这篇文章主要介绍“怎么理解oracle统计信息”,在日常操作中,相信很多人在怎么理解Oracle统计信息问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么理解Oracle统计
这篇文章主要介绍“怎么理解oracle统计信息”,在日常操作中,相信很多人在怎么理解Oracle统计信息问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么理解Oracle统计信息”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
dbms_stats.gather_table_stats( owner VARCHAR2, tablename VARCHAR2, partname VARCHAR2, estimate_percent NUMBER, block_sample BOOLEAN, method_opt VARCHAR2, degree NUMBER, granularity VARCHAR2, cascade BOOLEAN, stattab VARCHAR2, statid VARCHAR2, statown VARCHAR2, no_invalidate BOOLEAN, force BOOLEAN ) 参数说明 |
1.owner:要分析表的所有者 2.tablename:要分析的表的表名 3.partname:分区名 4.estimate_percent:采样行的百分比,从0.000001-100,null为全部分析,不采样。常量DBMS_STATS.AUTO_SAMPLE_SIZE是默认值,由Oracle决定最佳采样率。 5.block_sample:是否用块采样代替行采样。 6.method_opt:决定histograms信息是怎样被统计的,method_opt的取值如下:
7.degree:设置统计信息收集的并行度,默认值为null。 8.cascade:收集索引的统计信息,默认为false 9.stattab:指定存储统计信息的表。 10.statid:如果多个表的统计信息存储在一个stattab中时,statid用作分区条件。 11.statown:存储统计信息表的所有着。 如果不指定上述三个参数,则统计信息会被更新到数据字典。 12.force:即使表锁住了也收集统计信息。 |
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SCOTT', tabname => 'DEPT', estimate_percent => 30, method_opt => 'for all columns size repeat', no_invalidate => FALSE, degree => 8, cascade => TRUE); END; / |
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'ROBINSON', tabname => 'P_TEST', estimate_percent => 30, method_opt => 'for all columns size repeat', no_invalidate => FALSE, degree => 8, granularity => 'ALL', cascade => TRUE); END; / |
注意:分区的统计信息合并 到 DBA_TABLES
estimate_percent
表示采样率,采样率设置太大,也没必要,使用dbms_stats.auto_sample_size选项允许Oracle自动估算要采样的一个segment的最佳百分比。
如果表非常大,采样率过高会导致收集统计信息跑很长,增加了系统压力。
采样率设置过小,统计的信息就不能很完整的体现表中数据的分布,这样CBO在进行执行计划的选择上,很可能选择错误的执行计划。
根据工作经验:
表小于1GB 采样率可以设置50%-100%
表大于1GB小于5GB可以设置30%
表大于5GB 这类表都应该进行分区,采样率可以设置为30%
 method_opt 有两部分构成
method_opt 有两部分构成
表示收集的方法,参数分为两部分
这一部分for all [indexed | hidden] columns"
控制着哪些列将会收集列的基本统计信息(目标列上的最小值, 最大值, 列上不同值的数量, 空值的数量等等). 系统默认值为 for all columns, 它将收集表上所有列(包括隐藏列)的基本的统计信息. 此外, 它的其他可选值如下所示:
FOR ALL INDEXED COLUMNS 指定只有含有索引的字段才能收集列的基本统计信息. 一般不推荐使用这个选项值, 因为在数据库环境中的所有 sql 语句所使用的字段, 比如 select 后面的字段, where 后面字段, group by 中的字段, 并不只是会引用含有索引的字段. |
FOR ALL HIDDEN COLUMNS 指定表中所有不可见的字段才能收集列的基本统计信息, 也就是说不会去收集表上实际可见的列的统计信息. 同样的一般也不推荐使用这个选项值. 这个选项值通常只用于这种情况, 在一个所有列的统计信息都是准确的表中新增了一个或几个不可见或者说是虚拟的列, 只需要收集这个或者这几个不可见列的统计信息, 而不再重复去其他列的统计信息, 那么就使用 for all hidden columns 这个选项. |
第二部分"Size [size_clause]"
控制收集直方图的方式, size 后面可以有以下选项
AUTO Oracle 自己决定根据列的统计信息(sys.col_usage$)以及列的数据倾斜程度(均匀分布程度)决定哪些列需要收集直方图 Integer 指定收集直方图的桶数, 桶数最小为 1 最大为 254 (针对 11g 及以前的版本, 12c 后没有这个限制).注意如果桶数为 1, 即 size 1 意味着不建立直方图, 如果已经有直方图的列则会删除该列的直方图. REPEAT 只在已经有直方图的列上重新收集直方图. repeat 会确保在全局级别上对已经存在直方图的列重新收集直方图. 一般不推荐使用这个选项, 因为新的直方图使用的桶数将不能超过旧的直方图中的桶数. 假设当前直方图中桶数为 5, 当使用 size repeat 重新收集直方图时, 新的直方图使用的桶数将不能超过 5 , 这钟方式可能不会取得好的效果. SKEWONLY 只在数据不均匀分布的列上收集直方图. 让ORACLE 自己判断列是否收集直方图 只要是列倾斜了 ORACLE就会收集直方图 OLTP系统用这个 非常坑爹 基本上所有列都要收集直方图 |
如果 method_opt 的默认参数 for all columns size auto 在你的数据环境不适用, 可能你遇到的情况属于下面两种情况:
1.除了指定的列, 在其它列上创建直方图
2.只在指定的列上创建直方图
一个稳定的系统收集统计信息的时候推荐使用method_opt=> 'for all columns size repeat',repeat表示以前收集过直方图,现在收集统计信息的时候就收集直方图,如果以前没收集过直方图,现在收集统计信息的时候就不收集。
有时候收集统计信息的时候,用method_opt => 'for all columns size auto',很有可能把当前的sql搞定了,但是把其他的sql搞悲剧了,这是因为auto表示Oracle根据谓词过滤信息(前文讲解直方图的时候提到过的where条件过滤),自动判断该列是否收集直方图。一个稳定的系统,不应该让Oracle去自动判断,自动判断很可能就会出事,比如某列不该收集直方图,设置auto过后它自己去收集直方图了,从而导致系统不稳定。
options
控制Oracle统计信息的刷新方式:
gather:重新分析整个架构
gather empty:只分析目前还没有统计的表
gather stale:只重新分析修改量超过10%的表(包括插入、更新和删除)
gather auto:重新分析当前没有统计的对象,以及统计数据过期(变脏)的对象。使用gather auto类似于组合使用gather stale和gather empty
degree
表示收集统计信息的时候并行度,并行度根据你系统配置以及当前系统可用资源自行设置。 一般degree设置4--8。一个CPU 一般可以开2个线程
DEGREE 就等于 show parameter cpu
你开并行8去收集统计信息,很有可能开 17个进程 ,1个进程作为主进程来协调其他16个并行进程,8个进程 进行 读取数据 另外8个进程 来进行 CPU运算 进行分析
cascade
表示收集表的统计信息时候同时收集索引的统计信息。其实收集索引的统计信息非常坑爹, 因为索引收集统计信息 是单块读。
no_invalidate
表示收集统计信息之后在共享池中引用了相关表的SQL游标是否失效。这个一定要设置为FALSE,默认是TRUE ,不然你可能在做SQL优化的时候,你发现明明更新了统计信息,但是执行计划还是没改变。
granularity
统计数据的收集,'ALL' - 收集所有(子分区,分区和全局)统计信息
① ALL:采集Global、partition、subpartition等粒度统计信息。
② AUTO:根据分区类型,由Oracle确定统计信息采集粒度。
③ PARTITION:只采集partition粒度统计信息。
④ SUBPARTITION:只采集subpartition粒度统计信息
partname
分区表的某个分区名
exec dbms_stats.flush_database_monitoring_info; --刷新sys.col_usage$ 和视图:sys.DBA_TAB_MODIFICATIONS select owner, table_name name, object_type, stale_stats, last_analyzed from dba_tab_statistics where table_name in (table_name) and owner = 'OWNER_NAME' and (stale_stats = 'YES' or last_analyzed is null); |
实验一查看统计信息是否过期
1.创建一个实验表 CREATE TABLE TEST AS SELECT * FROM DBA_OBJECTS; |
2.收集统计信息 BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SCOTT', tabname => 'TEST', estimate_percent => 100, method_opt => 'for all columns size auto', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; / |
3.刷新 exec dbms_stats.flush_database_monitoring_info; |
4.查看test表的统计的信息是否过期,显示空行表示没有过期 select owner, table_name name, object_type, stale_stats, last_analyzed from dba_tab_statistics where table_name in ('TEST') and owner = 'SCOTT' and (stale_stats = 'YES' or last_analyzed is null); -----结果空行----- |
5.删除20%的数据,让统计信息过期 select count(*) from test; delete from test where rownum<=72388*0.2; |
6.再次刷新 exec dbms_stats.flush_database_monitoring_info; |
7.查看统计信息是否过期,有结果返回表示统计信息过期 select owner, table_name name, object_type, stale_stats, last_analyzed from dba_tab_statistics where table_name in ('TEST') and owner = 'SCOTT' and (stale_stats = 'YES' or last_analyzed is null); OWNER NAME OBJECT_TYPE STA LAST_ANALYZED ------------------------------ ------------------------------ ------------ --- SCOTT TEST TABLE YES 2018-05-13 20:18:40 |
实验二 查看是什么操作让统计信息过期的脚本
select * from ( select * from ( select * from ( select u.name owner, o.name table_name, null partition_name, null subpartition_name, m.inserts, m.updates, m.deletes, m.timestamp, decode(bitand(m.flags,1),1,'YES','NO') truncated, m.drop_segments from sys.mon_mods_all$ m, sys.obj$ o, sys.tab$ t, sys.user$ u where o.obj# = m.obj# and o.obj# = t.obj# and o.owner# = u.user# union all select u.name, o.name, o.subname, null, m.inserts, m.updates, m.deletes, m.timestamp, decode(bitand(m.flags,1),1,'YES','NO'), m.drop_segments from sys.mon_mods_all$ m, sys.obj$ o, sys.user$ u where o.owner# = u.user# and o.obj# = m.obj# and o.type#=19 union all select u.name, o.name, o2.subname, o.subname, m.inserts, m.updates, m.deletes, m.timestamp, decode(bitand(m.flags,1),1,'YES','NO'), m.drop_segments from sys.mon_mods_all$ m, sys.obj$ o, sys.tabsubpart$ tsp, sys.obj$ o2, sys.user$ u where o.obj# = m.obj# and o.owner# = u.user# and o.obj# = tsp.obj# and o2.obj# = tsp.pobj# ) where owner not like '%SYS%' and owner not like 'XDB' union all select * from ( select u.name owner, o.name table_name, null partition_name, null subpartition_name, m.inserts, m.updates, m.deletes, m.timestamp, decode(bitand(m.flags,1),1,'YES','NO') truncated, m.drop_segments from sys.mon_mods$ m, sys.obj$ o, sys.tab$ t, sys.user$ u where o.obj# = m.obj# and o.obj# = t.obj# and o.owner# = u.user# union all select u.name, o.name, o.subname, null, m.inserts, m.updates, m.deletes, m.timestamp, decode(bitand(m.flags,1),1,'YES','NO'), m.drop_segments from sys.mon_mods$ m, sys.obj$ o, sys.user$ u where o.owner# = u.user# and o.obj# = m.obj# and o.type#=19 union all select u.name, o.name, o2.subname, o.subname, m.inserts, m.updates, m.deletes, m.timestamp, decode(bitand(m.flags,1),1,'YES','NO'), m.drop_segments from sys.mon_mods$ m, sys.obj$ o, sys.tabsubpart$ tsp, sys.obj$ o2, sys.user$ u where o.obj# = m.obj# and o.owner# = u.user# and o.obj# = tsp.obj# and o2.obj# = tsp.pobj# ) where owner not like '%SYS%' and owner not like '%XDB%' ) order by inserts desc ) where rownum<=50;
|
案列1 执行大批量的update,立即手动收集统计信息
我在10点收集了统计信息, 10点 过5分钟执行了 一个 大批量的 update操作 你在 10点10 执行查询,但是我发现查询变慢了怎么办? 也就是说,某个表会突然发生大批的DML操作怎么办? |
解决方法:
收集统计信息的脚本直接放update后面,如果不立即收集
那肯定要动态采样,动态采样默认是2 ,没用
这种至少要LEVEL 达到6,才可能有效果
如果是偶尔性质的,那么就要注意统计信息收集策略,当他发生变化了就立即收集
如果是经常性质的,那么就在SQL里面加上动态采样的HINT
SELECT owner, table_name, num_rows, sample_size, trunc(sample_size / num_rows * 100) estimate_percent FROM DBA_TAB_STATISTICS WHERE owner='SCOTT' AND table_name='TEST';
|
实验 size auto 的方法
1创建一个新的实验表 create table test as select * from dba_objects; |
2收集统计信息,这里注意方法是 size auto , Oracle 自己决定根据列的统计信息(sys.col_usage$)以及列的数据倾斜程度(均匀分布程度)决定哪些列需要收集直方图 BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SCOTT', tabname => 'TEST', estimate_percent => 30, method_opt => 'for all columns size auto', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; / |
3查看统计信息 select a.column_name, b.num_rows, a.num_distinct Cardinality, round(a.num_distinct / b.num_rows * 100, 2) selectivity, a.histogram, a.num_buckets from dba_tab_col_statistics a, dba_tables b where a.owner = b.owner and a.table_name = b.table_name and a.owner = 'SCOTT'
从上面的结果发现 HISTOGRAM返回的是none 没有直方图信息,是因为我们没有select查询, |
4接着我们执行select查询, SELECT COUNT(*) FROM TEST WHERE OWNER='SCOTT'; 再次收集统计信息方法同步骤2和再次查看是否收集直方图同步骤3 发现有where条件就可以收集直方图 |
实验 size repeat 的方法
1创建一个新的实验表 create table test as select * from dba_objects; |
2.收集统计信息,这里我们使用的size repeat只在已经有直方图的列上重新收集直方图. repeat 会确保在全局级别上对已经存在直方图的列重新收集直方图. |
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SCOTT', tabname => 'TEST', estimate_percent => 30, method_opt => 'for all columns size repeat', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; / 3查看统计信息 select a.column_name, b.num_rows, a.num_distinct Cardinality, round(a.num_distinct / b.num_rows * 100, 2) selectivity, a.histogram, a.num_buckets from dba_tab_col_statistics a, dba_tables b where a.owner = b.owner and a.table_name = b.table_name and a.owner = 'SCOTT' and a.table_name = 'TEST'; |
|
实验 对某个列(test表的owner列)收集直方图
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SCOTT', tabname => 'TEST', estimate_percent => 30, method_opt => 'for owner columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; / 这里 for all 换成for owner |
到此,关于“怎么理解Oracle统计信息”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: 怎么理解Oracle统计信息
本文链接: https://lsjlt.com/news/65315.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

 可以发现是删除导致统计信息过期
可以发现是删除导致统计信息过期 
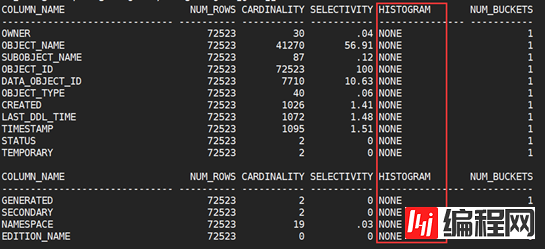 and a.table_name = 'TEST';
and a.table_name = 'TEST';

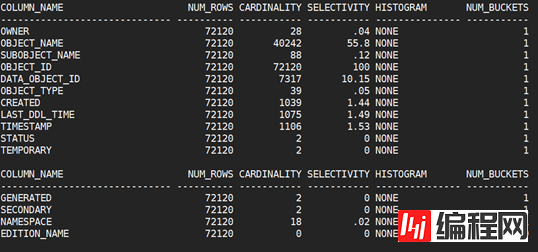 没有直方图的信息
没有直方图的信息
0