Hive 提供了类似 oracle 的 rownum 机制,类似这样(效率比较差): select * from (select row_number() over (order by create_time d

Hive 提供了类似 oracle 的 rownum 机制,类似这样(效率比较差):
select * from (select row_number() over (order by create_time desc) as rownum,u.* from user u) mm where mm.rownum between 10 and 15;
还有一种办法,如果表里有唯一标识字段也可以借助这个字段和 limit 实现。比如:
获取第一页数据:
注:同时需要记录这 10 条中最大的 id 为 preId,作为下一页的条件。
select * from table order by id asc limit 10;
获取第二页数据:
注:同时保存数据中最大的 id 替换 preId。
select * from table where id >preId order by id asc limit 10;
对于数据库分页, 这里曾经分析过存在的问题 大清单报表应当怎么做? 也给出了改善的思路,可以参考:
把取数和呈现做现两个异步线程,取数线程发出 sql 后就不断取出数据后缓存到本地存储中,呈现线程根据页数计算出行数到本地缓存中去获取数据显示。这样,只要已经取过的数据就能快速呈现,不会有等待感,还没取到的数据需要等待一下也是正常可理解的;而取数线程只涉及一句 SQL,在数据库中是同一个事务,也不会有不一致的问题。这样,两个问题都能得到解决。不过这需要设计一种可以按行号随机访问记录的存储格式,不然要靠遍历把记录数出来,那反应仍然会很迟钝。
画个图感受感受:
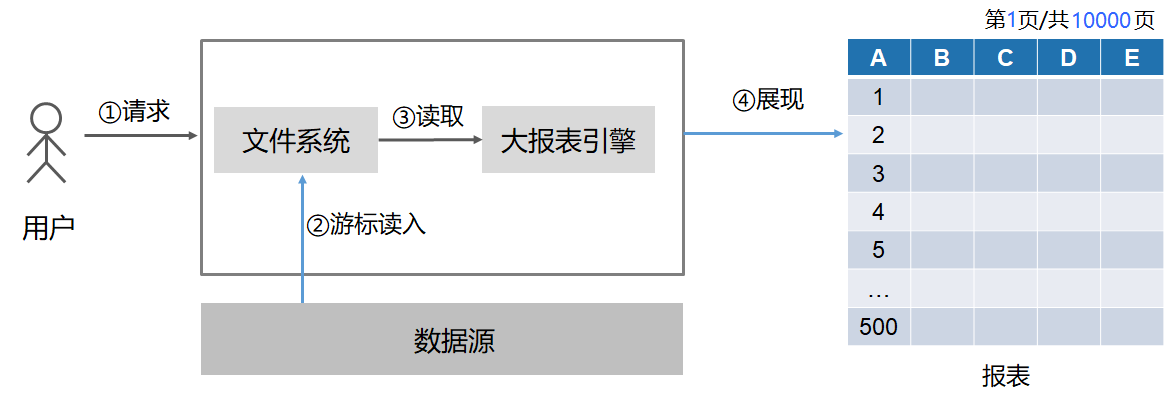
②和③分别是两个线程,一个负责取数缓存,一个负责读缓存做报表呈现
--结束END--
本文标题: 报表连 hive,数据量比较大,怎么分页查询?
本文链接: https://lsjlt.com/news/6715.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0