这篇文章主要介绍“Mysql的ref有什么用”,在日常操作中,相信很多人在mysql的ref有什么用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Mysql的ref有什么用”
这篇文章主要介绍“Mysql的ref有什么用”,在日常操作中,相信很多人在mysql的ref有什么用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Mysql的ref有什么用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
回忆一下查询成本
对于一个查询来说,有时候可以通过不同的索引或者全表扫描来执行它,MySQL优化器会通过事先生成的统计数据,或者少量访问B+树索引的方式来分析使用各个索引时都需要扫描多少条记录,然后计算使用不同索引的查询成本,最后选择成本最低的那个来执行查询。
创建场景
假如我们现在有一个表t,它的表结构如下所示:
CREATE TABLE t ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, key1 VARCHAR(100), common_field VARCHAR(100), INDEX idx_key1 (key1) ) ENGINE=InnoDB CHARSET=utf8;这个表包含3个列:
id列是自增主键
key1列用于存储字符串,我们为key1列建立了一个普通的二级索引
common_field列用于存储字符串
现在该表中共有10000条记录:
mysql> SELECT COUNT(*) FROM t; +----------+ | COUNT(*) | +----------+ | 10000 | +----------+ 1 row in set (2.65 sec)其中key1列为'a'的记录有2310条:
mysql> SELECT COUNT(*) FROM t WHERE key1 = 'a'; +----------+ | COUNT(*) | +----------+ | 2310 | +----------+ 1 row in set (0.83 sec)key1列在'a'到'i'之间的记录也有2310条:
mysql> SELECT COUNT(*) FROM t WHERE key1 > 'a' AND key1 < 'i'; +----------+ | COUNT(*) | +----------+ | 2310 | +----------+ 1 row in set (1.31 sec)现在我们有如下两个查询:
查询1:SELECT * FROM t WHERE key1 = 'a'; 查询2:SELECT * FROM t WHERE key1 > 'a' AND key1 < 'i';按理说上边两个查询需要扫描的记录数量是一样的,MySQL查询优化器对待它们的态度也应该是一样的,也就是要么都使用二级索引idx_key1执行它们,要么都使用全表扫描的方式来执行它们。不过现实是貌似查询优化器更喜欢查询1,而比较讨厌查询2。查询1的执行计划如下所示:
# 查询1的执行计划 mysql> EXPLaiN SELECT * FROM t WHERE key1 = 'a'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t partitions: NULL type: ref possible_keys: idx_key1 key: idx_key1 key_len: 303 ref: const rows: 2310 filtered: 100.00 Extra: NULL 1 row in set, 1 warning (0.04 sec)查询2的执行计划如下所示:
# 查询2的执行计划 mysql> EXPLAIN SELECT * FROM t WHERE key1 > 'a' AND key1 < 'i'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t partitions: NULL type: ALL possible_keys: idx_key1 key: NULL key_len: NULL ref: NULL rows: 9912 filtered: 23.31 Extra: Using where 1 row in set, 1 warning (0.03 sec)很显然,查询优化器决定使用idx_key1二级索引执行查询1,而使用全表扫描来执行查询2。
为什么?凭什么?同样是扫描相同数量的记录,凭什么我range访问方法就要比你ref低一头?设计MySQL的大叔,你为何这么偏心...
解密偏心原因
世界上没有无缘无故的爱,也没有无缘无故的恨。这事儿还得从索引结构说起。比方说idx_key1二级索引结构长这样:
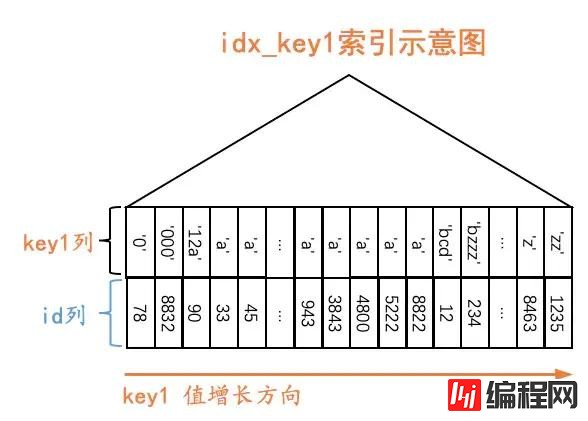
原谅我们把索引对应的B+树结构弄了一个极度精简版,我们忽略掉了页的结构,只保留了叶子节点的记录。虽然极度精简,但是我们还是保留了一个极其重要的特性:B+树叶子节点中的记录是按照索引列的值从小到大排序的。对于二级索引idx_key1来说:
二级索引叶子节点的记录只保留key1列和id列
二级索引记录是先按照key1列的值从小到大的顺序进行排序的。
如果key1列的值相同,则按照主键值,也就是id列的值从小到大的顺序进行排序。
也就是说,对于所有key1值为'a'的二级索引记录来说,它们都是按照id列的值进行排序的。对于查询1:
查询1: SELECT * FROM t WHERE key1 = 'a';由于查询列表是* ,也就是说我们需要通过读取到的二级索引记录的id值执行回表操作,到聚簇索引中找到完整的用户记录(为了去获取common_field列的值)后才可以将记录发送到客户端。对于所有key1列值等于'a'的二级索引记录,由于它们是按照id列的值排序的,所以:
前一次回表的id值所属的聚簇索引记录和下一次回表的id值所属的聚簇索引记录很大可能在同一个数据页中
即使前一次回表的id值所属的聚簇索引记录和下一次回表的id值所属的聚簇索引记录不在同一个数据页中,由于回表的id值是递增的,所以我们很大可能通过顺序I/O的方式找到下一个数据页,也就是说这个过程中很大可能不需要很大幅度的移动磁头就可以找到下一个数据页。这可以减少很多随机I/O带来的性能开销。
综上所述,执行语句1时,回表操作带来的性能开销较小。
而对于查询2来说:
查询2: SELECT * FROM t WHERE key1 > 'a' AND key1 < 'i';由于需要扫描的二级索引记录对应的id值是无序的,所以执行回表操作时,需要访问的聚簇索引记录所在的数据页很大可能就是无序的,这样会造成很多随机I/O。所以如果使用idx_key1来执行查询1和查询2,执行查询1的成本很显然会比查询2低,这也是设计MySQL的大叔更钟情于ref而不是range的原因。
MySQL的内部实现
MySQL优化器在计算回表的成本时,在使用二级索引执行查询并且需要回表的情境下,对于ref和range是很明显的区别对待的:
对于range来说,需要扫描多少条二级索引记录,就相当于需要访问多少个页面。每访问一个页面,回表的I/O成本就加1。
比方对于查询2来说,需要回表的记录数是2310,因为回表操作而计算的I/O成本就是2310。
对于ref来说,回表开销带来的I/O成本存在天花板,也就是定义了一个上限值:
double worst_seeks;这个上限值的取值是从下边两个值中取较小的那个:
比方对于查询1来说,回表的记录数是2310,按理说计算因回表操作带来的I/O成本也应该是2310。但是由于对于ref访问方法,计算回表操作时带来的I/O成本时存在天花板,会从全表记录的十分之一(也就是9912/10=991,9912为估计值)以及聚簇索引所占页面的3倍(本例中聚簇索引占用的页面数就是97,乘以3就是291)选择更小的那个,本例中也就是291。
全表记录数的十分之一(此处的全表记录数属于统计数据,是一个估计值)
聚簇索引所占页面的3倍
小贴士:在成本分析的代码中,range和index、all是被分到一类里的,ref是亲儿子,单独分析了一波。不过我们也可以看到,设计MySQL的大叔在计算range访问方法的代价时,直接认为每次回表都需要进行一次页面I/O,这是十分粗暴的,何况我们的实际聚簇索引总共才97个页面,它却将回表成本计算为2310,这也是很不精确的。
到此,关于“MySQL的ref有什么用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: MySQL的ref有什么用
本文链接: https://lsjlt.com/news/69478.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0