本篇文章给大家分享的是有关怎么进行oracle数据块格式的分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。 &n
本篇文章给大家分享的是有关怎么进行oracle数据块格式的分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Oracle数据块可分为三层 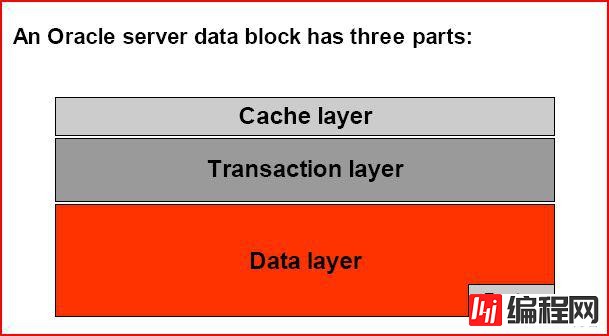
更细化
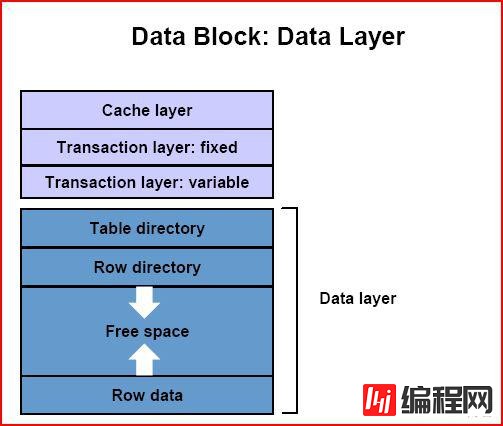
Cache layer--20字节,包含DBA、块类型、块格式、SCN;数据块被读取时进行完整性检查,确保没有损坏或fracture,即块更新信息只有部分被写入磁盘;
Transaction layer
固定事务layer--块类型,最后一次块清除时间csc,ITL数量itc;
可变事务layer--包含ITL,每个24字节;
Data layer
Data header(KDBH):14字节,表目录项个数,行目录项个数,指向free space的开始和结束位置的偏移量,当前块剩余空间
表目录--cluster表记录多于1,记录行目录中与此表相关的个数,以及起始位置
行目录--记录每行的起始位置,即指向行头的偏移量,每个2字节;innodb采用的是entry?
以10205为例
create table t(id number(2));
insert into t values(1);
insert into t values(2);
commit;
sql> select FILE_ID,BLOCK_ID,EXTENT_ID,BLOCKS from dba_extents where owner='SYS' and SEGMENT_NAME='T';
FILE_ID BLOCK_ID EXTENT_ID BLOCKS
---------- ---------- ---------- ----------
68 2260129 0 8
SQL> select dbms_rowid.rowid_block_number(rowid),id from t;
DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID) ID
------------------------------------ ----------
2260132 1
2260132 2
2260132 1
alter system dump datafile 68 block 2260132;
select spid from v$process where addr=(select paddr from v$session where sid=(select sid from v$mystat where rownum=1));
Dump block的输出格式与实际顺序可能不一致
****************cache layer******************************
buffer tsn: 115 rdba: 0x11227ca4 (68/2260132)
scn: 0x0860.07f11dad seq: 0x01 flg: 0x02 tail: 0x1dad0601
frmt: 0x02 chkval: 0x0000 type: 0x06=trans data
SCN=2字节base + 4字节wrap
Seq:sequence number
Flag:0x01—new block;0x02—delayed logging change advance SCN/seq;0x04—check value saved-block xor’s to zero;0x08—temporary block;
Frmt:数据块格式,从8i到10205一直为0x02
Chkval:可选项,db_block_checksum=true时启用
Tail:存于块尾footer,SCN base低位2字节 + 块类型 + SCN seq = 12ca + 06 + 01
Kcbh数据结构
typedef struct kcbh_ {
ub1 type_kcbh;
ub1 frmt_kcbh;
ub1 spare1_kcbh;
ub1 spare2_kcbh;
krdba rdba_kcbh;
ub4 bas_kcbh;
ub2 wrp_kcbh;
ub1 seq_kcbh;
ub1 flg_kcbh;
ub2 chkval_kcbh;
ub2 spare3_kcbh;
} kcbh;
****************transaction layer************************
--固定部分
Block header dump: 0x11227ca4
Object id on Block? Y
seg/obj: 0x5454c csc: 0x860.7f11dac itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x11227ca1 ver: 0x01 opc: 0
inc: 0 exflg: 0
Csc:最后一次块清除SCN
Typ:1=DATA; 2=INDEX
typedef struct ktbbh_ {
ub1 ktbbhtyp;
ub4 ktbbhsid;
kscn ktbbhcsc;
b2 ktbbhict;
ub1 ktbbhflg;
ub1 ktbbhfsl;
krdba ktbbhfnx;
}
--变长部分,每个ITL槽24个字节
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x000a.01d.00017bc3 0x00800330.7d5f.1e --U- 3 fsc 0x0000.07f11dad
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
Xid:事务ID undoseg + slot + wrap
Uba:undodba + seqno + recordNo
Flags:C=Commited; U=Commited Upper Bound; T=Active at CSC
Lck: 此事务涉及的行数目
Scn:提交TX时的SCN
struct ktbit {
kxid ktbitxid;
kuba ktbituba;
b2 ktbitflg;
ktbitun_t _ktbitun;
ub4 ktbitbas;
}
****************data layer******************************
tsiz: 0x1f98
hsiz: 0x18
pbl: 0x0d0e8664
bdba: 0x11227ca4
76543210
flag=--------
ntab=1
nrow=3
frre=-1
fsbo=0x18 --空闲空间的起始偏移量
fseo=0x1f86 –空闲空间的结束偏移量
avsp=0x1f65 –空闲空间总量
tosp=0x1f65
数据块头结构
struct kdbh {
ub1 kdbhflag;
ktno kdbhntab;
ub2 kdbhnrow;
sb2 kdbhfrre;
sb2 kdbhfsbo;
sb2 kdbhfseo;
b2 kdbhavsp;
b2 kdbhtosp;
}
0xe:pti[0] nrow=3 offs=0
表目录:
struct kdbt {
b2 kdbtoffs;
b2 kdbtnrow;
}
0x12:pri[0] offs=0x1f92
0x14:pri[1] offs=0x1f8c
0x16:pri[2] offs=0x1f86
行目录:sb2 kdbr[3]
每行对应一条记录,每个2字节,kdbr为sb2类型数组,指向每一行的头;
block_row_dump:
tab 0, row 0, @0x1f92
tl: 6 fb: --H-FL-- lb: 0x1 cc: 1
col 0: [ 2] c1 02
tab 0, row 1, @0x1f8c
tl: 6 fb: --H-FL-- lb: 0x1 cc: 1
col 0: [ 2] c1 03
tab 0, row 2, @0x1f86
tl: 6 fb: --H-FL-- lb: 0x1 cc: 1
col 0: [ 2] c1 02
行由行头和数据两部分,
行头--行标志 + 锁标志 + 列数,一般占3字节;T1-行大小; cc-本行的列数; lb-锁标志位,指向ITL; fb-标志位;
数据—列长度 + 列数据
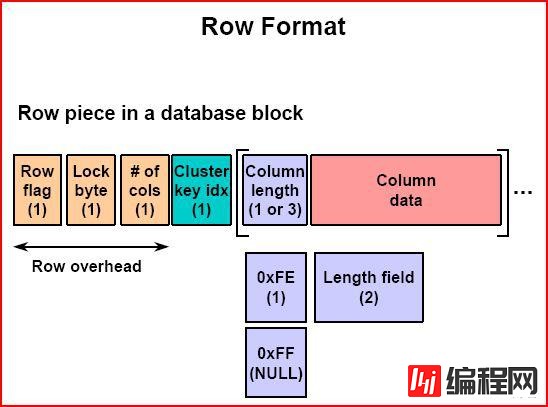
1 如何定位每1行?
由行目录kdbr存储每行的偏移量,每项2字节;
BBED> p kdbr
sb2 kdbr[0] @118 8078
sb2 kdbr[1] @120 8068
BBED> p *kdbr[0]
rowdata[10] ----------- ub1 rowdata[10]
@8178 0x2c
由于块头包含可变长的ITL和行目录,故空闲空间从块尾开始分配;
2 row flag的取值范围
删除数据时仅将行标记为deleted,行头row flag的位掩码如下

对于普通行(没有行链接/行迁移/被删除/簇表),其基本标志位为HFL,即32+8+4=44=0x2c;
若行被删除,则row flag=44+16=60=0x3c;
恢复尚未被覆盖的删除行,只需将其row flag从3c改为2c,row flag位于行头首字节;
详细可参照Http://orafaq.com/papers/dissassembling_the_data_block.pdf
3 行锁原理?
Oracle没有为行锁提供数据结构,而是通过 事务表 + ITL + lb(row header)实现;
一个事务分配一个TX lock和若干TM lock,涉及的数据块各需1个ITL,通过其XID关联事务表slot,而数据行则通过lb指向本块的ITL;
4 数据块验证?
数据块读入内存或写入磁盘时,会做一致性检查:
1 块版本,块头的SCNBase/块类型/seq同footer比较;
2 cache层的DBA同block buffer的DBA比较;
3 block-checksum, 如果开启checksum则做验证;
Dbv只检查数据块的header/footer,做逻辑验证;
Db_block_checking:替代10210/10211/10212事件,进行块完整性检查,如free slot list/行位置/锁数量;检查时会复制块,如有错误将块标志为soft corruption;
Db_block_checksum:dbwr和direct loader写数据块时计算checksum并存于cache层chkval,再次读取时重新计算并与已有checksum比较;
Dbms_repair修复cache/transaction层的错误,将块标示为soft corruption;
event
10231全表扫描时跳过坏块
10233跳过索引坏块
以上就是怎么进行oracle数据块格式的分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注编程网数据库频道。
--结束END--
本文标题: 怎么进行oracle数据块格式的分析
本文链接: https://lsjlt.com/news/68687.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0