这篇文章给大家介绍如何深入了解Redis中的Codis,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。场景在大数据高并发场景下,使用单个redis实例,即使redis的性能再高,也会变的
这篇文章给大家介绍如何深入了解Redis中的Codis,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
在大数据高并发场景下,使用单个redis实例,即使redis的性能再高,也会变的非常吃力,
首先,数据量越大,redis占用内存就越大,进一步导致rdb文件过大,这种情况会使的主从全量同步时间过长,同时实例重启时,加载过大的rdb也会让启动时间变长。【相关推荐:Redis视频教程】
其次在CPU的使用上,单个实例的Redis只能使用一个CPU核心,一个核心应多过多的数据,也会显得力不从心,
因此需要一个集群方案,将巨大的数据量由一台实例分散到多台实例上,从Redis流行到官方支持自己的Cluster方案之间,第三方也在自己开发支持集群的组件,Codis就是其中之一,
Codis使用Go语言开发,在Redis与客户端中间充当代理的角色,使用Redis协议,所以客户端直接连接Codis,向其发送指令即可,Codis负责转发指令给Redis,最后接收返回结果再返回给客户端,
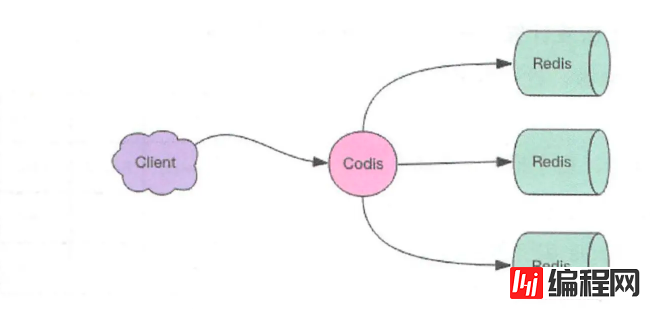
Codis代理的Redis实例构成一个Redis集群,当集群空间也不足以使用时,可以动态扩容,继续增加Redis实例,与此同时,客户端使用的sdk不需要做任何改动,只需由原来的连接redis改成连接codis即可,
Codis自身也可以采取一个集群,来保证自身的高可用,由于其本身就是无状态的,只负责转发内容,增加多个Codis没有副作用还可以保证QPS的提高,当其中一个Codis挂掉时,还可以使用别的。
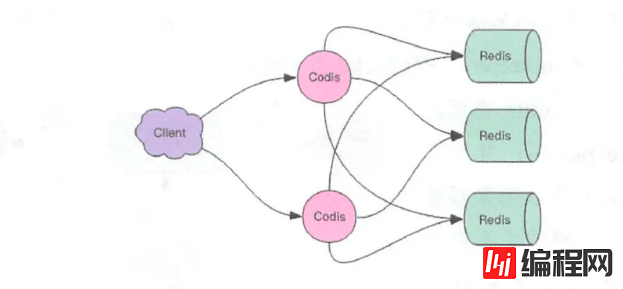
Codis将特定的Key转发到特定的Redis实例,集群中每个实例都保存一部分Key,降低其他实例的压力,同时所有实例的数据加起来,就是一份完整的信息。
Codis默认划分了1024个槽位(slot),集群中的每个Redis实例对应一部分槽位,Codis会在内存中维护槽位与Redis实例的对应关系,
槽位的数量默认是1024,可以更改,如果集群节点比较多,可以将数字调大。
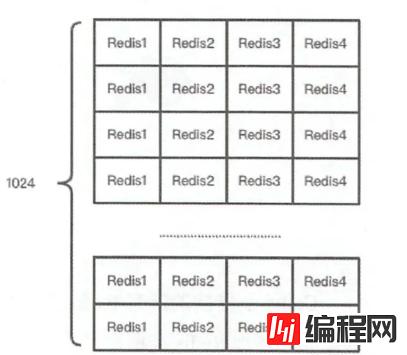
当接收到客户端发送过来的key时,Codis对该key进行 crc32 运算得出一个 hash 值,
再将 hash 后的整数值对 1024(槽位数量) 进行取模得到一个余数,该余数就是Key将被保存到的槽位,有了槽位就可以找到这个key该发到哪个redis实例上了。
伪代码:
hash = crc32(command.key) # 计算hash值
slot = hash % 1024 # 取模得到槽位
redisInstance = slots[slot].redis # 得到redis实例
redis.do(command) # 执行命令复制代码集群槽位同步
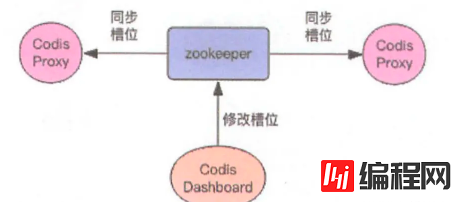
Redis与槽位的映射关系存在Codis的内存当中,因此Codis集群需要考虑保证每个节点中的槽位映射关系同步,所以Codis采用 ZooKeeper、Etcd 分布式配置存储中间件来持久化槽位映射关系,保证Codis集群之间的数据同步,
如下图,Codis将槽位关系存在Zookeeper中,并提供了一个Dashboard 观察与修改槽位关系,当发生改变时,Codis Proxy 监听到变化并重新同步槽位关系。
拓容
当现有集群也不满足业务需求时,就需要新增实例加入到的集群中,此时槽位映射关系需要进行重新分配,需要分配一部分的槽位给新节点。
Codis新增了一个 SLOTSSCAN 指令,可以遍历指定slot下的所有key,通过该指令扫描出待迁移槽位的所有key,然后挨个遍历每个key迁移到新节点中,
迁移过程中,Codis继续对外提供服务,此时来了一个请求打在了正在迁移的槽位上,由于该槽位现在对应新老两个节点,此时 Codis 无法判断该 key 有没有从旧节点中迁移到新节点上,
因此这种情况 Codis 会立即强制对当前的 key 进行单个迁移,迁移完成后,将请求转发给新的Redis实例上。
伪代码:
slot_index = crc32(command.key) % 1024
if slot_index in migrating_slots:
doMigratingKey(command.key)
redis = slots[slot_index].new_redis
else:
redis = slots[slot_index].redis复制代码SLOTSSCAN 与 Redis自身的Scan指令一样,无法避免扫描出来的数据重复,但这不会影响到迁移的正确性,因为单个key迁移之后,就立刻从旧实例中删除了,无法再被扫描出来。
自动均衡槽位
每次新增实例,如果都需要人工维护slot的映射关系太麻烦,Codis提供自动均衡,该功能会在系统比较空闲的时候观察每个Redis实例对应的slot数量,如果不平衡,就进行自动均衡,迁移数据的操作。
缺点
Codis给Redis带来扩容好处,但也造成了一些副作用。
不支持事务
一个事务可能对多个key做了操作,但事务只能在单个实例中完成,但是由于key分散在不同的实例中,因此Codis无法支持事务操作。
不支持rename
rename将一个key命名成另一个key,但是这两个key可能hash出来的槽位并不是同一个,而是在不同实例的槽位上,因此rename也不被支持。
官方提供的不支持的指令列表:https://GitHub.com/CodisLabs/codis/blob/master/doc/unsupported_cmds.md
扩容卡顿
Codis在扩容过程中,对数据的迁移是将整个key直接迁移过去的,例如一个hash结构,Codis会直接 hgetall 拉取所有的内容,使用 hmset 放到 新节点中,
如果该hash的内容过大,将会引起卡顿,官方建议单个集合结构的总大小不超过1MB,在业务上可以通过分桶存储等,将大型数据拆成多个小的,做一个折中。
网络开销
由于 Codis 在 客户端与Redis实例之间充当网络Proxy,多了一层,网络开销自然多一些,比直接连接Redis的性能要稍低一些。
中间件运维开销
Codis集群配置需要使用Zk或Etcd,这意味着引入Codis集群又要引入其他中间件,增加运维机器资源成本。
优点
Codis将分布式一致性的问题交给了第三方(ZK或Etcd)负责,省去了这方面的维护工作,降低实现代码的复杂性,
Redis官方的Cluster为了实现去中心化,引入了Raft与Gossip协议,以及大量需要调优的配置参数,复杂度骤增。
批量获取
对于批量操作,例如使用 mget 获取多个key的值,这些key可能分散在多个实例中,Codis将key按照所在的实例进行分组,然后对每个实例挨个调用 mget,最后汇总返回给客户端。
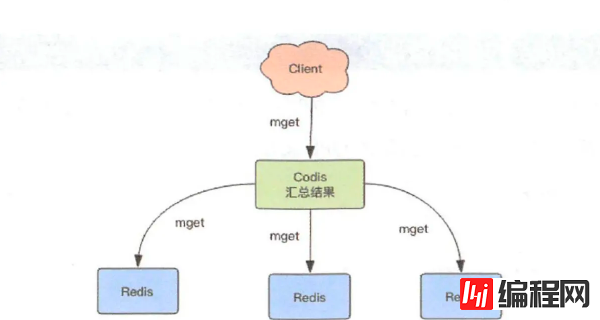
其他功能
Codis 提供 Dashboard 界面化,以及 Codis-fe 对集群进行管理,还可以进行增加分组、节点、执行自动均衡等操作,查看 slot 状态以及 slot 对应的 redis 实例,这些功能使的运维更加方便轻松。

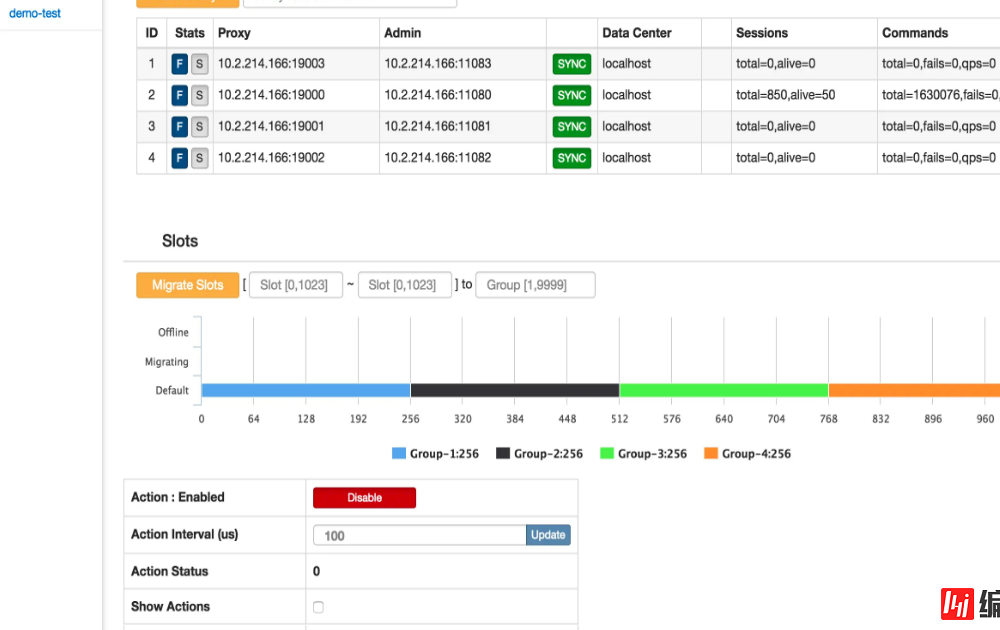
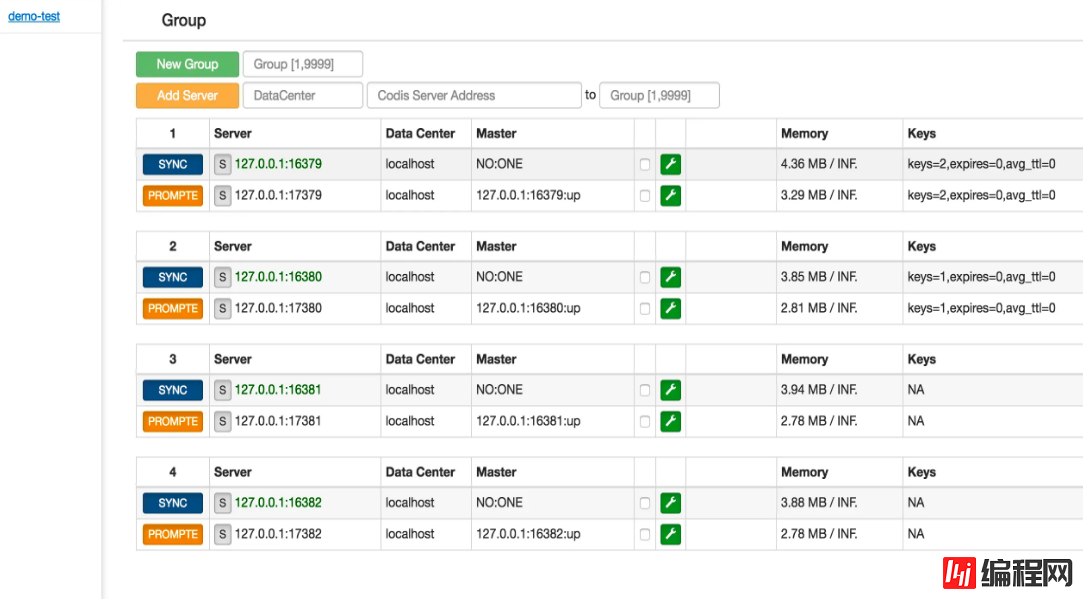
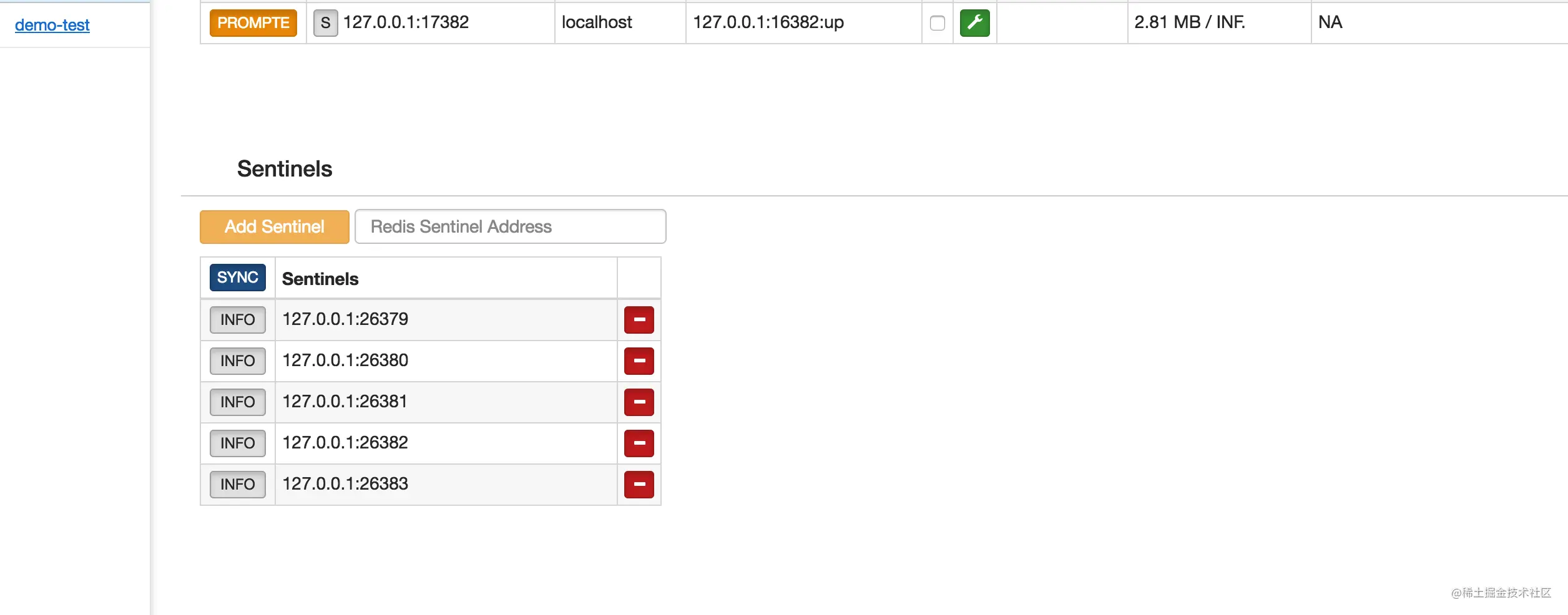
Codis是为了弥补Redis官方没有提供集群这一概念时出现的,现在Redis官方提供Cluster功能,官方的支持自然比第三方的更有优势,
同时第三方软件还需要实时关注官方发布的新特性各种,而Cluster肯定是实时兼容新特性,因此更推荐使用官方的Cluster,Codis作为曾经的一个知识点了解,某些思想与Cluster是有重合的。
关于如何深入了解Redis中的Codis就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
--结束END--
本文标题: 如何深入了解Redis中的Codis
本文链接: https://lsjlt.com/news/71162.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0