小编给大家分享一下terminating the instance due to error481导致ASM无法启动故障怎么办,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇
小编给大家分享一下terminating the instance due to error481导致ASM无法启动故障怎么办,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
1、现象
oracle 11g两个节点关机,进行硬件移动。
同时开机后,节点1正常,节点2开始能启动ASM实例,但是很快ASM实例就挂了,而且CRS服务也启动不了。
[oracle@shwmsdb1 ~]$ ps -ef|grep pmon
grid 14309 1 0 03:05 ? 00:00:01 asm_pmon_+ASM1
oracle 14382 14328 0 08:18 pts/1 00:00:00 grep pmon
oracle 15720 1 0 03:19 ? 00:00:06 ora_pmon_shwmsdb1
[oracle@shwmsdb2 ~]$ ps -ef|grep pmon
oracle 19298 19265 0 08:19 pts/1 00:00:00 grep pmon
2、分析原因
节点2启动数据库实例报错:
sql> startup nomount;
ORA-01078: failure in processing system parameters
ORA-01565: error in identifying file '+DATA/shwmsdb/spfileshwmsdb.ora'
ORA-17503: ksfdopn:2 Failed to open file +DATA/shwmsdb/spfileshwmsdb.ora
ORA-15077: could not locate ASM instance serving a required diskgroup
查看ASM告警日志:
节点2开机时候报错:
Fri Oct 27 03:43:07 2017
LMS0 started with pid=11, OS id=15250 at elevated priority
Fri Oct 27 03:43:07 2017
LMHB started with pid=12, OS id=15256
Fri Oct 27 03:43:07 2017
MMAN started with pid=13, OS id=15260
Fri Oct 27 03:43:07 2017
DBW0 started with pid=14, OS id=15264
Fri Oct 27 03:43:07 2017
LGWR started with pid=15, OS id=15268
Fri Oct 27 03:43:07 2017
CKPT started with pid=16, OS id=15272
Fri Oct 27 03:43:07 2017
SMON started with pid=17, OS id=15276
Fri Oct 27 03:43:07 2017
RBAL started with pid=18, OS id=15280
Fri Oct 27 03:43:07 2017
GMON started with pid=19, OS id=15284
Fri Oct 27 03:43:07 2017
MMON started with pid=20, OS id=15288
Fri Oct 27 03:43:07 2017
MMNL started with pid=21, OS id=15292
lmon reGIStered with NM - instance number 2 (internal mem no 1)
Fri Oct 27 03:45:07 2017
PMON (ospid: 15212): terminating the instance due to error 481
Fri Oct 27 03:45:07 2017
ORA-1092 : opitsk aborting process
Fri Oct 27 03:45:07 2017
System state dump requested by (instance=2, osid=15212 (PMON)), summary=[abnORMal instance termination].
System State dumped to trace file /u01/app/grid/diag/asm/+asm/+ASM2/trace/+ASM2_diag_15230.trc
Dumping diagnostic data in directory=[cdmp_20171027034507], requested by (instance=2, osid=15212 (PMON)), summary=[abnormal instance termination].
Fri Oct 27 03:45:07 2017
ORA-1092 : opitsk aborting process
Fri Oct 27 03:45:07 2017
License high water mark = 1
Instance terminated by PMON, pid = 15212
USER (ospid: 15331): terminating the instance
Instance terminated by USER, pid = 15331
ASM trc日志:
/u01/app/grid/diag/asm/+asm/+ASM2/trace/+ASM2_diag_15230.trc
Reconfiguration starts [incarn=0]
*** 2017-10-27 03:43:06.954
I'm the voting node
Group reconfiguration cleanup
kjzdattdlm: Can not attach to DLM (LMON up=[TRUE], DB mounted=[FALSE]).
kjzdattdlm: Can not attach to DLM (LMON up=[TRUE], DB mounted=[FALSE]).
kjzdattdlm: Can not attach to DLM (LMON up=[TRUE], DB mounted=[FALSE]).
*** 2017-10-27 03:43:08.186
kjzdattdlm: Can not attach to DLM (LMON up=[TRUE], DB mounted=[FALSE]).
kjzdattdlm: Can not attach to DLM (LMON up=[TRUE], DB mounted=[FALSE]).
kjzdattdlm: Can not attach to DLM (LMON up=[TRUE], DB mounted=[FALSE]).
节点1的ASM告警日志:
LMON (ospid: 14339) detects hung instances during IMR reconfiguration
LMON (ospid: 14339) tries to kill the instance 2 in 37 seconds.
Please check instance 2's alert log and LMON trace file for more details.
Fri Oct 27 03:45:04 2017
Remote instance kill is issued with system inc 10
Remote instance kill map (size 1) : 2
LMON received an instance eviction notification from instance 1
The instance eviction reason is 0x20000000
The instance eviction map is 2
Reconfiguration started (old inc 10, new inc 12)
[root@shwmsdb1 ~]# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
192.168.123.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
10.0.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
0.0.0.0 192.168.123.254 0.0.0.0 UG 0 0 0 eth2
[root@shwmsdb2 ~]# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
192.168.123.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
10.0.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth2
0.0.0.0 192.168.123.254 0.0.0.0 UG 0 0 0 eth2
在节点1缺少一条路由信息。
说明主机网卡USB0在动态获取169.254.XX.XX网段的IP地址。
IBM的PC服务器使用USB0做为管理网络的特性。没有连接USB0网卡的时候会不停向DHCP申请IP,如果没有发现DHCP时就会默认分配一个169.254.xxx.xxx的IP地址会和ORACLE的HAIP产生冲突,造成路由信息丢失
通过各种日志信息与文档中的信息的对比,得知此次的故障现象与文档中的故障现象是一致的。
3、解决办法
在节点1增加缺失的那条路由信息。
Execute the following as root on the node that's missing HAIP route:
# route add -net 169.254.0.0 netmask 255.255.0.0 dev eth2
在节点2执行以下语句:
Start ora.crsd as root on the node that's partial up:
# $GRID_HOME/bin/crsctl start res ora.crsd -init
grid执行路径:PATH=$PATH:$HOME/bin:/u01/app/11.2.0/grid/bin
节点2的CRS启动正常。
在节点1执行以下语句:
The other workaround is to restart GI on the node that's missing HAIP route with "crsctl stop crs -f" and "crsctl start crs" command as root.
[root@shwmsdb2 bin]# ./crsctl stop crs -f
卡住了。
用Ctrl+C结束。
但是节点1的CRS一直不正常。
用ps -ef|grep grid看到节点1有grid的卡死进程,kill 掉进程
kill -9 31307
两节点只剩下正常的grid进程。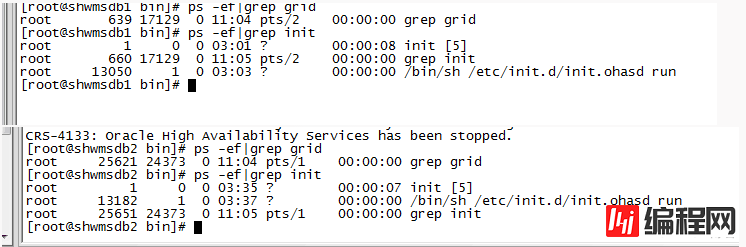
关闭两个节点的crs服务。
crsctl stop crs
正常关闭。
分别开启两个节点的crs服务。
crsctl start crs
开启完毕后执行:
ps -ef|grep grid
ps -ef|grep oracle
crsctl stat res -t
都显示正常。
两边执行crs_stat -t,也都正常。
[grid@shwmsdb2 ~]$ crs_stat -t
Name Type Target State Host
------------------------------------------------------------
ora.CRS.dg ora....up.type ONLINE ONLINE shwmsdb1
ora.DATA.dg ora....up.type ONLINE ONLINE shwmsdb1
ora.FRA.dg ora....up.type ONLINE ONLINE shwmsdb1
ora....ER.lsnr ora....er.type ONLINE ONLINE shwmsdb1
ora....N1.lsnr ora....er.type ONLINE ONLINE shwmsdb2
ora.asm ora.asm.type ONLINE ONLINE shwmsdb1
ora.cvu ora.cvu.type ONLINE ONLINE shwmsdb2
ora....network ora....rk.type ONLINE ONLINE shwmsdb1
ora.oc4j ora.oc4j.type ONLINE ONLINE shwmsdb2
ora.ons ora.ons.type ONLINE ONLINE shwmsdb1
ora....ry.acfs ora....fs.type ONLINE ONLINE shwmsdb1
ora.scan1.vip ora....ip.type ONLINE ONLINE shwmsdb2
ora.shwmsdb.db ora....se.type ONLINE ONLINE shwmsdb1
ora....SM1.asm application ONLINE ONLINE shwmsdb1
ora....B1.lsnr application ONLINE ONLINE shwmsdb1
ora....db1.ons application ONLINE ONLINE shwmsdb1
ora....db1.vip ora....t1.type ONLINE ONLINE shwmsdb1
ora....SM2.asm application ONLINE ONLINE shwmsdb2
ora....B2.lsnr application ONLINE ONLINE shwmsdb2
ora....db2.ons application ONLINE ONLINE shwmsdb2
ora....db2.vip ora....t1.type ONLINE ONLINE shwmsdb2
至此,两节点的crs和asm都正常。
4、故障总结
IBM 的x3850 x5系列的PC Server存在USB开启dhcp功能,从而导致usb网卡可能占用HAIP的缺陷,生产环境中的此类机器上运行的RAC数据库环境,需要关闭USB0的自动获取dhcp功能,给USB0配置静态IP。
打算两节点都删除USB0。
[root@shwmsdb1 ~]# /sbin/ifdown usb0
[root@shwmsdb1 ~]# cd /etc/sysconfig/network-scripts
[root@shwmsdb1 network-scripts]# cat ifcfg-usb0
# IBM RNDIS/CDC ETHER
DEVICE=usb0
BOOTPROTO=dhcp
ONBOOT=no
HWADDR=5e:f3:fd:35:86:33
[root@shwmsdb1 network-scripts]# mv ifcfg-usb0 ifcfg-usb0.bak
[root@shwmsdb1 network-scripts]# ls
ifcfg-eth0 ifdown-bnep ifdown-isdn ifdown-sl ifup-eth ifup-ipx ifup-ppp ifup-wireless
ifcfg-eth2 ifdown-eth ifdown-post ifdown-tunnel ifup-ib ifup-isdn ifup-routes init.ipv6-global
ifcfg-lo ifdown-ippp ifdown-ppp ifup ifup-ippp ifup-plip ifup-sit net.hotplug
ifcfg-usb0.bak ifdown-ipsec ifdown-routes ifup-aliases ifup-ipsec ifup-plusb ifup-sl network-functions
ifdown ifdown-ipv6 ifdown-sit ifup-bnep ifup-ipv6 ifup-post ifup-tunnel network-functions-ipv6
[root@shwmsdb1 network-scripts]# ifconfig -a
eth0 Link encap:Ethernet HWaddr 5C:F3:FC:DA:86:80
inet addr:10.0.0.89 Bcast:10.0.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:65714 errors:0 dropped:0 overruns:0 frame:0
TX packets:15916 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5327553 (5.0 MiB) TX bytes:1627321 (1.5 MiB)
Interrupt:169 Memory:92000000-92012800
eth0:2 Link encap:Ethernet HWaddr 5C:F3:FC:DA:86:80
inet addr:10.0.0.90 Bcast:10.0.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:169 Memory:92000000-92012800
eth0:3 Link encap:Ethernet HWaddr 5C:F3:FC:DA:86:80
inet addr:10.0.0.100 Bcast:10.0.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:169 Memory:92000000-92012800
eth2 Link encap:Ethernet HWaddr 5C:F3:FC:DA:86:82
inet addr:192.168.123.1 Bcast:192.168.123.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1536228 errors:0 dropped:0 overruns:0 frame:0
TX packets:1539186 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:729154172 (695.3 MiB) TX bytes:801250137 (764.1 MiB)
Interrupt:217 Memory:94000000-94012800
eth2:1 Link encap:Ethernet HWaddr 5C:F3:FC:DA:86:82
inet addr:169.254.66.26 Bcast:169.254.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:217 Memory:94000000-94012800
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:529225 errors:0 dropped:0 overruns:0 frame:0
TX packets:529225 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:137382526 (131.0 MiB) TX bytes:137382526 (131.0 MiB)
usb0 Link encap:Ethernet HWaddr 5E:F3:FD:35:86:33
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
重启服务器后在ifconfig -a里面会没有usb0
问题解决。
以上是“terminating the instance due to error481导致ASM无法启动故障怎么办”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注编程网数据库频道!
--结束END--
本文标题: terminating the instance due to error481导致ASM无法启动故障怎么办
本文链接: https://lsjlt.com/news/65175.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0