一.什么是hadoop? Hadoop是Apache旗下的一套开源软件平台,是用来分析和处理大数据的软件平台。 Hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑, 对海量数据进行分布式处理。3.Hadoop的核心组
Hadoop是Apache旗下的一套开源软件平台,是用来分析和处理大数据的软件平台。
Hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑, 对海量数据进行分布式处理。
3.Hadoop的核心组件:由底层往上分别是 hdfs、Yarn、MapReduce。
4.广义上来说,Hadoop通常指的是指一个更广泛的概念->Hadoop生态 圈。
5.云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚 拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助 IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业 务模式,把强大的计算能力提供给终端用户。
6.现阶段,云计算的两大底层支撑技术为虚拟化和大数据技术。
7.HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更 不等同于云计算本身。
8.HADOOP应用于数据服务基础平台建设。
9.HADOOP用于用户画像。
10.HADOOP用于网站点击流日志数据挖掘
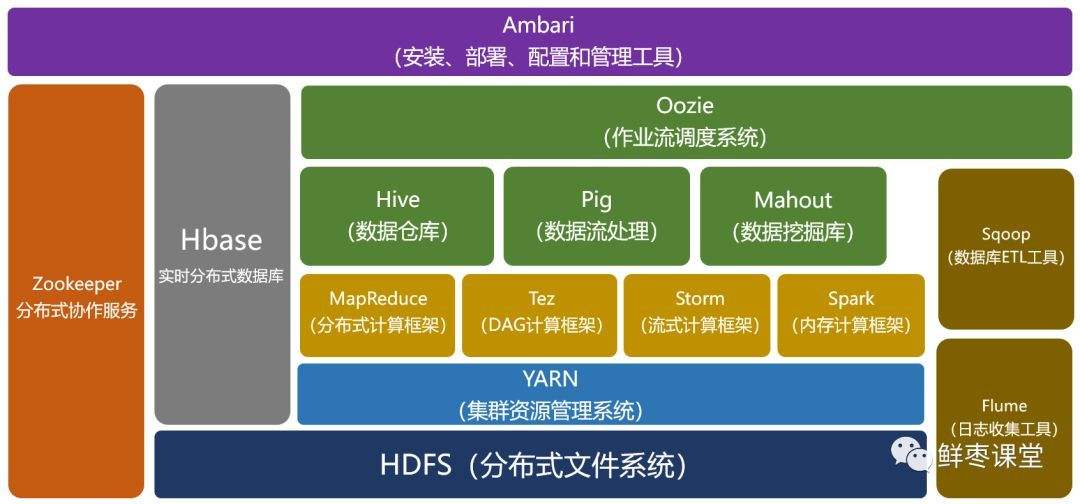
HDFS是块级别的分布式文件存储系统。是hadoop中数据存储管理的基础,具有高度容错性,能检测和应对硬件故障。
包含四个部分:HDFS Client、NameCode(nn)、DataNode(dn)、Secondary NameCode(2nn)
HDFS Client:就是客户端。NameCode(nn):元数据节点,存储文件的元数据。如文件名、文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在得到DataNode等;管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求;
它是描述数据的数据,相当于图书馆的检索系统。
DataNode(dn):数据节点,在本地文件系统存储文件块数据,以及块数据的校验和。
存储实际的数据,汇报存储信息给namenode,相当于书柜。
Secondary NameCode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode
Yarn顾名思义 管理资源的 那么具有足够的通用性,可以支持其他的分布式计算模式。
Yarn还能很方便的管理诸如Hive、HBase、Pig、spark/Shark等应用。
Yarn可以使各种应用互不干扰的运行在同一个Hadoop系统中,实现整个集群资源的共享。
包含两个进程:Nodemanager,ResourceManager
mapreduce是一种采用分而治之的分布式计算框架,用于处理数据量大的计算。
如一复杂的计算任务,单台服务器无法胜任时,可将此大任务切分成一个个小的任务,小任务分别在不同的服务器上并行的执行;最终再汇总每个小任务的结果
MapReduce由两个阶段组成:
Map阶段(切分成一个个小的任务)
Reduce阶段(汇总小任务的结果)
用户只需实现map()和reduce()两个函数,即可实现分布式计算
执行流程图如下:
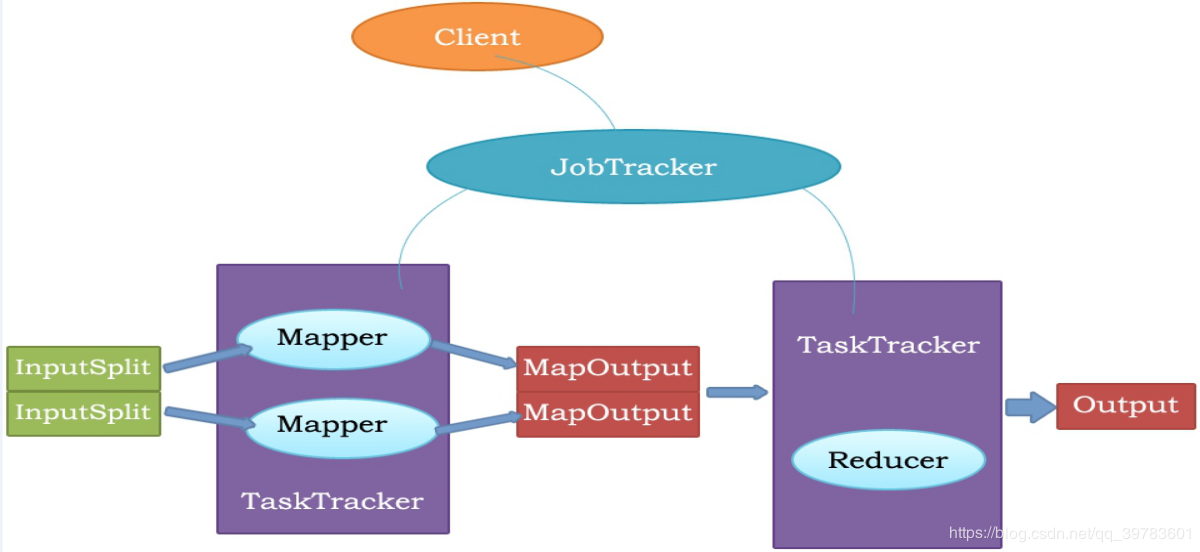
jobtracker
master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
tacktracker
slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
map task
解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
reduce task
从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行
原理图如下:
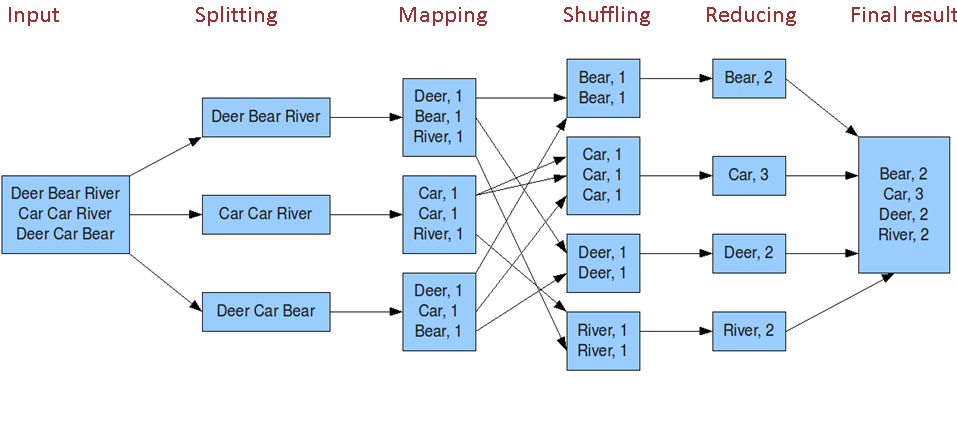
总体来说:是个总分总的结构,先分解成多个小任务,在map阶段处理完成后,汇总成少数个小任务server在Reduce阶段处理进行排序 分组等操作。
Map阶段解说:先把一个大任务分解split成多个小任务
(1) 读取HDFS中的文件。每一行解析成一个
(2)覆盖map(),接收(1)产生的
(3)对(2)输出的
(4)对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:
(5)(可选)对分组后的数据进行归约。
Rduce阶段解说:把map阶段的结果进行汇总
(1)多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
(2)对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑,
(3)对reduce输出的
参考文献:
https://www.jianshu.com/p/f1e785fffd4d,
Https://blog.csdn.net/qq_39783601/article/details/104928348,
https://blog.csdn.net/zcb_data/article/details/80402411,
https://www.cnblogs.com/ahu-lichang/p/6645074.html.
--结束END--
本文标题: Hadoop-谈谈你对Hadoop的正确认识和理解
本文链接: https://lsjlt.com/news/6459.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0