这篇文章主要介绍“oracle Exadata存储服务器原理是什么”,在日常操作中,相信很多人在Oracle Exadata存储服务器原理是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,
这篇文章主要介绍“oracle Exadata存储服务器原理是什么”,在日常操作中,相信很多人在Oracle Exadata存储服务器原理是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Oracle Exadata存储服务器原理是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Exadata Storage Server的机制
Exadata的I/O流程
Exadata的抗故障性
–“Storage”故障时,DB的操作
Exadata的Patch Version
–Grid Infrastructure / DB Patch : 11.2.0.3.8 等的5行
第1-4位 :PSR的Version
第5位 :Database Patch for Exadata的Version
–Exadata Storage Server Software Patch : 11.2.3.1.1 等的5行
第1,2位 :表示Oracle Database的 “major release number”
例)与Oracle Database 11.2.0.3 的情况的「11.2」相同
第3位 :一般表示Oracle Database的 “component-specific release number”。
例)与Oracle Database 11.2.0.3 情况的「3」相同
※11.2.2.4.2对应11.2.0.3
第4位 :表示Oracle Exadata Storage Server Software的 “major release number”。
第5位 :表示Oracle Exadata Storage Server Software 的PSR的版本。
Exadata 架构(全景)
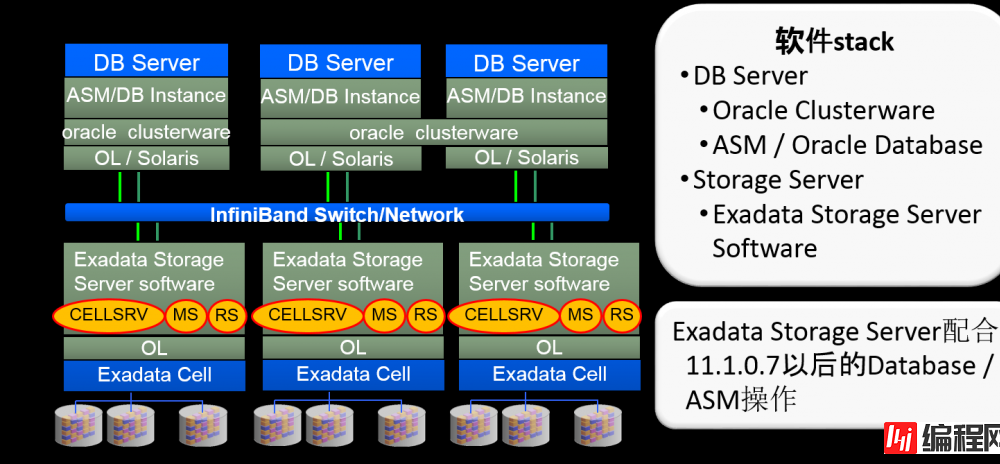
InfiniBand Network
OL/Solaris中需要安装ofed驱动
执行DB Server、DB Server 以及Cell Server之间的信息交换
Cell之间无法互相交换信息。跨越多个cell的操作安装在DB Server中
→实现Cell的完全Scale-out
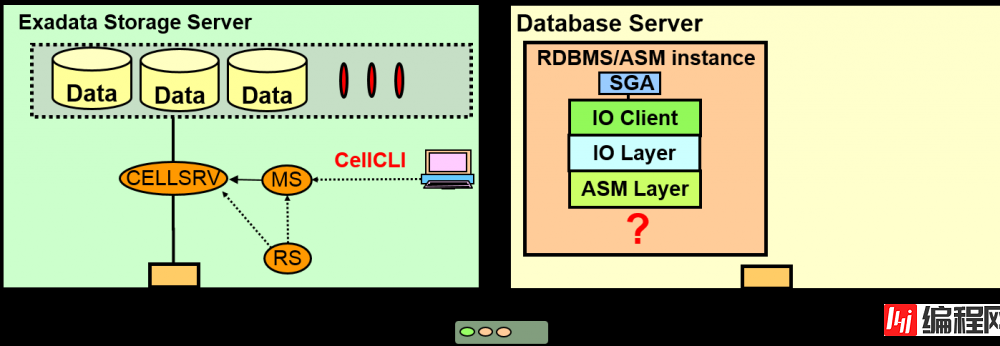
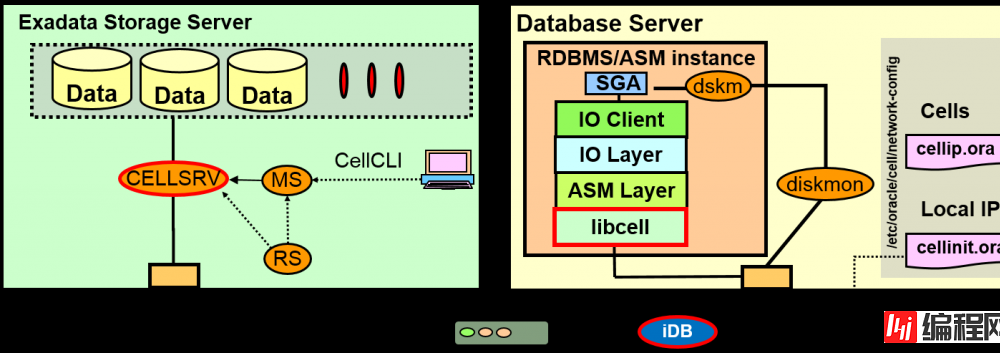
Exadata Storage Server上有哪些进程?
oracle是如何连接ASM/DB的IO/ASM层到Exadata 存储服务器的?
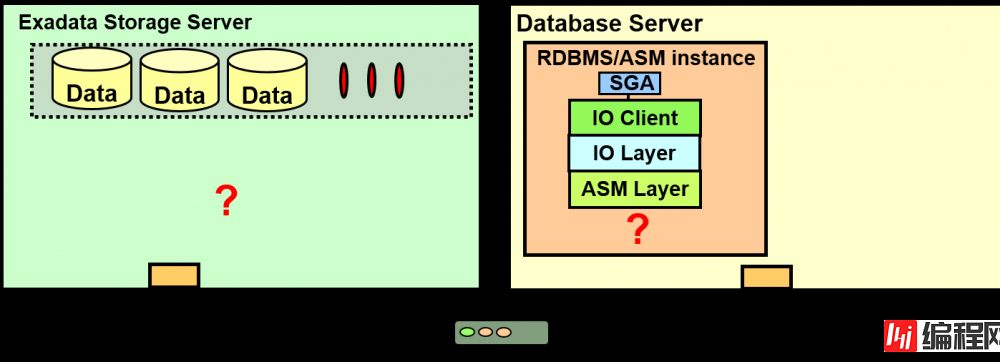
Cell Server(CELLSRV)负责与DB Server的信息交换。于是变成多线程,各个线程对磁盘与网络执行非同步I/O
Management Server (MS)管理制成grid disk,变更H/W、SNMPTrap、警报、email通知、缺点
Restart Server (RS) 监视CELLSRV与MS。进程的存亡、内存使用状況等。
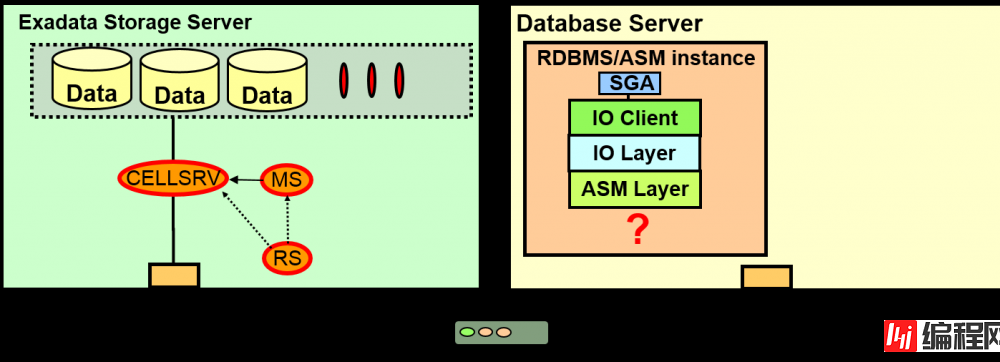
通过Exadata Storage Server Software检测HW故障的机制
MS为Exadata的Hardware故障, 检测Software故障
–也可以从CellCLI 查看HW故障
Exadata 可以内部通过MS直接与ILOM通信,获得信息
–对于ILOM中自节点的eth0 (management eth)的IP, SNMP trap会跳过。
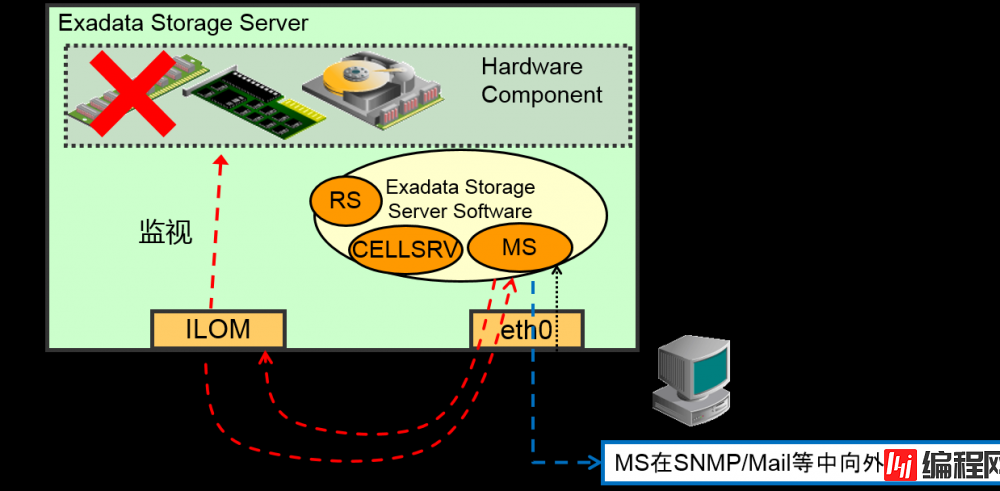
CellCLI是Exadata中管理各Cell的utility。可以变更Exadata Storage Server 的设定、展示警报历史警报历史、 展示metric、进行维护
与Management Server (MS)通信,管理通信Storage cell
■ 从CellCLI 观察的情况
[root@cell01] # cellcli -e list cell detail | tail -n 3
cellsrvStatus: running
msStatus: running
rsStatus: running
■ 从ps 中观察的情况
CELLSRV 进程
[root@cell01] # ps -ef | grep "bin/cellsrv " | grep -v grep
root 13085 13084 【略】 /opt/oracle/cell11.2.3.1.1_linux.X64_120607/cellsrv/bin/cellsrv 100 5000 9 5042
RS 进程
[root@cell01] # ps -ef | grep cellrssrm | grep -v grep
root 11081 1 【略】 /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/bin/cellrssrm■ 从ps 中观察的情况 续表MS 进程[root@cell01]# ps -ef | grep oc4j | grep -v grep
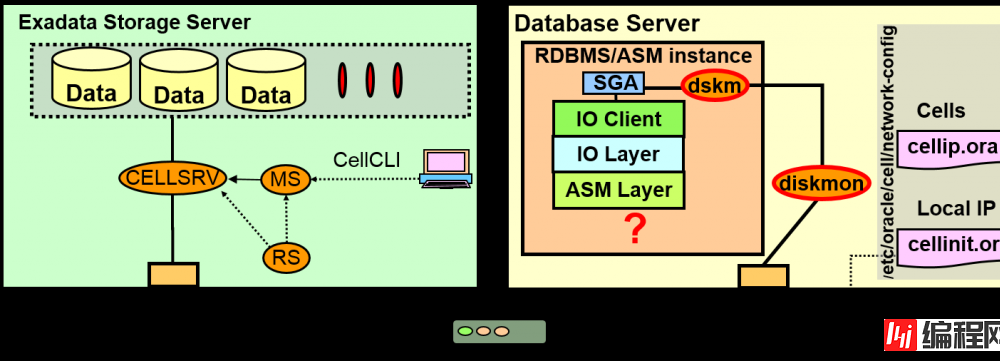
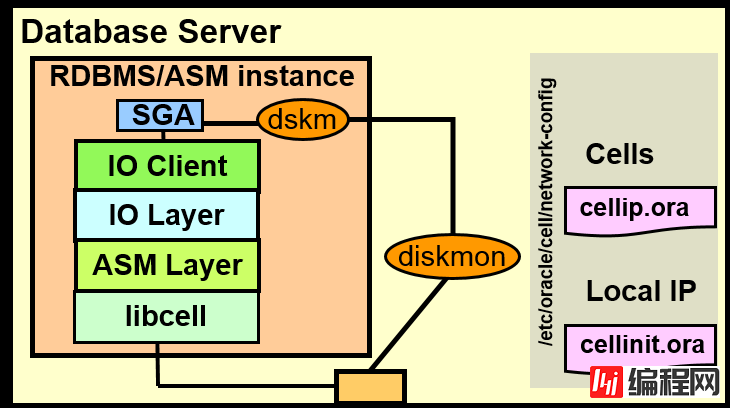
root 12093 12092 【略】 /usr/java/jdk1.5.0_15/bin/java -Xms256m -Xmx512m -Djava.library.path=/opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/lib -Ddisable.checkForUpdate=true -jar /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/oc4j/ms/j2ee/home/oc4j.jar -out /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/deploy/log/ms.lst -err /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/deploy/log/ms.errMaster diskmon (diskmon) 通过CRS,与CSS同时启动与CELLSRV通信
Slave diskmon (dskm) 作为各个实例的一部存在与master进行通信
执行检测Cell故障,分配IO fencing 、IO资源管理
Cellinit.ora
决定Cellinit.ora到底使用哪个网络界面,与哪个存储交换信息(指定InfiniBand的bondib0)
# cat /etc/oracle/cell/network-config/cellinit.ora
ipaddress1=192.168.20.81/22
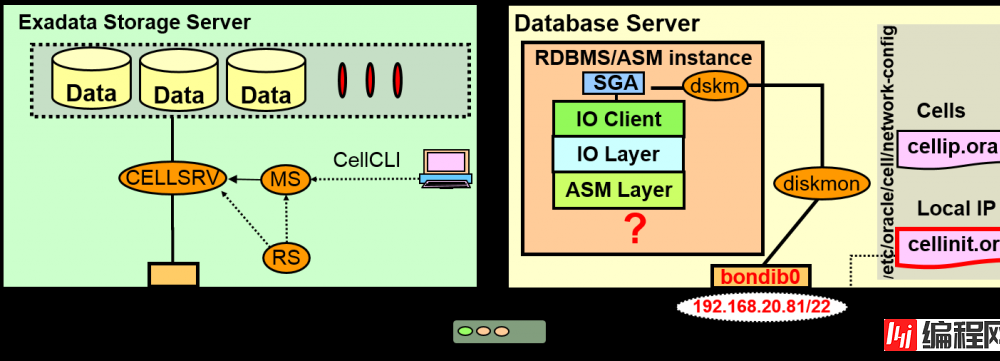
Cellip.ora存储cell的列表 增加新的cell时可以动态加入到cellip.ora
# cat /etc/oracle/cell/network-config/cellip.ora
cell=”192.168.20.91”
cell=”192.168.20.92”
cell=”192.168.20.93”
diskmon 与 dskm
■ 从crsctl 中观察的情况
[root@db01] # /u01/app/11.2.0.3/grid/bin/crsctl stat res -t -init | grep -A2 diskmon
ora.diskmon
1 ONLINE ONLINE katana01m
■ 从ps 中观察的情况
diskmon 进程
[root@db01] # ps -ef | grep diskmon | grep -v grep
oracle 24362 1 0 Aug06 ? 00:01:00 /u01/app/11.2.0.3/grid/bin/diskmon.bin -d –f
dskm 进程
[root@db01] # ps -ef | grep dskm | grep -v grep
oracle 22500 1 0 Aug09 ? 00:00:00 ora_dskm_dgprmy1
oracle 25083 1 0 Aug06 ? 00:00:00 asm_dskm_+ASM1
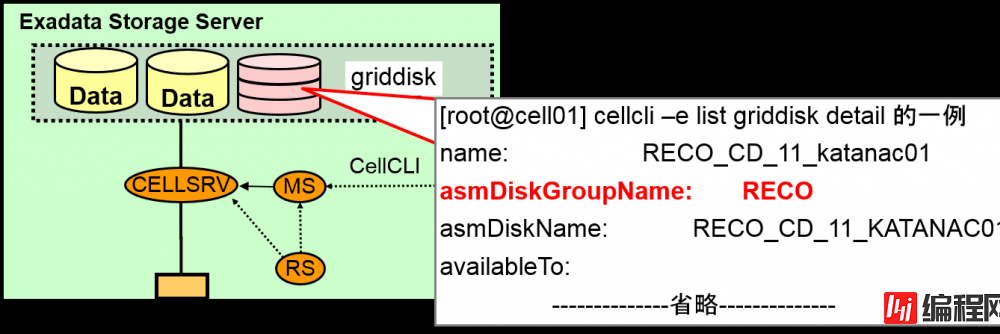
Cell Server认识DB Server的机制
各Griddisk如果在member中分配的话,被分配的Diskgroup的名字就会作为attribute登录
如果有Cell的磁盘故障的情况的话,就会以这个属性为基础,从Diskgroup中,对对应的ASM磁盘进行drop
DB/ASM通过Libcell(library)与CELLSRV通信
通信中,使用iDB 协议
Exadata存储通信中使用的Exadata固有的协议
基于RDS协议来构筑的InfiniBand上的操作
Exadata Storage Server Software的警报日志
追踪文件以及警报日志在Automatic Diagnostic Repository(ADR)中配置
alert.log (from RS and CELLSRV), ms-odl.log, ms-odl.trc, rs*trc, svtrc*.trc
与Oracle Database相同,可以使用ADRCI进行管理

日志文件、追踪文件
Cell的日志
–$ADR_BASE/diag/asm/cell/<hostname>/trace/
–存在CELLSRV、RS、MS的警报日志以及追踪文件
alert.log : CELLSRV与RS的警报日志
ms-old.log / ms-old.trc : MS的警报日志与追踪文件
svtrc_<pid>_<tid>.trc (svtrc_13661_0.trc) : CELLSRV的追踪文件
rstrc_<pid>_<tid>.trc (rstrc_27528_4.trc) : RS的追踪文件
Diskmon的日志文件
–$ORA_CRS_HOME/log/<hostname>/diskmon/
diskmon.log 与 diskmon.l01 ~ diskmon.l10
进程、设定文件等一览(数据库中)
diskmon、dskm
master diskmon (diskmon) 与CSS同时启动,与CELLSRV通信。
Slave diskmon (dskm)是各个实例的一部分,与master diskmon通信。
cell故障以及I/Ofencing、I/O资源管理计划
cellip.ora
DB服务器使用的cell的机器IP列表
cellinit.ora
DB服务器在与cell的通信中使用的本地IP
CELLSRV
CELLSRV中1个cell中1个进程(多线程)。线程对磁盘以及网络会执行非同步IO。
MS
制成/删除Grid磁盘、变更H/W、展示、管理SNMP trap、警报、缺点。
RS
监视CELLSRV与MS。RS监视进程存亡、
内存使用率等。Backup RS监视Core RS。
CellCLI
执行用户操作与构成的命令行工具
各进程的作用
| 进程 | 服务器 | 作用 |
| CELLSRV | Exadata | 对于磁盘以及网络发现非同步IO。 |
| MS | Exadata | 制成/删除Grid磁盘、变更H/W、展示、管理SNMP trap、警报、缺点 |
| Core RS | Exadata | 监视CELLSRV与MS。监视进程存亡以及、内存使用率。 |
| Backup RS | Exadata | 监视Backup RS与Core RS |
| Diskmon | DB Server | 与CSS同时启动、与CELLSRV通信。cell故障以及I/Ofencing、I/O资源管理计划的传播 |
| Dskm | DB Server | 各实例的后台进程中与master diskmon通信。 |
通过RS进程进行的监视①
alter cell startup services all 执行时 (Backup RS的启动)
Core RS 进程
[root@cell01] # ps -ef | grep cellrssrm | grep -v grep
root 11081 1 【略】 /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/bin/cellrssrm
Backup RS 进程
[root@cell01] # ps -ef | grep cellrsbkm | grep -v grep
root 11089 11087 【略】 /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/bin/cellrsbkm -rs_conf /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/deploy/config/cellinit.ora -ms_conf /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/deploy/config/cellrsms.state -cellsrv_conf /opt/oracle/cell11.2.3.1.1_LINUX.X64_120607/cellsrv/deploy/config/cellrsos.state -debug 0

通过RS进程进行监视②
alter cell startup services all 执行时 (CELLSRV , MS的启动)
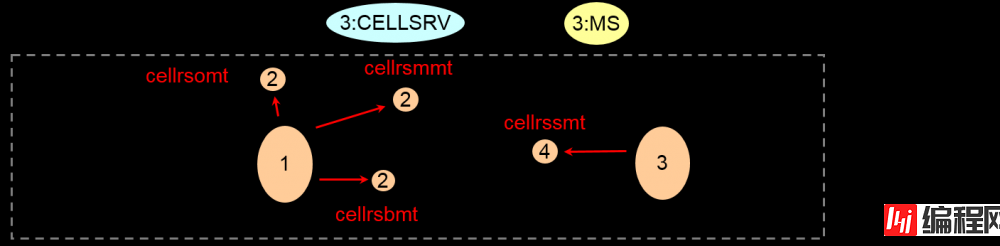
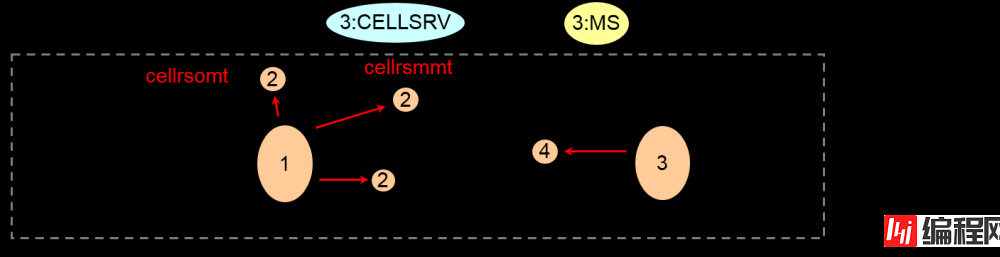
监视对象的进程启动时就会生成监视这些项目的进程。
监视进程:
–cellrSSMt – server monitoring process
–cellrsbmt – backup monitoring process
–cellrsomt – oss (outdated name of cellsrv) monitoring process
–cellrsmmt – ms monitoring process
All names prefixed with cellrs
monitoring procs suffixed with mt
制成Heartbeat与incident
Cellrsmmt检测MS的Http端口是否存在,以及MS的内存使用量是否在规定范围内
Cellrsomt检测CELLSRV是否存在
Heartbeat失败时,服务重启。
–服务重启之前,监视进程会生ADR incident
通过ps 观察的监视进程①
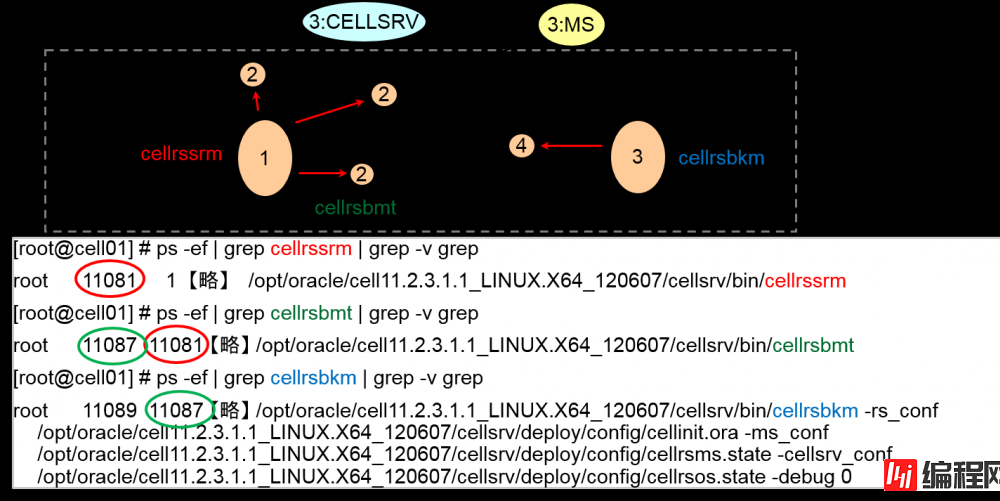
通过ps 观察的监视进程②
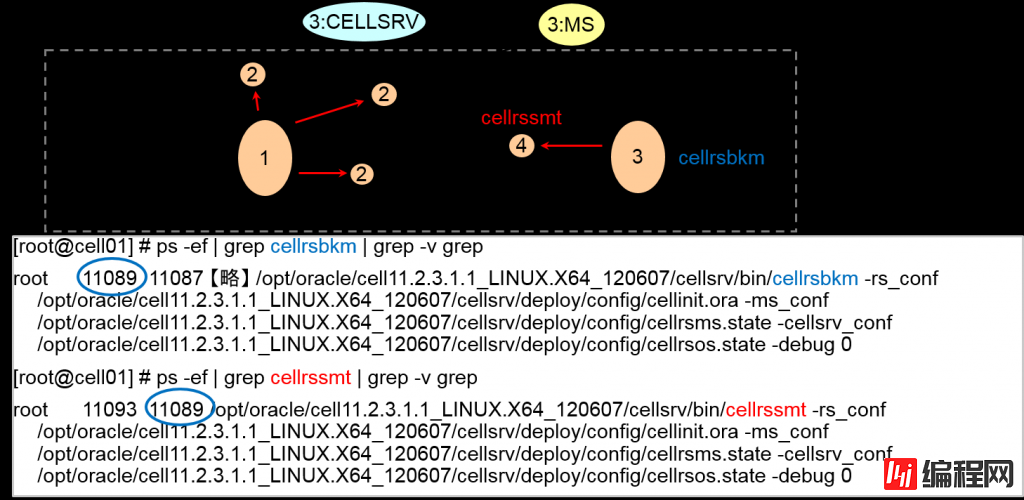
通过ps 观察的监视进程③
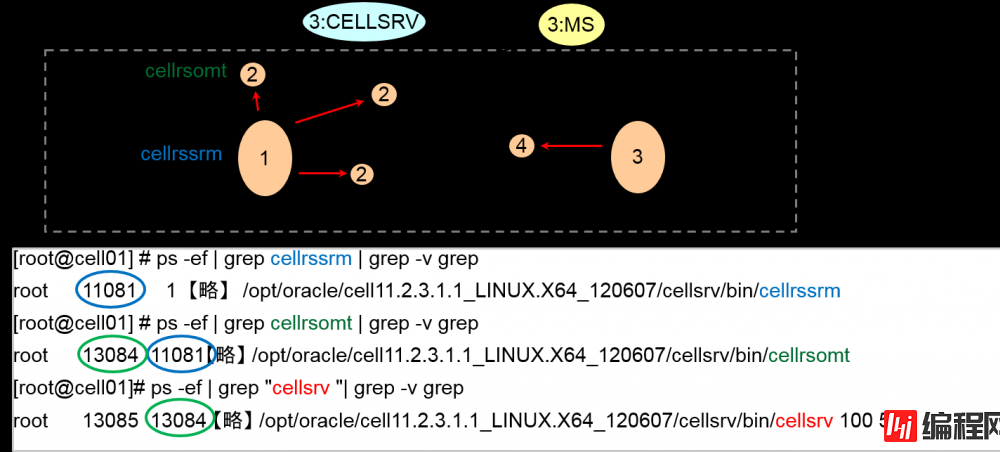
通过ps 观察的监视进程④
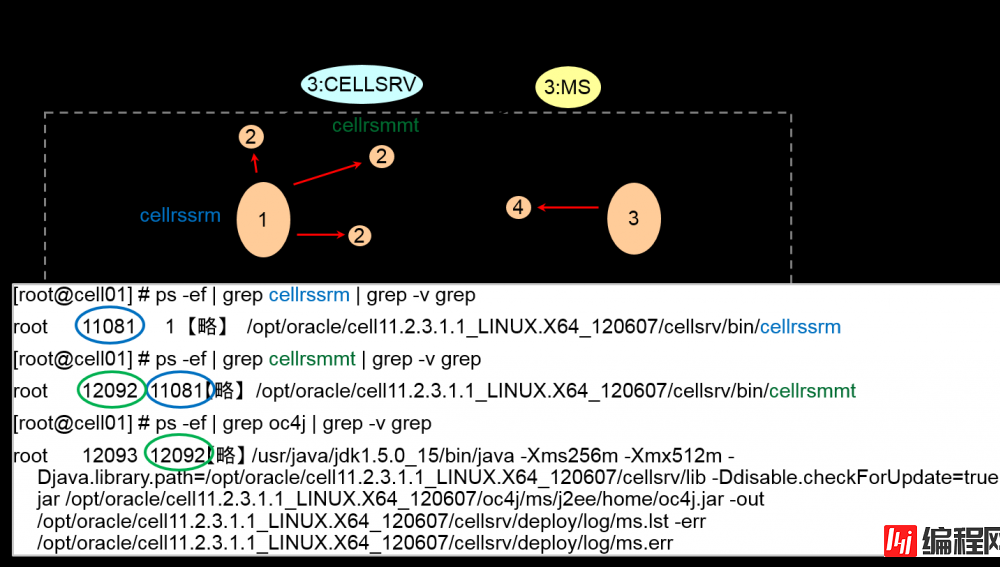
主要进程故障时的操作①
监视进程可以检测到进程故障时,并重启故障进程
警报记录在$ADR_BASE/diag/asm/cell/<hostname>/trace/alert.log中
重新启动花费数秒
Core RS进程故障时的操作(观察警报日志就可以明白的操作)
【Thu Aug 23 20:25:40 jsT 2012 : kill Core RS进程】
-------------------------------------------------------------------------------
Thu Aug 23 20:25:41 2012 : RS-7445 [Serv RS_MAIN is absent] [It will be restarted]
Thu Aug 23 20:25:42 2012 : cellrsomt / cellrsbmt / cellrsmmt をshotdown
Thu Aug 23 20:25:43 2012 : [RS] Started Service RS_MAIN with pid 26177
Thu Aug 23 20:25:43 2012 : cellrsomt / cellrsbmt / cellrsmmt 新pid重新启动
-------------------------------------------------------------------------------
【另外、CELLSRV / MS /Backup RS 进程之父为”1”】Backup RS 进程故障时的操作(观察警报日志就可以明白的操作)
【 Thu Aug 23 20:47:56 :kill Backup RS进程】
-------------------------------------------------------------------------------
Thu Aug 23 20:47:57 2012 : RS-7445 [Serv RS_BACKUP is absent] [It will be restarted]
Thu Aug 23 20:47:58 2012 : cellrssmt をshotdown
Thu Aug 23 20:47:58 2012 : [RS] Started Service RS_BACKUP with pid 28476
Thu Aug 23 20:47:58 2012 : cellrssmt を新たしいpidでMS 进程故障时的操作(观察警报日志就可以明白的操作)
【Thu Aug 23 20:55:44 JST 2012 : kill MS进程】
-------------------------------------------------------------------------------
Thu Aug 23 20:55:44 2012 : RS-7445 [Serv MS is absent] [It will be restarted]
: [RS] Started Service MS with pid 3839CELLSRV 进程故障时的操作(观察警报日志就可以明白的操作)
【Thu Aug 23 20:38:56 JST 2012 : kill CELLSRV 进程】
-------------------------------------------------------------------------------
Thu Aug 23 20:38:56 2012 : RS-7445 [Serv CELLSRV is absent] [It will be restarted]
:通过新的pid重启cellrsomt
Thu Aug 23 20:38:59 2012 : FlashLog的有效化
Thu Aug 23 20:38:59 2012 : [RS] Started Service CELLSRV with pid 9593
Thu Aug 23 20:39:00 2012 : diskmon的Heartbeat开始
Thu Aug 23 20:39:03 2012 : FlashCache的有效化Exadata的I/O的种类
Block I/O
–一个或者多个的Database Block的I/O
Smart I/O
–Filtering(行filtering )以及 Predicate evaluation(列filtering )通过Storage Server来执行
–Storage Server中的数据处理結果返回到DB Server中,执行剩余处理
Smart I/O的种类
Smart Scan
–行的filtering :仅将必需的行返回到DB服务器中
–列的filtering :仅将必需的列返回到DB服务器中
–Join filtering :使用Bloom filter,結合之前,会执行cell中的filtering
–索引扫描:index fast full scan的话就会执行Smart Scan
Smart Incremental Backup (増量备份)
–仅仅读入有变更的块
RMAN列表
–在cell中unload数据块格式
创建表空间、数据文件
–在cell中unload数据块格式
Smart I/O的操作
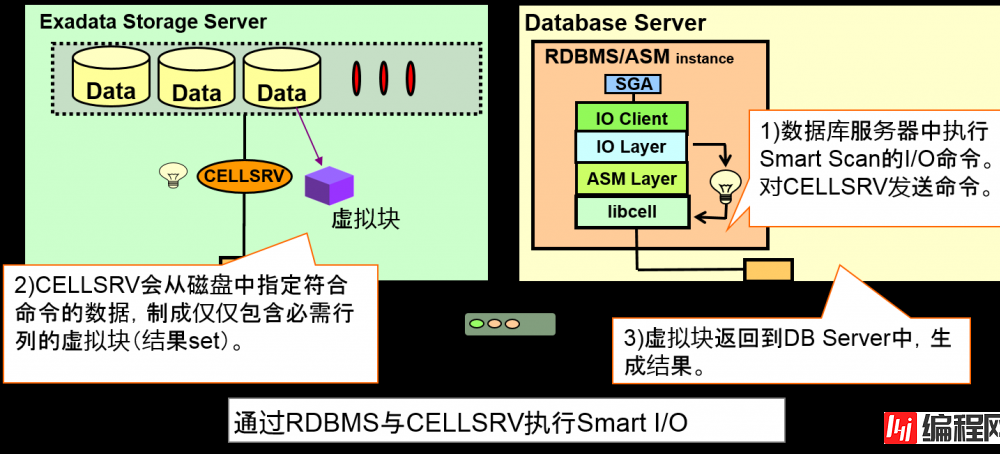
Smart Scan的选择
Smart Scan仅仅在Direct Path Read中执行。
–不通过SGA(缓冲区高速缓存),直接读入到PGA中
–采用Direct Read的案例(11g)
并行执行的情况
串行执行的全表扫描中,表尺寸较大的情况
→ 花费时间较长的并行查询以及全表扫描等处理都会成为Smart Scan的对象。
CBO的判断步骤
1.与CBO是否使用Exadata无关,直接以Global水平制成执行计划
Exadata以外操作相同
2.觉得是否进行Direct lead
Exadata以外操作相同
3.如果Exadata上已经存在对象文件,就会使用smart scan
※从11.2.0.3.8开始,追加Exadata固有的获得系统统计的功能,Optimizer可以制成关照到使用了Exadata的情况的计划了。
Optimizer的演进
至此的调优中,都是不考虑Exadata制成制成计划的
缺点的例子之一:”Exadata的Full Table Scan”很快,但选择了Index Range Scan
11.2.0.3.8以后、系统统计的选项中,通过追加了Exadata 选项得到改善
验证环境
–Exadata V2 Half 11.2.0.3.9 / 11.2.3.1.1
–表 test_tbl
约60,000,000行
数据量:約 9GB
Seqid列: 数字的1开始的连续数字(※制成unique index)
查询:Create table <tname> as select * from test_tbl where seqid < 10,000
※元表:60,000,000行。缩小为1/6,000
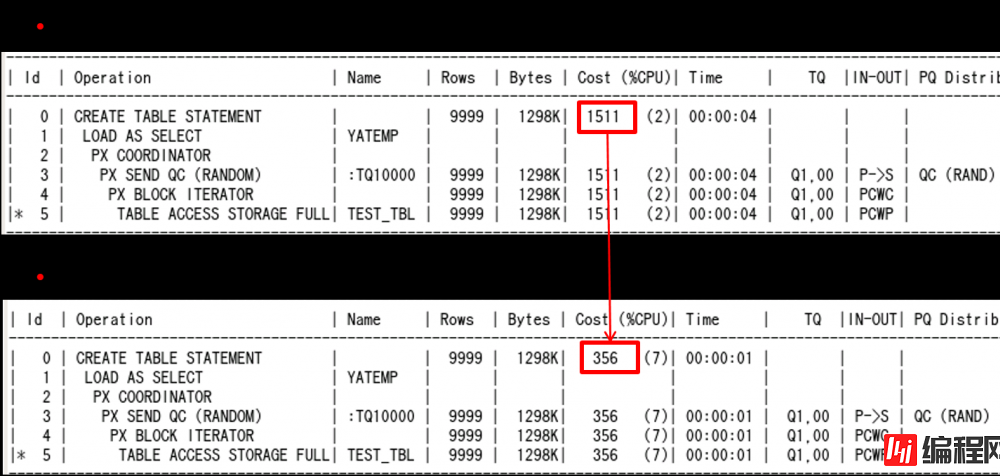
Default的plan中包含index range scan

查询:Create table <tname> as select * from test_tbl t where seqid < 10,000
※元表:60,000,000行。缩小为1/6,000
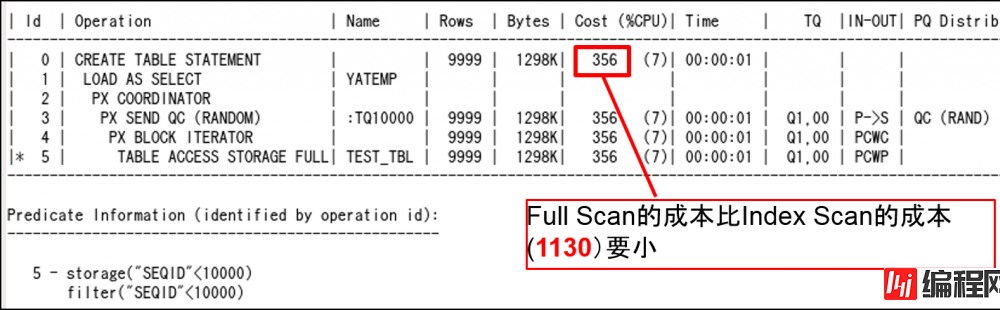
Full scan选项时的plan
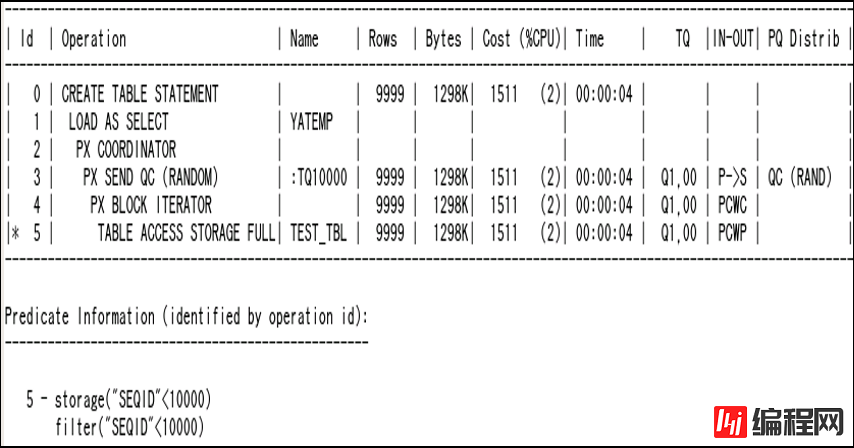
11.2.0.3.8 中的Cost计算①
此前的对策: 删除index或者invisible化
–对其他查询有影响
11.2.0.2.18 / 11.2.0.3.8中的Optimizer
–Exadata的话,Full Scan的成本估计比起之前降低了
Scan成本的计算式 (Number of blocks to read)/MBRC
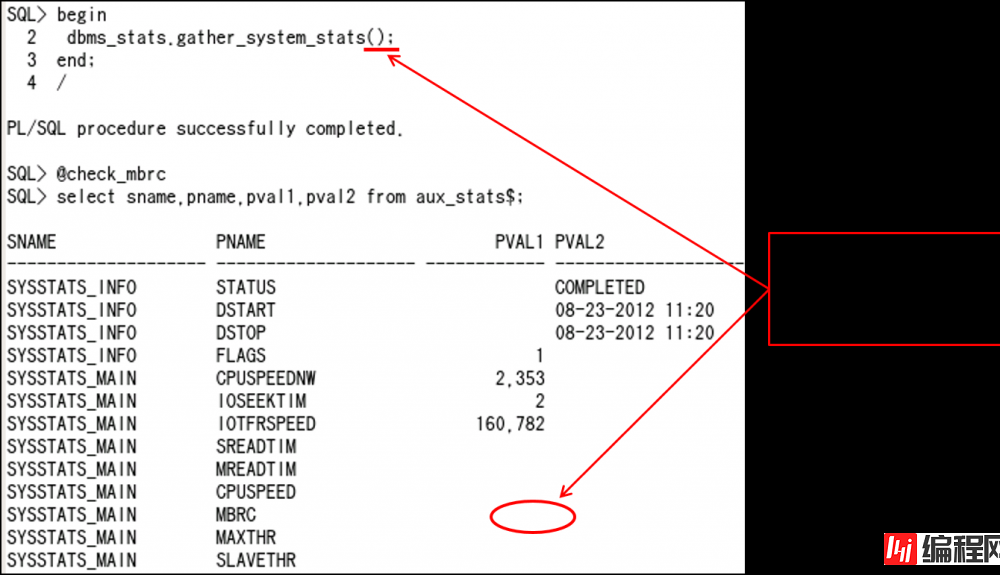
Multi Block Read Count (MBRC)是什么?
一次OS 读入中,读入的db block数
–Exadata中,1次OS读入量为1MB
因此8KB db block的情况下会读入128 block
=> 但是,Optimizer使用MBRC = 8
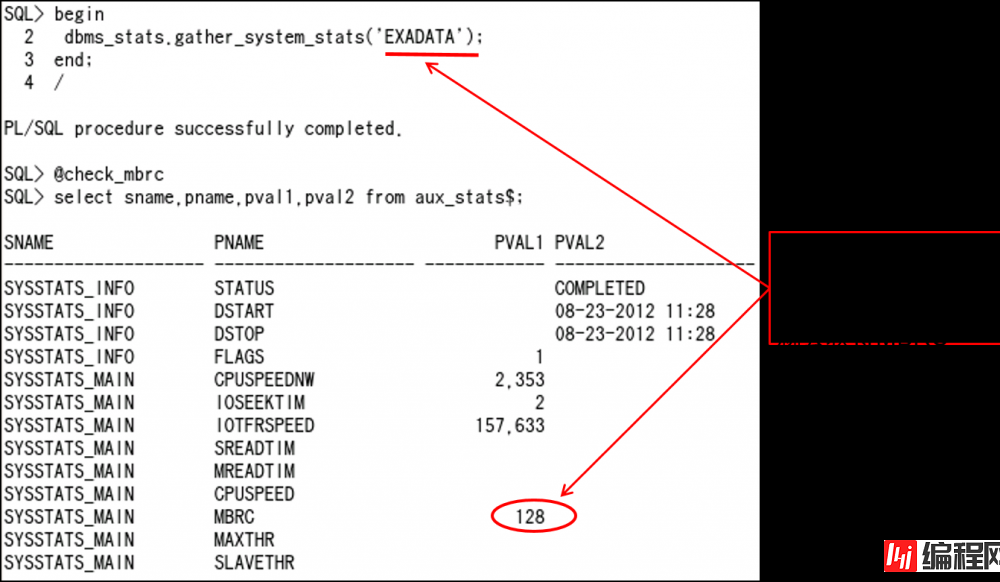
GATHER_SYSTEM_STATS(系统统计)中、制成了用于Exadata的新模式
begin
dbms_stats.gather_system_stats('EXADATA');
end;
/Exadata指定时,设定MBRC值。
–DB_FILE_MULTI_BLOCK_READ_COUNT的値(默认値 : 1MB / blocksize)
由此我们发现Exadata的Full Scan成本比以前小多了
需要Patch for Bug 10248538
(Exadata中,包含11.2.0.2.18 or 11.2.0.3.8 以上)
查询:Create table <tname> as select * from test_tbl where seqid < 10,000
※元表:60,000,000行。缩小1/6,000
Default的plan在FULL SCAN时在index range scan上被变更了
Smart Scan不适用的案例
详细内容请参考User’s Guide 「7 Monitoring and Tuning Oracle Exadata Storage Server Software」
The CELL_OFFLOAD_PROCESSING parameter is set to FALSE.
The table or partition being scanned is small.
The optimizer does not use direct path read.
A scan is perfORMed on a clustered table.
A scan is performed on an index-organized table.
A fast full scan is performed on compressed indexes.
A fast full scan is performed on reverse key indexes.
The table has row dependencies enabled or the rowscn is being fetched.
The optimizer wants the scan to return rows in ROWID order.
The optimizer does not use direct path read.
The command is CREATE INDEX using nosort.
A LOB or LONG column is being selected or queried.
A SELECT … VERSIONS query is done on a table.
A query that has more than 255 columns referenced and heap table is uncompressed, or Basic or OLTP compressed. However such queries on Exadata Hybrid Columnar Compression-compressed tables are offloaded.
The tablespace is encrypted, and the CELL_OFFLOAD_DECRYPTION parameter is set to FALSE. In order for Exadata Cell to perform decryption, Oracle Database needs to send the decryption key to Exadata Cell. If there are security concerns about keys being shipped across the network to Exadata Cell, then disable the decryption feature.
The tablespace is not completely stored on Exadata Cell.
The predicate evaluation is on a virtual column.
对加密数据进行Smart Scan
功能
–TDE表区域加密化、TDE列加密化数据都可以进行SmartScan
–可以灵活使用Xeon 5600 / E7 处理器的AES-NI功能
AES-NI仅在表区域加密时有效
Exadata的话,可以与X2-2 / X2-8的DB Server / Storage Server同时使用
优点
–通过在存储中卸载多个处理的过载可以大幅提高DB Server的CPU效率
–通过加密化数据进行filtering,可以减少向DB Server发送的 数据量
HCC压縮时的操作
通过HCC执行压縮的时机
–在直接路径加载时执行压缩
Parallel DML, INSERT , Direct Path ,sql*LDR
数据压縮时的操作
–数据在每个列中以列単位执行压缩
因为在压缩后执行写入,所以可以减少磁盘I/O
–压縮处理通过服务器自身来执行进程

对HCC压縮数据执行查询时的操作
非Smart Scan的情况
–以压缩状态读入到缓冲区高速缓存中,在PGA中展开
–全表扫描的情况
读入所有的Compression Unit,对搜索所需要的列进行展开
Smart Scan的情况
–在Exadata Storage Server上执行解压,应用Smart Scan。
※列filtering的情况中,仅将对应的列以压缩状态传送到Database Server中。
–Database Server的解压处理中减少CPU过载
–压縮数据通过行filtering,可以减少向DB Server发送的数据量

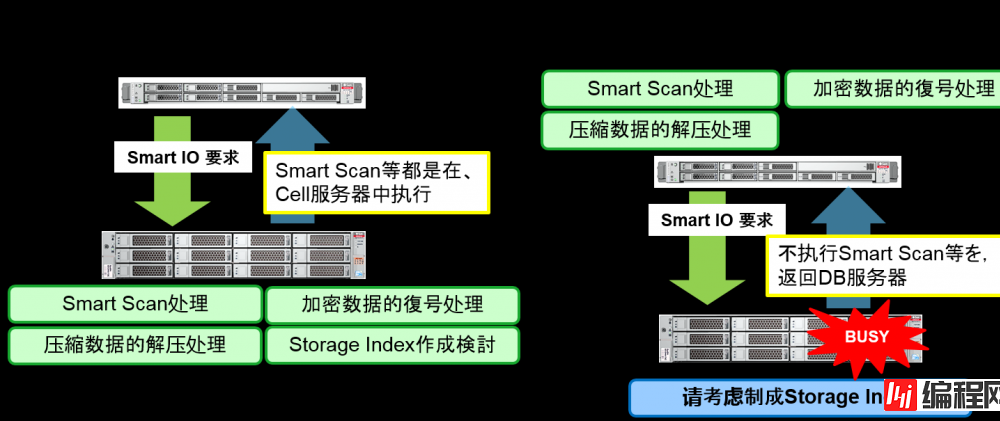
Smart I/O 【Optimized Smart Scan】
11.2.2.3开始的新功能
Smart Scan时,通过排除Cell的CPU瓶颈,提高性能
监视Cell的CPU使用率,CPU使用率超过阀值的话,就会作为通过cell执行的处理的一部分在DB中执行
用户以及管理者的不需要设置就可以自动执行的功能
通过Optimized Smart Scan,如果不执行Smart Scan的话,在Cell中使用CPU的下列处理都会被跳过
–Smart Scan
–压縮数据的解压处理
–加密数据的解密处理
–判断是否制成Storage Index等
Optimized Smart Scan的活用例
所有Smart IO都是Optimized Smart Scan的对象。以Cell/DB CPU使用率为基准进行判断
Optimized Smart Scan的特征
通过各Cell进行Optimized Smart Scan判断时,是以1MB数据単位来执行的,并不是SQL単位以及DB単位
cellsrv进程每0.2秒都会获得Cell CPU使用率
如果接受Smart I/O 需求的话,以现在的Cell/DB的CPU使用率为基础,就可以判断是否需要执行,不执行Smart Scan等直接返回到DB中的处理
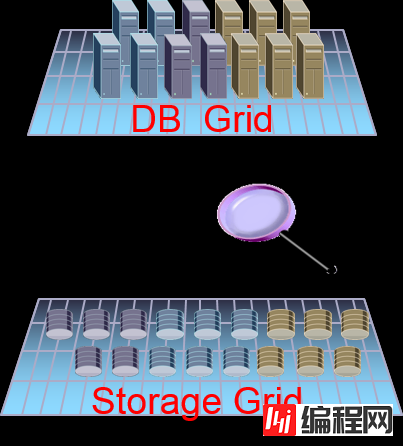
DB与Exadata Storage Grid的統合
Database Server中的cluster membership在Cell的监视中也得到了扩展。
认识到Cell 在DB层发生的变化
–Cluster member发生变化后不执行STALE I/O
–可以不破坏数据高效变更结构
Cell 的故障会报告给数据库
数据库可以查看存储的操作,存储也可以查看数据库的操作
这是仅限Exadata存储中的合作功能
Cell 执行监视、报告I/O统计状况等
处理ASM硬件故障
ASM的镜像
–在Allocation Unit水平上执行镜像。
–使用Exadata时,会自动对每个cell制成故障group(可能同时发生故障的磁盘组合)primary与镜像的AU会分别储存在各自的故障group中。
–磁盘以及Cell故障从数据库中穿透性地执行
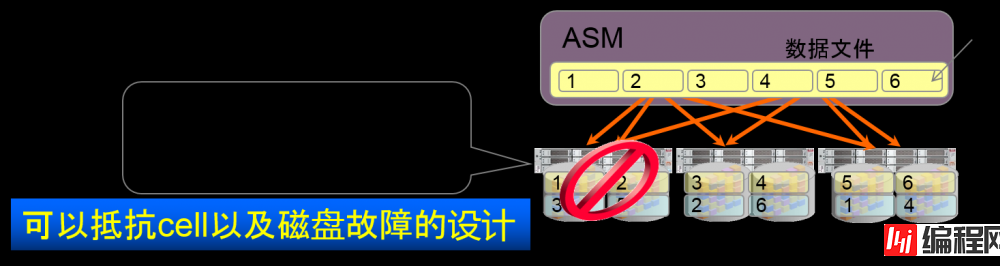
Brown out的保护
*Brown out=暂时中止等
cell以及磁盘无应答时,ASM会暂时将I/O冻结(offline化)
–Read I/O会重放被镜像化的数据库。
–追踪失败的Write I/O。
磁盘可以再次访问时,offline的Write I/O会被再次执行。
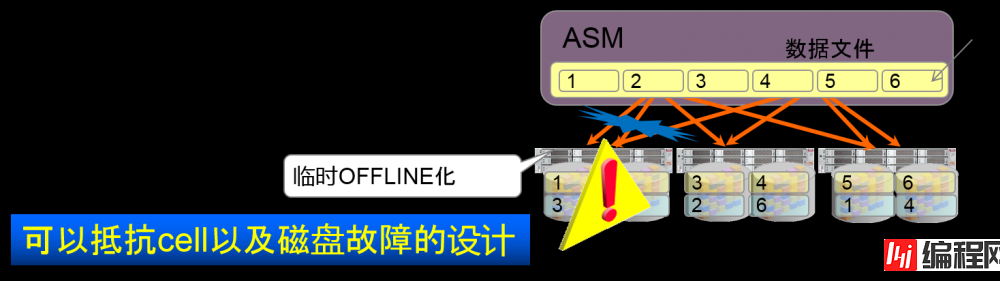
快速镜像化槽(sink)
高速修复临时故障
–例)cell crash以及临时hang
也可以处理计划中止
–例)更新cell软件
Cell以及CELLSRV故障时的操作
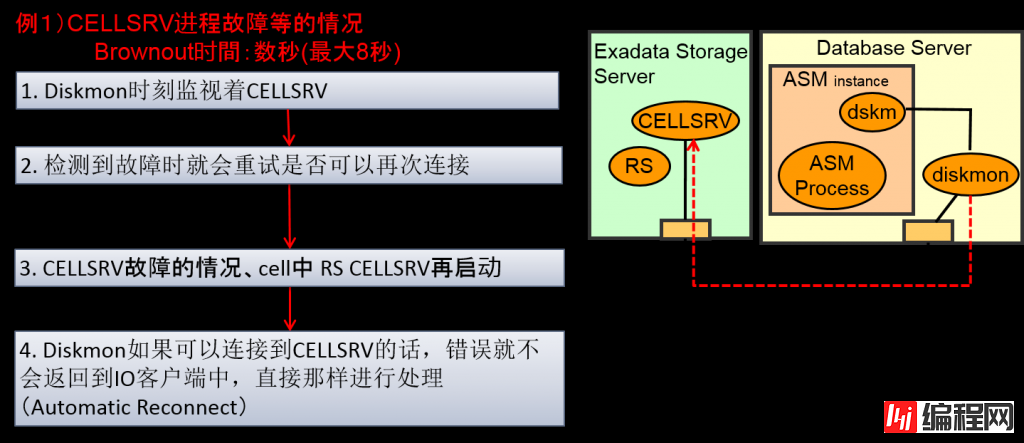
CELLSRV 进程故障
–临时的,时间较短的故障的案例较多。
–CELLSRV 进程的故障时会即时检测到RS进程,就会重启CELLSRV。这时,IO客户端就不会返回IO故障报告,这种案例可以通过自动重新连接继续进行IO处理来处理(Automatic Reconnect)
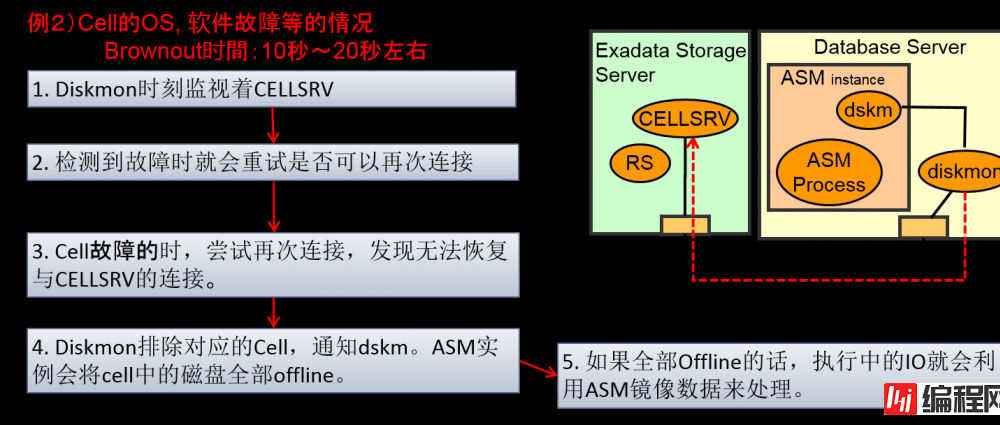
Cell故障
–Cell终止时(OS,设备终止)到重启为止会花费较多时间。
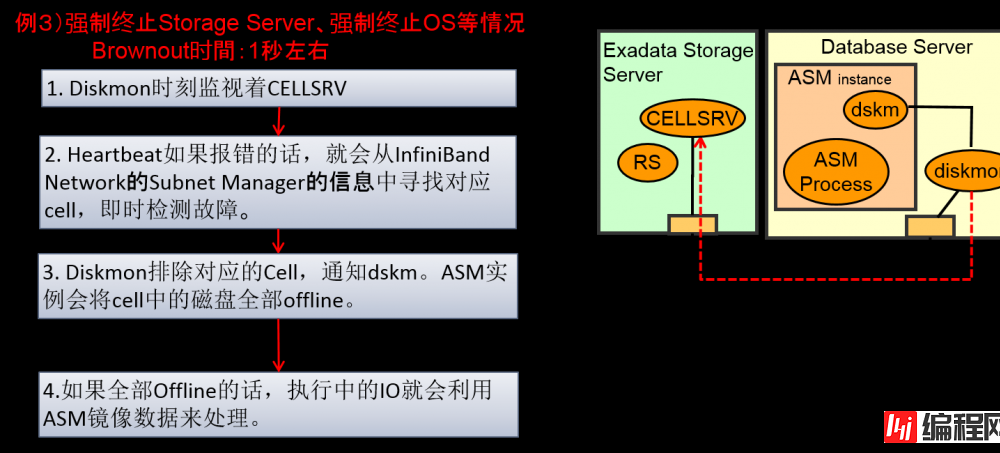
–DB Server中的Diskmon进程会监视Cell,检测到cell故障时,就会舍弃对应的cell,对此,ASM就会在对应的cell的磁盘中被舍弃。DB一起ASM的IO会重放其他的cell中的ASM的镜像。
–观察IO客户端的话,CELLSRV性能就会下降,就会变成待机状态,直到diskmon吧故障cell排除为止,都会使得那个cell上的IO进行hang
每个版本从发现故障到解决故障的时间都在缩短。
Cell以及CELLSRV故障时的Brownout时间
Oracle Exadata Database Machine Unplanned Outage Matrix (Doc ID 1471529.1)
–记载着每个版本各个部件故障时,对应用的影响时间
–最新版的Outage Matrix如下述Note所示
–Oracle Exadata Database Machine Unplanned Outage Matrix 11203 BP7 – 11.2.3.1.1 (Doc ID 1471527.1)
检测Cell以及CELLSRV故障的检测 (11.2.0.3 + 11.2.3.1.1)
例1)CELLSRV进程故障等的情况
Brownout时間:数秒(最大8秒)
停止Cell上的软件stack
–因为CELLSRV, MS, RS全部终止了,进程无法重启
[root@jigenc01 ~]# date; service celld stop; date;
Mon Aug 6 19:16:53 JST 2012
Stopping the RS, CELLSRV, and MS services...
The SHUTDOWN of services was successful.
Mon Aug 6 19:17:04 JST 2012
[root@jigenc01 ~]#查看Diskmon的日志
2012-08-06 19:16:52.281: [ DISKMON][16663:1105365312] dskm_process_msg5: received msg type KGZM_PING (0x0011)
2012-08-06 19:16:55.284: [ DISKMON][16663:1105365312] dskm_process_msg5: received msg type KGZM_PING (0x0011)
2012-08-06 19:16:58.285: [ DISKMON][16663:1105365312] dskm_process_msg5: received msg type KGZM_PING (0x0011)
2012-08-06 19:16:58.463: [ DISKMON][16663:1096874304] dskm_tcpmon_thrd_main: Detected a cell death o/192.168.20.51. Posting hbb thread.
2012-08-06 19:16:58.463: [ DISKMON][16663:1111669056] dskm_hb_thrd_main7: posted out of skgxpwait()
2012-08-06 19:16:58.463: [ DISKMON][16663:1111669056] dskm_hb_thrd_main7.1: posted by TCPmon thread
2012-08-06 19:16:58.463: [ DISKMON][16663:1111669056] INFO: Entering Cell Reconnect: rscnam: o/192.168.20.51 rsc: 0x10b81040 state: UNREACHABLE reconn_attempts: 0 last_reconn_ts: 1344248182
2012-08-06 19:16:58.463: [ DISKMON][16663:1111669056] dskm_node_guids_are_offline: query SM done. retcode = 56891(REACHABLE)
2012-08-06 19:16:58.464: [ DISKMON][16663:1111669056] dskm_oss_get_net_info3: oss_get_net_info for device o/192.168.20.51 failed with error 5 (nip = 1)
2012-08-06 19:16:58.464: [ DISKMON][16663:1111669056] dskm_ant_rsc_monitor_start1: dskm_oss_get_net_info failed with error 56841
2012-08-06 19:16:58.464: [ DISKMON][16663:1111669056] dskm_ant_rsc_monitor_start: rscnam: o/192.168.20.51 rsc: 0x10b81040 state: UNREACHABLE reconn_attempts: 1 last_reconn_ts: 1344248218
2012-08-06 19:17:00.466: [ DISKMON][16663:1111669056] dskm_node_guids_are_offline: query SM done. retcode = 56891(REACHABLE)
2012-08-06 19:17:00.467: [ DISKMON][16663:1111669056] dskm_oss_get_net_info3: oss_get_net_info for device o/192.168.20.51 failed with error 5 (nip = 1)
2012-08-06 19:17:00.467: [ DISKMON][16663:1111669056] dskm_ant_rsc_monitor_start1: dskm_oss_get_net_info failed with error 56841
2012-08-06 19:17:00.467: [ DISKMON][16663:1111669056] dskm_ant_rsc_monitor_start: rscnam: o/192.168.20.51 rsc: 0x10b81040 state: UNREACHABLE reconn_attempts: 2 last_reconn_ts: 1344248220
2012-08-06 19:17:10.302: [ DISKMON][16663:1105365312] dskm_process_msg5: received msg type KGZM_PING (0x0011)
2012-08-06 19:17:10.478: [ DISKMON][16663:1111669056] dskm_node_guids_are_offline: query SM done. retcode = 56891(REACHABLE)
2012-08-06 19:17:10.479: [ DISKMON][16663:1111669056] dskm_oss_get_net_info3: oss_get_net_info for device o/192.168.20.51 failed with error 5 (nip = 1)
2012-08-06 19:17:10.479: [ DISKMON][16663:1111669056] dskm_ant_rsc_monitor_start1: dskm_oss_get_net_info failed with error 56841
2012-08-06 19:17:10.479: [ DISKMON][16663:1111669056] dskm_ant_rsc_monitor_start: rscnam: o/192.168.20.51 rsc: 0x10b81040 state: UNREACHABLE reconn_attempts: 7 last_reconn_ts: 1344248230
2012-08-06 19:17:10.479: [ DISKMON][16663:1111669056] dskm_queue_tcpmon_request: posting
2012-08-06 19:17:10.479: [ DISKMON][16663:1111669056] dskm_post_tcpmon_thrd
2012-08-06 19:17:10.480: [ DISKMON][16663:1096874304] dskm_tcpmon_thrd_main: posted, poll returned with retcode = 45
2012-08-06 19:17:10.480: [ DISKMON][16663:1096874304] dskm_tcpmon_thrd_main: Got a request with type 2, cellname = o/192.168.20.51, cellname length 16, cell incarnation = 0
2012-08-06 19:17:10.480: [ DISKMON][16663:1096874304] dskm_tcpmon_thrd_main: Cant find the corresponding monitor request in progress, unmonitor request will be ignored
Reconnect 失败8次,进入Cell的evict的进程。
之后diskmon通知dskm,cell down。
Mon Aug 06 19:17:10 2012
Exadata cell: o/192.168.20.51 is no longer accessible. I/O errors to disks on this might get suppressed
Mon Aug 06 19:17:10 2012
NOTE: process _user14223_+asm1 (14223) initiating offline of disk 74.3916043773 (DATA_H_CD_05_JIGENC01) with mask 0x7e[0x7f] in group 1
WARNING: Disk 74 (DATA_H_CD_05_JIGENC01) in group 1 in mode 0x7f is now being taken offline on ASM inst 1
WARNING: Disk 72 (DATA_H_CD_04_JIGENC01) in group 1 in mode 0x7f is now being taken offline on ASM inst 1
WARNING: Disk 73 (DATA_H_CD_02_JIGENC01) in group 1 in mode 0x7f is now being taken offline on ASM inst 1
WARNING: Disk 75 (DATA_H_CD_01_JIGENC01) in group 1 in mode 0x7f is now being taken offline on ASM inst 1
<中略。Cell上的全Griddisk分>
NOTE: initiating PST update: grp = 1, dsk = 79/0xe96a1602, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 1, dsk = 80/0xe96a1603, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 1, dsk = 81/0xe96a1604, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 1, dsk = 82/0xe96a1605, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 1, dsk = 83/0xe96a1606, mask = 0x6a, op = clear
Mon Aug 06 19:17:10 2012
NOTE: process _user26170_+asm1 (26170) initiating offline of disk 66.3916043034 (DBFS_DG_CD_11_JIGENC01) with mask 0x7e[0x7f] in group 4
WARNING: Disk 66 (DBFS_DG_CD_11_JIGENC01) in group 4 in mode 0x7f is now being taken offline on ASM inst 1
WARNING: Disk 60 (DBFS_DG_CD_08_JIGENC01) in group 4 in mode 0x7f is now being taken offline on ASM inst 1
WARNING: Disk 61 (DBFS_DG_CD_07_JIGENC01) in group 4 in mode 0x7f is now being taken offline on ASM inst 1
马上对对应的cell中的disk进行offline2-1. 切断TCP connection,即时检测Cell death
Proactive disk drop (11.2.1.3.1~)
一般的ASM中,发生一个磁盘故障时,ASM会等待超时,然后自动删除对应磁盘。删除完成之前,如果发生其他的磁盘故障的话,就可能变成二重故障,丢失数据。
11.2.1.3.1以后的版本,通过Exadata Storage Server预测到物理磁盘的故障以及其他故障时
–在ASM超时之前,就会在pro-active从ASM磁盘group中删除磁盘
–ASM会将故障磁盘上的数据重新移动到其他磁盘上
可以及时回复ASM磁盘group的冗长性,减少丢失数据的危险
即使是检测到Flash module故障的情况,也会从Smart Flash Cache中删除对应的Flash module,或者从ASM group中,删除对应的Flash Grid Disk。
自动修复的进程
Cell中
–MS进程
cell的管理进程。
检测到磁盘故障的话就会重新生成警报,如果检测到插入了新的磁盘的话,就会执行重新制成LUN以及celldisk,griddisk所必需的操作。
ASM实例内
–XDMG进程(Exadata Automation Manager)
监视cell的状态变更,如果需要更换磁盘的话,就执行对应的task。监视无法访问的磁盘以及cell。可以访问时,就执行检测,开始ONLINE处理。
–XDWK进程(Exadata Automation Worker)
从XDMG进程中自动执行对应的task。XDWK进程会在执行ONLINE、DROP、ADD等非同步处理时启动。不是活跃状态的话持续五分钟就会终止进程。
操作Proactive Disk Drop的条件
Proactive Disk Drop 需要通过以下条件进行操作
物理故障(Failed) 时
–HDD
–Flash disk
预测故障(Predictive Failure) 状态
–HDD
–Flash disk
性能极端缓慢的状态(Poor Performance)
–Flash disk
注意:仅仅通过物理性地拔出HDD ,是无法查看 Failed 的状态的
这种情况的对策一如既往,(将ASM 磁盘offline,等待disk_repair_time
超时,删除。重新插入磁盘的话,就会自动重新制成Griddisk,Celldisk。
自动执行ASM 磁盘的offline或者 Add。
到此,关于“Oracle Exadata存储服务器原理是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: Oracle Exadata存储服务器原理是什么
本文链接: https://lsjlt.com/news/64254.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0