这篇文章主要介绍了oracle优化器RBO与CBO有什么用,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。RBO和CBO的基本概念Oracle
这篇文章主要介绍了oracle优化器RBO与CBO有什么用,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
RBO和CBO的基本概念
Oracle数据库中的优化器又叫查询优化器(Query Optimizer)。它是sql分析和执行的优化工具,它负责生成、制定SQL的执行计划。Oracle的优化器有两种,基于规则的优化器(RBO)与基于代价的优化器(CBO)
RBO: Rule-Based Optimization 基于规则的优化器
CBO: Cost-Based Optimization 基于代价的优化器
RBO自ORACLE 6以来被采用,一直沿用至ORACLE 9i. ORACLE 10g开始,ORACLE已经彻底丢弃了RBO,它有着一套严格的使用规则,只要你按照它去写SQL语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,也就是说RBO对数据不“敏感”;它根据ORACLE指定的优先顺序规则,对指定的表进行执行计划的选择。比如在规则中,索引的优先级大于全表扫描;RBO是根据可用的访问路径以及访问路径等级来选择执行计划,在RBO中,SQL的写法往往会影响执行计划,它要求开发人员非常了解RBO的各项细则,菜鸟写出来的SQL脚本性能可能非常差。随着RBO的被遗弃,渐渐不为人所知。也许只有老一辈的DBA对其了解得比较深入。关于RBO的访问路径,官方文档做了详细介绍:
RBO Path 1: Single Row by Rowid
RBO Path 2: Single Row by Cluster Join
RBO Path 3: Single Row by Hash Cluster Key with Unique or Primary Key
RBO Path 4: Single Row by Unique or Primary Key
RBO Path 5: Clustered Join
RBO Path 6: Hash Cluster Key
RBO Path 7: Indexed Cluster Key
RBO Path 8: Composite Index
RBO Path 9: Single-Column Indexes
RBO Path 10: Bounded Range Search on Indexed Columns
RBO Path 11: Unbounded Range Search on Indexed Columns
RBO Path 12: Sort Merge Join
RBO Path 13: MAX or MIN of Indexed Column
RBO Path 14: ORDER BY on Indexed Column
RBO Path 15: Full Table Scan
CBO是一种比RBO更加合理、可靠的优化器,它是从ORACLE 8中开始引入,但到ORACLE 9i 中才逐渐成熟,在ORACLE 10g中完全取代RBO, CBO是计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。如果对一次执行SQL时发现涉及对象(表、索引等)没有被分析、统计过,那么ORACLE会采用一种叫做动态采样的技术,动态的收集表和索引上的一些数据信息。
关于RBO与CBO,我有个形象的比喻:大数据时代到来以前,做生意或许凭借多年累计下来的经验(RBO)就能够很好的做出决策,跟随市场变化。但是大数据时代,如果做生意还是靠以前凭经验做决策,而不是靠大数据、数据分析、数据挖掘做决策,那么就有可能做出错误的决策。这也就是越来越多的公司对BI、数据挖掘越来越重视的缘故,像电商、游戏、电信等行业都已经大规模的应用,以前在一家游戏公司数据库部门做BI分析,挖掘潜在消费用户简直无所不及。至今映像颇深。
CBO与RBO的优劣
CBO优于RBO是因为RBO是一种呆板、过时的优化器,它只认规则,对数据不敏感。毕竟规则是死的,数据是变化的,这样生成的执行计划往往是不可靠的,不是最优的,CBO由于RBO可以从很多方面体现。下面请看一个例子,此案例来自于《让Oracle跑得更快》。
SQL> create table test as select 1 id ,object_name from dba_objects;
Table created.
SQL> create index idx_test on test(id);
Index created.
SQL> update test set id=100 where rownum =1;
1 row updated.
SQL> select id, count(1) from test group by id;
ID COUNT(1)
---------- ----------
100 1
1 50314
从上面可以看出,该测试表的数据分布极其不均衡,ID=100的记录只有一条,而ID=1的记录有50314条。我们先看看RBO下两条SQL的执行计划.
SQL> select * from test where id =100;
Execution Plan
----------------------------------------------------------
Plan hash value: 2473784974
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST |
|* 2 | INDEX RANGE SCAN | IDX_TEST |
------------------------------------------------
Predicate InfORMation (identified by operation id):
---------------------------------------------------
2 - access("ID"=100)
Note
-----
- rule based optimizer used (consider using cbo)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
588 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL> select * from test where id=1;
50314 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2473784974
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST |
|* 2 | INDEX RANGE SCAN | IDX_TEST |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=1)
Note
-----
- rule based optimizer used (consider using cbo)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
7012 consistent gets
97 physical reads
0 redo size
2243353 bytes sent via SQL*Net to client
37363 bytes received via SQL*Net from client
3356 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
50314 rows processed
从执行计划可以看出,RBO的执行计划让人有点失望,对于ID=1,几乎所有的数据全部符合谓词条件,走索引只能增加额外的开销(因为ORACLE首先要访问索引数据块,在索引上找到了对应的键值,然后按照键值上的ROWID再去访问表中相应数据),既然我们几乎要访问所有表中的数据,那么全表扫描自然是最优的选择。而RBO选择了错误的执行计划。可以对比一下CBO下SQL的执行计划,显然它对数据敏感,执行计划及时的根据数据量做了调整,当查询条件为1时,它走全表扫描;当查询条件为100时,它走区间索引扫描。如下所示:
SQL> select * from test where id=1;
50314 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1357081020
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 49075 | 3786K| 52 (2)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| TEST | 49075 | 3786K| 52 (2)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=1)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
32 recursive calls
0 db block gets
3644 consistent gets
0 physical reads
0 redo size
1689175 bytes sent via SQL*Net to client
37363 bytes received via SQL*Net from client
3356 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
50314 rows processed
SQL> select * from test where id =100;
Execution Plan
----------------------------------------------------------
Plan hash value: 2473784974
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 79 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 79 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST | 1 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=100)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
9 recursive calls
0 db block gets
73 consistent gets
0 physical reads
0 redo size
588 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
仅此一项就可以看出为什么ORACLE极力推荐使用CBO,从ORACLE 10g开始不支持RBO的缘故。所谓长江后浪推前浪,前浪死在沙滩上。
CBO知识点的总结
CBO优化器根据SQL语句生成一组可能被使用的执行计划,估算出每个执行计划的代价,并调用计划生成器(Plan Generator)生成执行计划,比较执行计划的代价,最终选择选择一个代价最小的执行计划。查询优化器由查询转换器(Query Transform)、代价估算器(Estimator)和计划生成器(Plan Generator)组成。
CBO优化器组件
CBO由以下组件构成:
· 查询转化器(Query Transformer)
查询转换器的作用就是等价改变查询语句的形式,以便产生更好的执行计划。它决定是否重写用户的查询(包括视图合并、谓词推进、非嵌套子查询/子查询反嵌套、物化视图重写),以生成更好的查询计划。
The input to the query transformer is a parsed query, which is represented by a set of
query blocks. The query blocks are nested or interrelated to each other. The form of the
query determines how the query blocks are interrelated to each other. The main
objective of the query transformer is to determine if it is advantageous to change the
form of the query so that it enables generation of a better query plan. Several different
query transformation techniques are employed by the query transformer, including:
■ View Merging
■ Predicate Pushing
■ Subquery Unnesting
■ Query Rewrite with Materialized Views
Any combination of these transformations can be applied to a given query.
· 代价评估器(Estimator)
评估器通过复杂的算法结合来统计信息的三个值来评估各个执行计划的总体成本:选择性(Selectivity)、基数(Cardinality)、成本(Cost)
计划生成器会考虑可能的访问路径(Access Path)、关联方法和关联顺序,生成不同的执行计划,让查询优化器从这些计划中选择出执行代价最小的一个计划。
· 计划生成器(Plan Generator)
计划生成器就是生成大量的执行计划,然后选择其总体代价或总体成本最低的一个执行计划。
由于不同的访问路径、连接方式和连接顺序可以组合,虽然以不同的方式访问和处理数据,但是可以产生同样的结果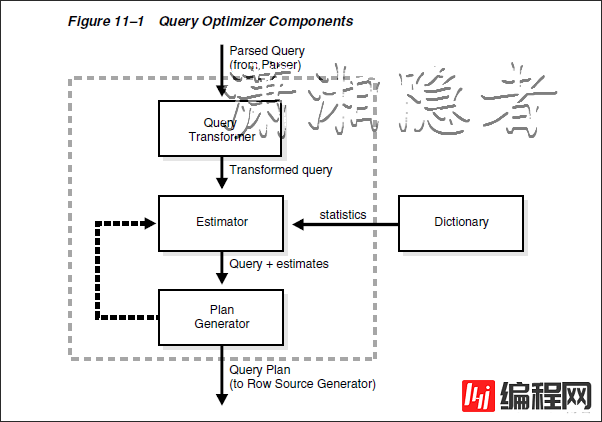
下图是我自己为了加深理解,用工具画的图
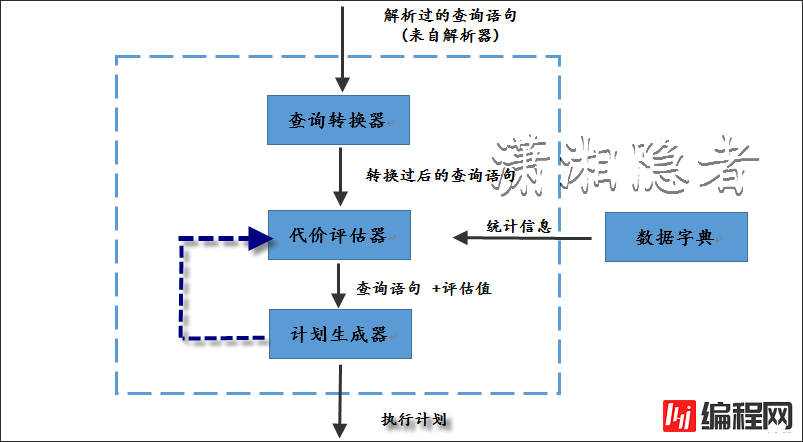
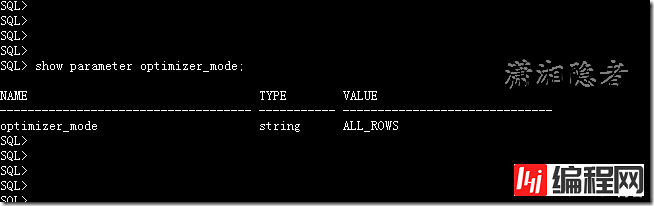
查看ORACLE优化器
SQL> show parameter optimizer_mode;
NAME TYPE VALUE
--------------------------- ----------- -----------------
optimizer_mode string ALL_ROWS
修改ORACLE优化器
ORACLE 10g 优化器可以从系统级别、会话级别、语句级别三种方式修改优化器模式,非常方便灵活。
其中optimizer_mode可以选择的值有: first_rows_n,all_rows. 其中first_rows_n又有first_rows_1000, first_rows_100, first_rows_10, first_rows_1
在Oracle 9i中,优化器模式可以选择first_rows_n,all_rows, choose, rule 等模式:
Rule: 基于规则的方式。
Choolse:指的是当一个表或或索引有统计信息,则走CBO的方式,如果表或索引没统计信息,表又不是特别的小,而且相应的列有索引时,那么就走索引,走RBO的方式。
If OPTIMIZER_MODE=CHOOSE, if statistics do not exist, and if you do not add hints to SQL statements, then SQL statements use the RBO. You can use the RBO to access both relational data and object types. If OPTIMIZER_MODE=FIRST_ROWS, FIRST_ROWS_n, or ALL_ROWS and no statistics exist, then the CBO uses default statistics. Migrate existing applications to use the cost-based approach.
First Rows:它与Choose方式是类似的,所不同的是当一个表有统计信息时,它将是以最快的方式返回查询的最先的几行,从总体上减少了响应时间。
All Rows: 10g中的默认值,也就是我们所说的Cost的方式,当一个表有统计信息时,它将以最快的方式返回表的所有的行,从总体上提高查询的吞吐
虽然Oracle 10g中不再支持RBO,Oracle 10g官方文档关于optimizer_mode参数的只有first_rows和all_rows.但是依然可以设置 optimizer_mode为rule或choose,估计是ORACLE为了过渡或向下兼容考虑。如下所示。
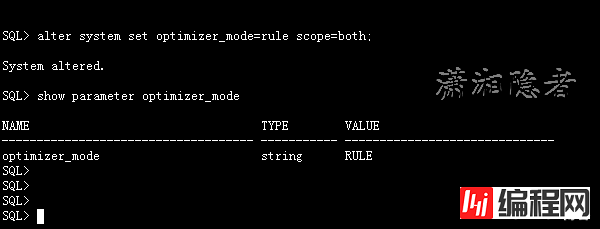
系统级别
SQL> alter system set optimizer_mode=rule scope=both;
System altered.
SQL> show parameter optimizer_mode
NAME TYPE VALUE
-------------------------------- ----------- -----------------------
optimizer_mode string RULE
会话级别
会话级别修改优化器模式,只对当前会话有效,其它会话依然使用系统优化器模式。
SQL> alter session set optimizer_mode=first_rows_100;
Session altered.
语句级别
语句级别通过使用提示hints来实现。
SQL> select * from dba_objects where rownum <= 10;
感谢你能够认真阅读完这篇文章,希望小编分享的“ORACLE优化器RBO与CBO有什么用”这篇文章对大家有帮助,同时也希望大家多多支持编程网,关注编程网数据库频道,更多相关知识等着你来学习!
--结束END--
本文标题: ORACLE优化器RBO与CBO有什么用
本文链接: https://lsjlt.com/news/65439.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0