本篇内容主要讲解“Mysql中的锁怎么理解”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“mysql中的锁怎么理解”吧!01. 怎么认识"锁"
本篇内容主要讲解“Mysql中的锁怎么理解”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“mysql中的锁怎么理解”吧!
01. 怎么认识"锁"
02. "锁"的分类
按照加锁思想不同,可区分乐观锁(optimistic locking)和悲观锁(pessimistic locking)——这是一个虚构的概念
按照加锁策略,可分为记录锁(record locking)、间隙锁(gap locking)和临键锁(next-key locking),其中临键锁=记录锁+间隙锁
按照加锁粒度,可分为行锁(row-level locking)和表锁(table-level locking),其中InnoDB可以加行锁,也可以加表锁;MyISAM只能加表锁
按照加锁影响,可区分共享锁(share locking,S锁)和排他锁(exclusive locking,X锁),二者又分别称作读锁和写锁
事务加锁之前要先发出"请求",所以就产生了意向锁(intention locking),相当于是向引擎发出一个加锁的意向:又可细分为共享意向锁(intention share locking,IS)和排他意向锁(intention exclusive locking,IX),请求成功(请求加锁的目标未被占用)则变成相应的S锁或X锁,否则便处于等待状态或者超时退出。
03. 加"锁"过程
加锁过程一般分为两个阶段,即加锁(locking phase)和解锁(unlocking phase),所以也叫两阶段锁(two-phase locking)
锁的作用范围是事务,所以加锁只能在开启事务之后由某些sql语句触发,而当提交事务或回滚时释放锁
04. 给谁加"锁"
不是所有的SQL语句都加锁,例如DDL(数据定义语言)和DCL(数据控制语言)因不涉及事务,自然不存在锁的问题
也不是所有的DQL(特指数据查询语言,形如select……)都加锁,例如普通的select语句都不加锁,而是依靠mvcC(multi-version concurrency control,即多版本并发控制)来实现事务的"某种"一致性
普通select语句不加锁,如想加锁只需在select语句后明确指定"for share"或"for update"即可,其中前者就是共享锁(S锁),也叫读锁;后者是排他锁(X锁),也叫写锁
但是所有的DML语句(数据操作语言,insert、update和delete)都会自动加锁,而且加的是排他锁(X锁)
05. 加"锁"目的
加锁的目的是为了数据库的稳定性和一致性,但其副作用是降低了并发能力,所以加锁策略往往要在一致性(consistency)和并发能力(concurrency)间折中
加锁是为了权衡数据一致性和并发能力,MySQL中不加锁实现这一机制的方法是MVCC,即大名鼎鼎的多版本并发控制;与之对应,加锁实现的并发机制则叫做LBCC(locking-based concurrency control)
06. 加"锁"对象
表锁,是对整个表进行锁定,如果是虚拟的视图(view)、触发器(trigger),则会将其关联的所有表进行锁定
行锁,实际锁的对象不是行,而是按索引锁定,也就是说锁不会定位到某条记录,而是通过限制索引来间接作用到记录
07. "锁"和事务
SQL通用标准定义了事务的ACID四大属性,即原子性Atomcity,一致性Consistency,隔离性Isolation,持久性Durability
为了实现隔离性进而确保一致性,需要实现事务;事务的实现又依赖于存储引擎,MySQL的两种常用引擎中,默认引擎InnoDB支持事务,而MyISAM则不支持
前面提到,普通的查询语句不加任何锁,此时innoDB引擎依靠MVCC机制实现数据库的隔离性和一致性。MVCC,简单的说就是对可能存在并发和争议的记录增加带有版本信息的隐藏字段,例如时间戳,来确保多次查询数据的一致性
一致性的状态又具体因隔离级别不同而异,SQL92标准(数据库通用标准,非MySQL独有)定义了四大隔离等级:
a. 读未提交(Read Uncommitted,RU),即一个事务可以读到其他事务已操作但未提交的数据,当这个操作回滚时,即发生脏读
b. 读已提交(Read Committed,RC),即一个事务仅能读到其他事务已提交的数据,确保这个数据是实实在在真实的数据,避免了脏读,但可能导致本事务窗口内前后查询结果不一致,即不可重复读
c. 可重复读(Repeatable Read,RR),即可重复读,基于MVCC机制,在当前事务中的首次查询时,记录一个快照版本,同一事务期间的后续查询均采用当前快照版本的结果,所以即使是其他事务已提交的数据,但若其快照版本在本事务首次快照版本之后,也不会读出来。注意,这里当前事务采集的快照"版本号"取决于首次查询的时机,而不是开始事务的时机。
d. 串行化(Serializable, SE),严格限制并发,多个事务间在存在数据竞争时串行执行,数据稳定性和一致性最强,但并发能力受到极大限制。注意,这里是指存在数据冲突时事务间串行,否则仍可并发
不是所有的数据库都必须包含这4种隔离级别(例如oracle数据库主要支持RC和SE两个隔离级别),不同数据库实现的方式也不尽相同。MySQL支持全部4个隔离级别,默认为RR级别
默认情况下,MySQL执行的每条SQL语句都是自动提交的,如果想显式的执行事务,有两种方法:
1## 开启事务2种方法 2-- 一种是显式开启事务 3START TRANSACTION / BEGIN 4-- 另一种是关闭自动提交 5SET autocommit = 0 6 7## 结束事务 8COMMIT / ROLLBACK对于未显式开启事务的SQL语句,可将其看做是在语句前后分别自动开启和提交事务,即:
1select ……; 2等价于 3START TRANSACTION; 4selece ……; 5COMMIT;08."读象"
read phenomena,官方文档给出的英文写法,未找到相关权威翻译名词。特指MySQL读取过程中存在的副作用,例如脏读、幻读等
read phenomena,主要是指数据库中三种"错误"的读取结果:
脏读:dirty read,即A事务读取了B事务更改但未提交的信息,主要发生在RU隔离级别
不可重复读,non-repeatable read,即由于B事务在A事务期间对数据更改并已提交,导致A事务前后读取到不一致的结果
幻读,phantom read,即A事务在之后的查询中出现了前期未出现的记录。
鉴于部分资料对幻读和不可重复读解释很乱,这里再说下幻读和不可重读区别:
不可重复读,顾名思义,是指前后两次读取结果不一致,这里的不一致涵盖的范围很广,换言之只要前后不一致就都属于不可重复读。造成原因主要是一项事务在执行期间,其他事务对数据表进行了更改并提交(如果未提交就能读到那么性质更恶劣,属于脏读),主要发生在RC隔离级别,因为RC意味着"读已提交",所以但凡其他事务已提交的数据更新该事务都能察觉到,前后结果当然可能不一致
而幻读,顾名思义,是指读到了之前未曾发现的记录,当然,从某种意义上将之前未曾发觉肯定也属于不可重复读,这样理解本身是没错的,只是二者侧重点不一样。幻读侧重于在本事务执行期间,其他事务插入(insert)了新的记录,造成本事务之后读取到了前期不曾发现的事务,好似发生幻觉一样,是谓幻读。
需要指出:MySQL依靠MVCC的快照机制,某种程度上RR隔离级别已经避免了幻读,但仍可触发,官方文档也给予相应的说明。具体请阅读后面的实战案例。
09. 快照读和当前读
快照读,snapshot read,也叫一致读或非加锁读,consistent nonlocking read,指不依靠加锁来保证查询数据一致性,是MySQL中RR和RC级别下的默认查询语句执行方式,通过MVCC机制实现按"快照"版本号执行读操作。RR级别和RC级别采集"快照"原则是不同的,这也是导致两种隔离级别存在不同"读象"(不可重读或幻读)的原因,其中:
RR级别以进入事务后第一次读操作的时间作为快照版本(注意是第一次读操作的时间,而与开启事务时间无关),一旦确定快照版本,则在本事务后续读操作中就都应用此快照结果
RC级别是每次读操作时均采集快照,所以当其他事务提交后它能及时采集到新的快照
普通查询语句中,RC级别因为存在脏读,所以不属于一致读
SE级别因为是靠加锁(默认对普通select语句加S锁)来实现数据一致,能够确保读取到一致的结果,但已不是原原本本的一致读
当前读,current read,也叫加锁读,即locking read,特指在普通查询语句后增加"for share"或"for update"来指定共享读或排他读的读操作,其中:
for share,即加S锁,允许多个事务同时获取该S锁,是谓共享
for update,即加X锁,仅供获取到该X锁的事务操作,是谓排他
由于加锁读是建立在事务的基础上,所以必须显式开启事务后,加锁读才有意义,否则因为事务的
实战案例篇
以下所有案例均依托Navicat Primium12工具。初始建表语句:
1create table test(id int, name varchar(20), primary key(id)); 2insert into test values(1, 'A'); 3insert into test values(3, 'C');10. 3种"读象"
脏读、不可重复读和幻读应该是困扰很多人的一个常见概念问题,尤其是后两者的区别,这里通过几个案例进行阐释说明。
脏读,dirty read
首先来看官方文档给出的定义:
An operation that retrieves unreliable data, data that was updated by another transaction but not yet committed. It is only possible with the isolation level known as read uncommitted.
大意:某个操作中处理了由其他事务更新但尚未提交的数据,这个数据是不可靠的数据,仅发生于RU隔离级别。
案例:
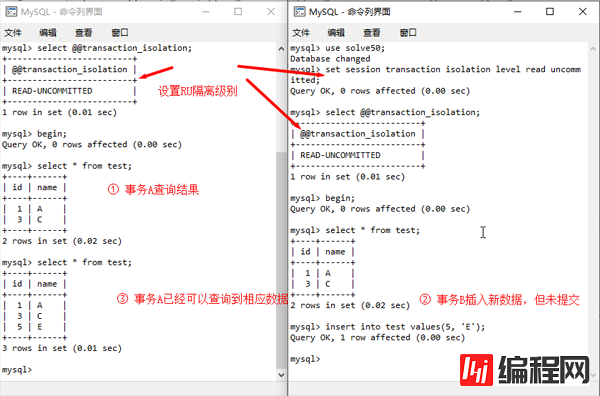
RU存在脏读:事务A读到了事务B更改但未提交的数据
不可重复读,non-repeatable read
官方文档给出的定义:
The situation when a query retrieves data, and a later query within the same transaction retrieves what should be the same data, but the queries return different results (changed by another transaction committing in the meantime).
大意:在一项事务查询数据期间,由于其他事务同时进行了提交,造成其前后两次查询到的数据结果不一致。
案例:
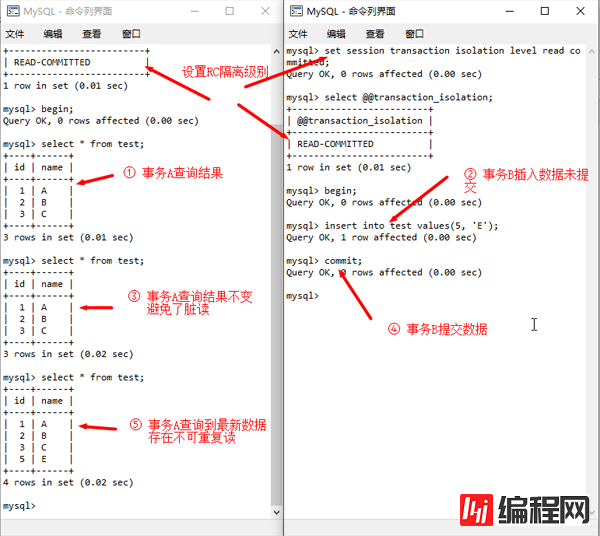
RC避免了脏读,但存在不可重复读
幻读,phantom read
A row that appears in the result set of a query, but not in the result set of an earlier query. For example, if a query is run twice within a transaction, and in the meantime, another transaction commits after inserting a new row or updating a row so that it matches the WHERE clause of the query.
大意:之前查询的结果中不存在、但之后查询得到的记录称作是幻读。例如,一个查询执行两次,期间另一个事务进行了插入或更新记录并提交,导致前一个事务两次查询结果不一致。
个人观点,幻读本身当然属于不可重复读的一种,毕竟两次读取结果"不一致"。但幻读侧重的是之前没有、之后虚幻出来了新行这种特定操作。
案例:
①,RR级别可避免RC级别中的不可重复读问题:
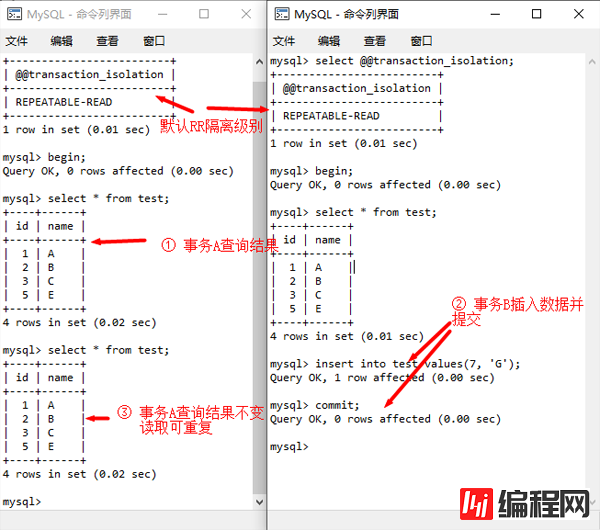
RR不存在不可重复读数据
②,特殊情况下仍可触发幻读
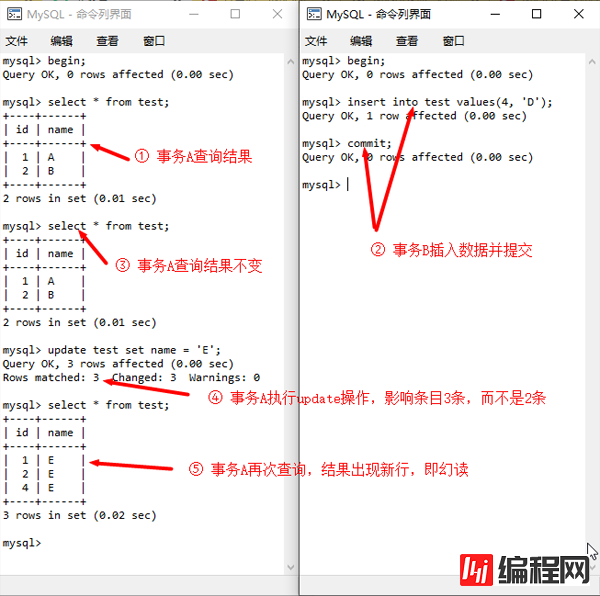
RR级别下,特殊操作仍可触发幻读(更新快照)
实际上,MVCC机制只是为保证读取结果采取快照的方式,所以能保证可重复读,但对于执行insert、update和delete操作时,仍然会实际检测当前数据库中最新的记录状态:当其他事务提交的最新数据与本事务中的增删改操作符合条件时,仍然会有影响。
这点不难理解,毕竟要保证数据库的状态一致性,但值得诧异的是经过update之后,居然会更新事务中的快照版本。例如图中所示案例,初次查询有2条记录,update时实际更新的是3条,但再次查询时结果也更新成了3条。而且,更重要的是,这种现象并不具有普遍性:仅当事务执行update操作时才会更新快照版本,而对于delete和insert操作则是只检测状态不更新快照版本。
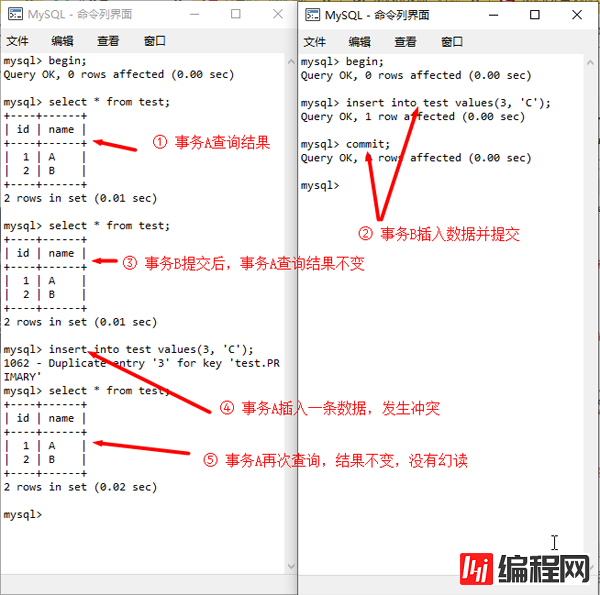
事务的insert操作不会更新快照版本
更一般的,进一步测试了事务B执行的其他增删改操作对事务A是否更新快照版本的影响,两两组合,得到如下试验结论:

如上幻读仅发生在其他事务插入新记录且提交后,本事务更新数据后的再次查询中
当然,官方文档对此给出了注解:

大意是说:快照读(snapshot)仅适用于查询语句,对DML(数据操纵语言,即增删改操作)不适用。其他事务执行删除或更新操作并提交,当前事务虽然"看不到"这些更改,但在执行自己执行更新或删除操作后对其可见。虽然此注解足以解释上述案例结论,但笔者实际上仍然存在前述表中的疑问。
最后需要指出的是,MVCC机制是基于快照版本的并发控制,与之对应的是LBCC,当采用LBCC读取数据时,则总能读到最新的数据。当然,这与RR隔离级别和MVCC机制并不矛盾。
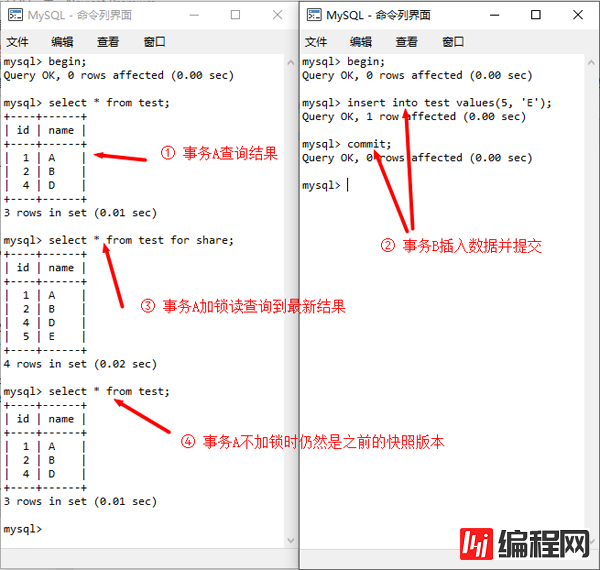
加锁读总是读取最新结果,但不影响快照版本
11. 快照版本
MVCC是基于多版本的并发控制,查询结果以快照版本为准。但不同隔离级别的快照版本采集原则不一致。在RR隔离级别中,通过MVCC机制实现了在同一事务中的可重复读取问题,而且该快照是在首次查询时采集的版本号信息,而与开启事务时机无关。
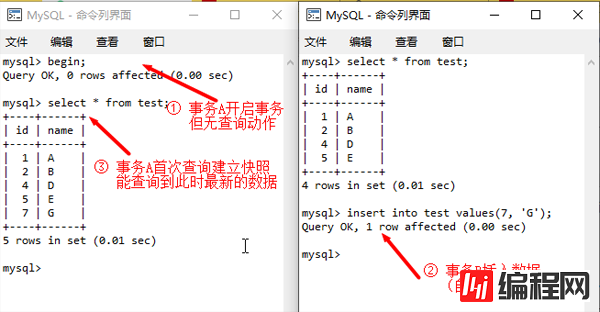
RR级别中首次查询建立快照版本
而且,RR级别中一旦建立了快照版本,则在该事务的后续查询中均采用该快照版本作为结果(当然,通过前面的案例发现也有例外);与之对应的是,RC级别中,每次查询都采集最新的快照版本作为结果,所以自然也就存在不可重复读的问题。
12. 加锁类型
首先简单介绍记录锁、间隙锁和临键锁:
记录锁
记录锁根据索引锁定相应记录,即使相应的表中不建立任何索引时。实际上所有InnoDB表都存在索引,当用户建表时未显式设置索引时,引擎会自动建立隐藏索引,这也是InnoDB底层基于聚簇索引存取整条记录的特性使然。

记录锁仅对索引满足查询条件的记录加锁
间隙锁
如果说记录锁是对命中的记录进行加锁,那么间隙锁是则是对查询区间范围内但是不存在的记录进行预订加锁,例如下图中假设表中不存在id=2、3的记录,但因为满足查询范围,所以会对其加间隙锁。

间隙锁对满足查询条件的记录间隙加锁
显然,间隙锁是以牺牲一定并发性能为代价换取高一致性。实际上,这也是所有锁在做的一件事,即在一致性和并发能力之间获得某种均衡。
需要指出的是:
鸿蒙官方战略合作共建——HarmonyOS技术社区
间隙锁仅在范围查询时存在,对于等值查询则不适用,例如上例中查询条件改为where id=1 or id=4则不会对潜在的id=2和3加间隙锁
当查询条件是等值查询,但查询条件是联合索引(在多列创建的索引)时,也会对满足要求的潜在记录加间隙锁
间隙锁仅在特定隔离级别存在,RR级别中默认有间隙锁,而RC级别则不存在
临键锁
在记录锁和间隙锁的基础上,临键锁=记录锁+间隙锁。

临键锁=记录锁+间隙锁
RC隔离级别中只有记录锁,而没有间隙锁和临键锁;RR级别中如果是等值查询则是记录锁,范围查询则是临键锁(即记录锁+间隙锁),在5.6以前版本中可以通过全局参数设置是否开启,但在8.0版本已移除该变量。
RC隔离级别默认设置记录锁
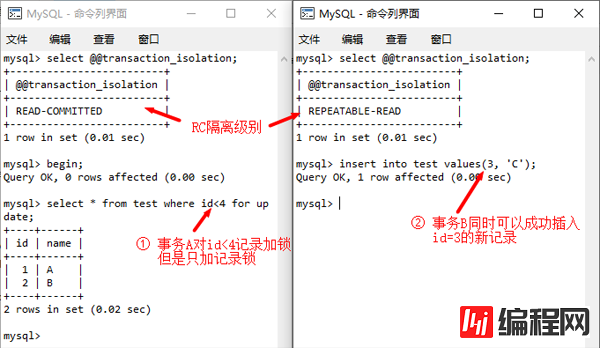
RR隔离级别默认加临键锁
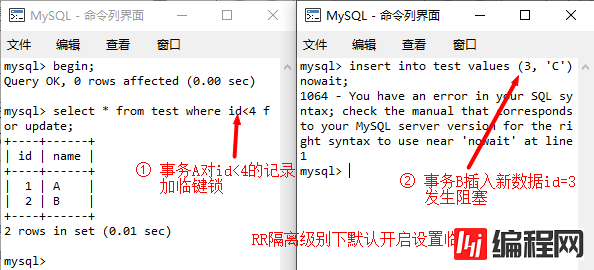
13. 索引类型对加锁影响
在明确加锁类型后,还需考虑不同索引对加锁的影响。首先指出,在InnoDB引擎下即使创建表时不显式指定索引,引擎也会自动生成隐藏索引用于聚簇存储记录数据。基于此,索引对加锁的影响有如下几种情况(引自官方文档):
一致读(即快照读,非加锁读,基于MVCC),除SE隔离级别外,其他隔离级别均不加任何锁
当前读(加锁读,for share或for update),对所有满足条件的记录加锁,同时释放不满足条件的索。对于某些复杂语句,例如含有UNIOn语句时,由于在汇总结果时涉及到临时表,所以对于不满足查询条件的记录不会立即释放锁。同时,加记录锁还是临键锁要取决于索引类型和查询条件,只有当对应唯一索引下的等值查询时,才只加记录锁,否则会升级为临键锁
update语句会对每条满足记录的语句加临键锁(X锁),但满足唯一索引和等值查询时,只加记录锁
delete语句加锁原则与update语句一致
insert语句只对插入行加记录锁(X锁),而没有任何间隙锁。实际上,insert语句是先加意向锁,请求成功才去插入,否则也不会阻塞其他事务。特殊情况下,当多个事务同时insert相同索引记录时,会发生索引重复冲突,进而可能造成死锁。详见下一节。
不同类型下的加锁分析详见文末参考资料2中文档,讲解充分,受到广泛转发引用,这里个人就不班门弄斧了。
14. 锁竞争和死锁
一般来说,锁具有排他性。如果是共享锁(S锁),可以和另一个共享锁(S锁)同时拥有,但无法和一个排他锁(X锁)同时拥有;而对于一个X锁,则无法跟任何其他锁并发。当多个事务企图同时占用某一资源需要加锁时,就有可能发生锁竞争甚至死锁。
锁竞争,当多个事务同时企图占有同一资源、但只是时间上冲突而资源占用上并不冲突时,会发生锁竞争:
多个事务竞争同一资源
在上述案例中,三个事务依次请求对数据表加X锁,其中事务A成功请求,事务B和事务C会处于等待。当事务A提交事务后,虽然事务B和事务C处于同时竞争加锁状态,但由于MySQL对事务调度的FIFO(First In First Out,先入先出)特性,二者不会发生死锁,而是优先满足事务B加锁请求,待事务B提交事务后再满足事务C的加锁请求。
死锁,与锁竞争相似而又不同的是,死锁也是发生在多个事务同时竞争同一资源,但是这些资源不能简单通过时间先后得以解决,而是存在逻辑上的冲突:
①,锁竞争+索引重复冲突造成死锁:
三个事务竞争资源存在索引重复
这个案例与锁竞争中的例子类似但又不同:假设事务A、事务B和事务C同时请求插入一条数据(插入语句都是加X锁),此时不仅仅是因为加锁冲突,还存在索引重复的问题,此时一旦事务A回滚释放锁后,事务B和事务C则会陷入死锁。这是一种特殊的死锁触发原因。
②,竞争同一资源出现死循环:
两个事务先竞争,后死锁
在这个案例中,先是事务A和事务B分别对id=1和id=2的记录加X锁,然后事务A继续对id=2的记录请求加锁时,因为该记录已被事务B占有,所以事务A只能等待;但此时事务B又企图对事务A已经占有的id=1记录加X锁,造成事务A和事务B在各自占有一定资源的基础上分别企图占用对方已加锁的资源,逻辑上冲突,骑虎难下,引擎不可能通过时间调度得以解决,故而发生死锁。
发生死锁后,引擎会根据相关的事务间的重要程度(包括占用资源多少、时间先后等)来选择一个进行回滚:例如上例中,事务A先于事务B请求加X锁,可将事务B看成是直接造成死锁的原因,所以选择对B进行回滚,而允许A加锁成功。
到此,相信大家对“MySQL中的锁怎么理解”有了更深的了解,不妨来实际操作一番吧!这里是编程网网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
--结束END--
本文标题: MySQL中的锁怎么理解
本文链接: https://lsjlt.com/news/69355.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0