照每张表的主键构造一颗B+树,并且叶节点中存放着整张表的行记录数据,因此也让聚集索引的叶节点成为数据页。
(6)非聚集索引(辅助索引)(页节点不存放一整行记录)。
(1)如果条件中有or,即使其中有条件带索引,也不会使用(尽量少用or);
(2)Like查询是以%开头,例如SELECT * FROM mytable WHEREt Name like’%admin’;
(3)如果列类型是字符串,那一定要在条件中使用引号引起来,否则不会使用索引;
MyISAM,InnoDB,Memonry三个常用MySQL引擎类型比较:
索引 MyISAM索引 InnoDB索引 Memonry索引
B-tree索引 支持 支持 支持
Hash索引 不支持 不支持 支持
R-Tree索引 支持 不支持 不支持
Full-text索引 不支持 暂不支持 不支持
因为在使用二叉树的时候,由于二叉树的深度过大而造成I/O读写过于频繁,进而导致查询效率低下。因此采用多路树结构,B树的各种操作能使B树保持较低的高度。
B树又叫平衡多路查找树,一棵m阶的B树特性如下:
1.树中每个结点最多含有m个孩子(m>=2);
2.除根结点和叶子结点外,其他每个结点至少有(ceil(m/2))个孩子(其中ceil(x)是一个取上限的函数);
3.根结点至少有2个孩子(除非B树只包含一个结点:根结点);
4.所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,指向这些结点的指针都为null);(注:叶子结点只是没有孩子和指向孩子的指针,这些结点也存在,也有元素,类似红黑树中,每一个null指针即当做叶子结点,只是没画出来而已)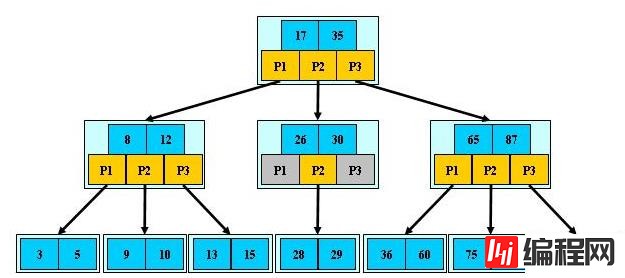
B+树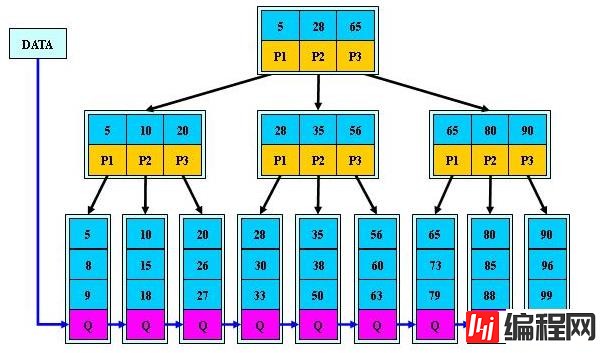
在什么情况下适合建立索引?
(1)为经常出现在关键字order by, group by, distinct后面的字段,建立索引;
(2)在uNIOn等集合操作的结果集字段上建立索引,其建立索引的目的同上;
(3)为经常用作查询选择的字段,建立索引;
(4)在经常用做表链接的属性上,建立索引;
(5)考虑使用索引覆盖,对数据很少被更新的表,如果用户经常只查询其中的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描改变为索引的扫描。
即当sql中存在下面的关键字时,它们要保持这样的顺序:
select[distinct]、from、join(如left join)、on、where、group
by、having、union、order by、limit;
即在执行时sql按照下面的顺序进行执行:
from、on、join、where、group by、having、select、distinct、union、order by
group by要和聚合函数一起使用,
例如:
select a.Customer,sum(a.OrderPrice) from orders a where a.Customer=’Bush’ or a.Customer = ‘Adams’ group by a.Customer;实现多表查询(内连接)
select u.uname,a.addr from lm_user u inner join lm_addr a on u.uid = a.uid;使用select from where同样可以实现
select u.uname,a.addr from lm_user u, lm_addr a where u.uid = a.uid;delimiter $$
create procedure procedure_bill()
comment '查询所有销售情况'
begin
select billid, tx_time, amt from lm_bill;
end $$
delimiter ;调用存储过程
call procedure_bill();查看存储过程
show procedure status like 'procedure_bill';在数据库中,如果两个表的之间的关系为多对多的关系,如:“学生表和课程表”,一个学生可以选多门课,一门课也可以被多个学生选;根据数据库的设计原则,应当形成第三张关联表。
步骤1:创建三张数据表Student ,Course,Stu_Cour
CREATE TABLE Student (
stu_id INT AUTO_INCREMENT,
NAME VARCHAR(30),
age INT ,
class VARCHAR(50),
address VARCHAR(100),
PRIMARY KEY(stu_id)
)
CREATE TABLE Course(
cour_id INT AUTO_INCREMENT,
NAME VARCHAR(50),
CODE VARCHAR(30),
PRIMARY KEY(cour_id)
)
CREATE TABLE Stu_Cour(
sc_id INT AUTO_INCREMENT,
stu_id INT ,
cour_id INT,
PRIMARY KEY(sc_id)
)第二步:为Stu_Cour关联表添加外键
ALTER TABLE Stu_Cour ADD CONSTRaiNT stu_FK1 FOREIGN KEY(stu_id) REFERENCES Student(stu_id);
ALTER TABLE Stu_Cour ADD CONSTRAINT cour_FK2 FOREIGN KEY(cour_id) REFERENCES Course(cour_id);完成创建!
注:为已经添加好的数据表添加外键:
-语法:alter table 表名 add constraint FK_ID foreign key(你的外键字段名) REFERENCES 外表表名(对应的表的主键字段名);
例: alter table tb_active add constraint FK_ID foreign key(user_id) REFERENCES tb_user(id);
当你访问数据库时,不管是手工访问,还是程序访问,都不是直接读写数据库文件,而是通过数据库引擎去访问数据库文件。
以关系型数据库为例,发SQL语句给数据库引擎,数据库引擎解释SQL语句,提取出你需要的数据返回给你。因此,对访问者来说,数据库引擎就是SQL语句的解释器。
主要区别:
MYISAM 是非事务安全型的,而InnoDB是事务安全型;
NYISAM锁的粒度是表级锁,而InnoDB支持行级锁;
MYISAM支持全文本索引,而InnoDB不支持全文索引
MYISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MYISAM;
MYISAM表是保存成文件的形式,在跨平台的数据转移中使用MYISAM存储会省去不少的麻烦;
(6)InnoDB表比MYISAM表更安全,可以在保证数据不丢失的情况下,切换非事务表到事务表;
应用场景:
MYISAM管理非事务表,它提供高速存储和检索,以及全文搜索能力,如果应用中需要执行大量的select查询,那么MYISAM是更好的选择。
InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的insert或update操作,则应该使用innodb,这样可以提高多用户并发操作的性能。
目前关系数据库有6种范式:第一范式{1NF},第二范式{2NF},第三范式{3NF},巴斯—科德范式{BCNF},第四范式{4NF},第五范式{5NF,又称完美范式}。满足最低要求的范式是第一范式。在第一范式的基础上进一步满足更多规范要求的称为第二范式{2NF},其余范式依次类推,一般来说,数据库只需满足第三范式(3NF)就OK了。
范式:
1NF:确保每列保持原子性;
2NF:确保表中的每列都和主键相关(联合主键);
3NF:确保表中的每列都和主键直接相关(外键);
BCNF:在1NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖);
4NF:要求把同一表内的多对多关系删除;
5NF:从最终结构重新建立原始结构;
到此,关于“MySQL数据库基础知识点有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: MySQL数据库基础知识点有哪些
本文链接: https://lsjlt.com/news/72378.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0