今天就跟大家聊聊有关Mysql到HBase的迁移策略的研究与实现是怎样的,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。随着WEB2.0的到来,互联网
今天就跟大家聊聊有关Mysql到HBase的迁移策略的研究与实现是怎样的,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
随着WEB2.0的到来,互联网数据快速增长。大规模数据的采集和处理及应用直接影响着用户体验,决定着企业的发展。比较传统关系型数据库和分布式非关系型数据库两者处理大数据的性能,将本地数据迁移到分布式数据库势在必行。文章分析了现有迁移工具的利弊,基于HBase数据库提出了一种有效的数据迁移策略,并依据提出的策略实现了一种半自动化移工具。以美国城市和方言系统CityDetail数据库数据为例,阐述了该迁移工具的工作原理并对迁移后的数据进行多次查询比较,证明了使用该工具进行数据迁移的高效性。
关系型数据库;HBase;迁移工具
Web2.0时代,网络技术飞速发展,个人与企业都在不断地创造海量数据,在新的掘金大潮中,如何利用数据以及将数据转化为有价值信息的速度,越来越成为企业成功与否的决定性因素。实现数据的快速分析,并做出指导,对数据存储提出了更大的挑战。虽然传统数据库已经发展了很多年,在企业应用方面也形成了很大的使用规模,但是其在处理大数据应用方面仍然存在不足[1]。首先,传统关系型数据库无法完成大规模水平拓展,尽管网络解决方案在一定程度上解决了这个问题,但网络中仍无法动态地创建集群;其次,关系型数据库无法有效存储Web2.0时代的半结构及非结构化数据;此外传统的关系型数据库也无法满足大数据时代对海量数据高效查询的需求。
非关系型数据库的出现弥补了传统关系型数据库在处理大规模数据中的不足。非关系型数据库是对Cassandra、mongoDB和HBase等众多支持非关系化以及弱关系化数据存储的数据库的统称。非关系型数据库中的表主要采用聚合的存储结构,这就使得数据管理更为方便[2];通过预分配空间机制轻松实现了海量数据存储;可通过连续添加服务节点来实现扩展,不需要停机维护和数据迁移。此外,众多的非关系型数据库有着强大的业务针对性,在应用性能上较传统关系型数据库有着颠覆性的提升。其中HBase凭借着与hadoop的无缝集成和强大的高扩展性以及拥有巨大的多元化社区的优势[3],被各大互联网企业争相应用。
HBase的广泛应用,使得存储在传统关系型数据库中的历史数据向HBase的迁移成为当下研究热点。
1、国内外研究现状
针对传统关系型数据向HBase迁移的研究,目前,业界只提出了一些数据迁移的方法,却很少有比较权威的数据迁移工具,更没有可以迁移原有表模式或者自动化的迁移工具。
现有的迁移工具如Hadoop的官方工具Sqoop只支持单表的增量加载,无法完成数据库系统中众多表模式的迁移;HBase的Importtsv 工具只支持TSV等指定文件的迁移;Put方法虽然简单直接但也只是完成数据的迁移且迁移效率不佳。此外国内外的大型互联网公司如微软、华为等也都争相开发自己的迁移工具,但多是基于自身的商业应用[4]。
综上所述,实现一个自动化或半自动化的数据迁移工具很有必要。这样可以更大限度地利用业务存储在原有关系型数据库中的历史数据,减少数据之间关系等珍贵资源的浪费,此外,也将避免人工再次录入。本文针对关系型数据库mysql和非关系型数据库HBase的存储原理和表结构进行了深入研究,并以 CityDetail系统为例阐述了传统关系型数据库向HBase迁移的思想,并设计实现了迁移工具。最终,验证了通过此方法进行数据迁移后,对数据库查询的高效性。
2、数据库的存储原理分析
2.1、关系型数据库存储原理
关系型数据库[5]是一种建立在关系模型基础上的数据库。关系型数据库中用一张二维表代表现实世界中的实体,用表中的字段代表实体的属性,用外键等联合操作代表实体之间的关系。表中的一行即一个记录代表了一个实体,一个或多个这样的表以及表之间的关系组成了一个关系型数据库。
关系型数据库Mysql中默认安装INFORMATioN_SCHEMA数据库。INFORMATION_SCHEMA数据库中存储着MySQL中所有数据库的表名、列名、记录条数、主键、外键以及过程和方法等信息。这些存储在INFORMATION_SCHEMA中的数据就叫做数据库系统的元数据。如图1所示。
元数据是用来描述数据的数据[6],用来支持如数据的存储位置、历史数据、资源查找等功能。元数据可以视为一种电子目录,用来协助数据检索。在关系型数据库中利用DESCRIB等SQL语句进行检索时就是查询的数据库中的这些元数据。因此,在数据迁移的过程中,可以利用对关系型数据库中元数据表的查询快速获取关系型数据库中各个表的模式和各表之间的关系,然后进行迁移。
2.2、HBase的存储原理
非关系型数据库HBase是对Google的BigTable数据库的开源实现。它经常被描述为是一种稀疏的、分布式的、持久化的多为映射[7]。HBase中的逻辑视图如图2所示。
由图2可以看出HBase的表是一个稀疏矩阵。HBase与传统关系型数据库表所不同的是:它可以存储半结构化数据,即HBase中的表在设计上没有严格的限制[8],数据记录可能包含不一致的列、不确定大小等。此外,与关系型数据库不同,HBase在存储上基于列而非行,因此对同列中的数据具有较好的查询性能。HBase表可以有数百万列和数十亿行,因此可以用来存储大规模数据。HBase中实际上定义了如下的思维数据模型[7],分别为:
(1)表。HBase用表来组织数据,表名为字符串。
(2)行键。HBase表中,数据按行存储。行由行键***标志,行键没有数据类型,总是被视为字节数组。
(3)列族。表中的数据在行中被组织成列族,列族也影响到HBase数据的物理存放。系统会把列族存储在HBase自己的数据库中,所以列族要在建表时定义好并且不能轻易修改。此外,HBase中每行有相同的列族,相同列族下可以拥有不同的列限定符。
(4)列限定符。列族里的数据通过列限定符或列来定位。与列族不同,列限定符可以不必事前定义。列限定符也不必在不同行之间保持一致。列限定符没有数据类型,总是视为字节数组。
(5)单元。行键、列族和列限定符一起确定了一个单元。存储在单元里的数据称为单元值。值没有数据类型,视为字节数组byte[]。
(6)时间版本。HBase中用版本来存储单元值在不同时间的值,默认存储3个版本。时间版本用时间戳来标识。
在物理上,HBase的数据存储在hdfs中,能够很好地利用HDFS的分布式处理模式,并从Hadoop的mapReduce程序模型中获益。 HBase逻辑上的表在行的方向上分割成多个HRegion,HRegion按大小分割,每张表开始只有一个Region,随着记录数的不断增加,Region不断增大,当增大到一定程度时,HRegion会被等分成两个新的HRegion。HRegion是HBase中分布式存储和负载均衡的最小单元,但却不是存储的最小单元。HRegion由一个或者多个Store组成,每个Store保存了表中的一个列族。每个Store又由一个 Memstore和0至多个StoreFile(HFile)组成,StoreFile用来存储数据并以HFile的形式保存在HDFS上[9]。
3、迁移工具的主要模块
本迁移系统的主要组成模块为如下几个部分。
3.1、提取源数据库中的表模式
通过对传统关系型数据库中存储结构的分析可知,INFORMATION_SCHEMA数据库存储了MySQL中所有数据表的元数据,因此可以通过对这些元数据的访问,快速提取到要迁移的MySQL数据库中所有源数据的表模式。
INFORMATION_SCHEMA数据库中的SCHEMATA表提供了当前MySQL实例中所有数据库的信息,SQL查询语言show datatables的结果就是出自此表。TABLES表提供了关于数据库中的表信息,详细描述了某个表属于哪个SCHEMA以及表类型、表名称、每个表的记录数以及创建时间等信息。COLUMNS表提供了表中的列信息,详细表述了某张表的所有列以及每个列的信息。STATISTICS表提供了表中所有的索引信息,此外还有描述表的用户权限等的元数据。通过对这些表的联合访问,可以快速提取源数据库模式,避免因对数据库中的数据表的访问而延长响应时间。
3.2、表模式的转换
通过对HBase数据库存储结构的研究可知,HBase数据库中表的结构与传统关系型数据库有所不同。HBase中的各表之间不存在关联关系,也不存在关系型数据库中的Join连接查询等操作。要进行表模式的迁移就必须将传统关系型数据库中存在相互联系的数据迁移到HBase中的同一行中。考虑到 HBase数据库的特殊表结构和存储结构,为了使迁移后的数据尽量不影响业务功能,对数据的表模式做以下转换[10]:
(1)基本表的转换
对CityDetail系统中的所有表进行基本转换就是直接将源数据表迁移到HBase端。把源数据表的表名作为HBase表的表名,主键作为行键,表名和列名的组合作为HBase端表中的列限定符,版本设置为1。
(2)内嵌转换
在CityDetail系统中存在Country表与City表之间的关联关系,同时存在Country表与CountryLanguage表之间的关联关系。HBase中的物理存储结构决定了HBase表的不同列族存储在不同的Store文件中,又因为源数据中对不同表的连接查询操作要远远少于单表的操作,因此将City表和CountryLanguage表分别作为Country表的一个列族进行存储即可。所以,要实现这类表的迁移就要保留 Country的表模式,然后对City表和CountryLanguage表进行分割,作为Country表的一个列族添加在Country表中。
(3)递归转换
在CityDetail系统中除存在Country表与City表之间的关联关系外,还存在着下一级如Detail表和City表之间的关联关系。要完成这一类型表的迁移,就要在Country表和City表进行内嵌转换的基础上,对City表和Detail表也进行深一级的内嵌变换。根据递归原理,先将Detail表进行分割,作为City表相应行中的一个列族,然后再对City表进行分割,作为Country表的一个列族进行迁移。
(4)分割转换
根据关系型数据库的关系范式[11]可知,表之间还可能存在同一个表Describe是 外三个表Country、City和CountryLanguage的子表的情况,针对这类关系的转换可以通过对Describe表进行分割,并分别添加到三个表对应的列族下的方法来完成。
通过以上四种转换方式的整合应用,最终完成CityDetail系统的所有表模式的迁移。
4、设计实现
本文设计的迁移系统流程图如图3所示。

(1)连接关系型数据库MySQL
首先在Java程序中使用Class.forName语句加载MySQL的JDBC驱动程序,然后用语句“Connection conn = DriverManager.getConnection(url, user, passWord)”创建一个新的连接,进而访问数据库的元数据,获取表模式。
(2)模式转换
遍历(1)中获取的所有表模式,利用前文提到的四种转换方式转换得到迁移后的HBase中的表模式。
(3)连接HBase数据库
通过语句“Configuration conf=HBaseConfigurAtion.create”获取HBase数据库中的配置信息,然后用语句“table=new HTable(conf,tablename)”在HBase中创建新表,根据(2)中转换得到的表模式,用语句“byte[] family=Bytes.toBytes(“n”)”指定各列族的名称。至此,迁移系统的表模式迁移完毕。
(4)数据迁移
在数据迁移模块中要分别连接两个数据库。首先,连接MySQL数据库,创建一个MySQL Object用于访问MySQL中指定的数据库,用SQL查询语句循环遍历数据,获取数据库中的记录,然后连接创建的HBase数据表,生成HBase Object,用Put方法依次将SELECT查询获取的数据记录插入到HBase的表中,最终关闭数据对象,完成数据迁移。
5、测试与结论
实验测试在Hadoop集群上进行,集群包括4台主机,每台主机都安装了Hadoop、HBase和ZooKeeper,集群信息如表1所示。
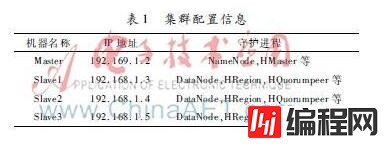
本试验分别用本文所提数据迁移工具与Apache为Hadoop配置的官方数据迁移工具Sqoop对CityDetail系统进行迁移,并使用不同大小的数据集对两种工具的迁移过程和结果进行了对比。
首先,在迁移过程的繁简方面,Sqoop工具是在终端上通过指定参数包括连接数据库的语句、迁移前后的数据表名、属性名等来完成数据的迁移。在参数指定上比较繁琐,不容易操作。而本文迁移工具从获取表模式到建立HBase数据表和迁移数据均由系统自动完成,比较而言,自动化程度较高。
其次,在查询性能上,由于本文迁移工具完成了表模型的转换和迁移,而Sqoop只是机械化地迁移了特定表中的数据,并没有进行表模式的迁移,两者比较,前者迁移结果存在很大的优势。以典型的SQL查询语句:“SELECT Name,Language where Country.CountryCode=Language.CountryCode” 为例,两者的查询结果如图4。
从图4可以看出,本文迁移工具较Sqoop在查询性能上有了很大的改善。因为本文迁移工具通过对表模式的转换,将属于同一条记录的信息存储在了一个HRegion中,同一表中的数据存储在了同一个Store文件中,查询时,减少了多次寻址的过程,从而降低了系统响应时间。
6、结论
本文通过对CityDetail系统从MySQL数据库到HBase数据库的迁移案例分析,研究了MySQL数据库和HBase数据库存储数据的原理,提出通过访问MySQL数据库元数据快速提取表模式并转换迁移的方法,解决了以往迁移工具不能迁移表模式的问题。在尽量保证数据完整性的前提下,提高了迁移速度、自动化程度和迁移后数据的查询性能。但是,由于HBase中存在***索引,在多条件查询上的查询性能肯定会较MySQL有较大的下降,因此关于索引的优化还有待学习和研究。
看完上述内容,你们对MySQL到HBase的迁移策略的研究与实现是怎样的有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注编程网数据库频道,感谢大家的支持。
--结束END--
本文标题: MySQL到HBase的迁移策略的研究与实现是怎样的
本文链接: https://lsjlt.com/news/67421.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0