MHA角色部署MHA 服务有两种角色,MHA Manager(管理节点)和MHA node(数据节点): MHA Manager:通常单独部署在一台独立的机器上或者直接部署在其中一台slave上(不建议后者),管理多个master/slave集群,每个master/slave集群称作一个application;其作用有二: (1)master自动切换及故障转移命令运行 (2)其他的帮助脚本运行:手动切换master;master/slave状态检测 MHA node:运行在每台mysql服务器上(master/slave/manager),它通过监控具备解析和清理logs功能的脚本来加快故障转移。其作用有: (1)复制主节点的binlog数据 (2)对比从节点的中继日志文件 (3)无需停止从节点的sql线程,定时删除中继日志 目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。 我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。 官方介绍:
https://code.Google.com/p/mysql-master-ha/ 下图展示了如何通过MHA Manager管理多组主从复制。可以将MHA工作原理总结为如下: 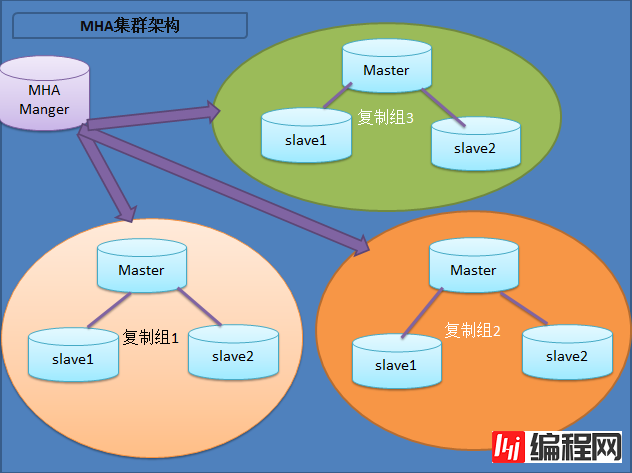
(1)从宕机崩溃的master保存二进制日志事件(binlog events); (2)识别含有最新更新的slave; (3)应用差异的中继日志(relay log)到其他的slave; (4)应用从master保存的二进制日志事件(binlog events); (5)提升一个slave为新的master; (6)使其他的slave连接新的master进行复制; MHA组件(1)、 Manager工具: – masterha_check_ssh : 检查MHA的SSH配置。 – masterha_check_repl : 检查MySQL复制。 – masterha_manager : 启动MHA。 – masterha_check_status : 检测当前MHA运行状态。 – masterha_master_monitor : 监测master是否宕机。 – masterha_master_switch : 控制故障转移(自动或手动)。 – masterha_conf_host : 添加或删除配置的server信息。 (2)、 Node工具(这些工具通常由MHAManager的脚本触发,无需人手操作)。 – save_binary_logs : 保存和复制master的二进制日志。 – apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。 – filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。 – purge_relay_logs : 清除中继日志(不会阻塞SQL线程)。 (3)、自定义扩展: -secondary_check_script:通过多条网络路由检测master的可用性; -master_ip_failover_script:更新application使用的masterip; (需要修改) -shutdown_script:强制关闭master节点; -report_script:发送报告; -init_conf_load_script:加载初始配置参数; -master_ip_online_change:更新master节点ip地址;(需要修改) MHA环境准备OS:Centos 6.8 MySQL :5.7.18 MHA 软件包: MHA 0.57 角色 ip地址 主机名 server_id "类型 "
Master 10.180.2.163 MHA-M1 13306 "写入 "
S1 10.180.2.164 MHA-S1 23306 "读 " (其实可以一起部署监控,一组MHA 可以多个监控节点)
S2 10.180.2.165 MHA-S2 33306 "读 ","监控复制组 " (监控一般不能部署到master 节点,防止Master 宕机不能切换) 安装MHA Node 包(1)在所有节点安装MHA node所需的perl模块(DBD:mysql),并下载MHA 软件包 ? 12yum
install
perl-DBD-MySQL -y (可能需要epel源)Https://mega.nz/#F!G4oRjarB!SWzFS59bUv9VrKwdAeIGVw (MHA0.57) (2)在所有的节点安装mha node(包括Manager 节点): tar xf mha4mysql-node-0.57.tar.gz
cd mha4mysql-node-0.57perl Makefile.PLmake && make install
安装完成将产生文件如下:
[root@MHA-S1 bin]# ll
total 48-r-xr-xr-x 1 root root 16381 Aug 7 14:06 apply_diff_relay_logs-r-xr-xr-x 1 root root 4807 Aug 7 14:06 filter_mysqlbinlog
lrwxrwxrwx 1 root root 26 Aug 8 17:10 mysql -> /usr/local/mysql/bin/mysql
lrwxrwxrwx 1 root root 32 Aug 8 17:09 mysqlbinlog -> /usr/local/mysql/bin/mysqlbinlog-r-xr-xr-x 1 root root 8261 Aug 7 14:06 purge_relay_logs-rwxr-xr-x 1 root root 314 Aug 8 16:21 purge_relay.sh-r-xr-xr-x 1 root root 7525 Aug 7 14:06 save_binary_logs
[root@MHA-S1 bin]# pwd/usr/local/bin
增加系统环境变量: echo "export PATH=\$PATH:/usr/local/bin" >> /etc/profile
source ~/.bash_profile
安装MHA Manager 包tar xf mha4mysql-node-0.57.tar.gz
cd mha4mysql-node-0.57perl Makefile.PLmake && make install
安装完成后会在/usr/local/bin目录下面生成以下脚本文件
[root@MHA-S2 bin]# pwd/usr/local/bin
[root@MHA-S2 bin]# ll
total 140-r-xr-xr-x 1 root root 16381 Aug 7 14:07 apply_diff_relay_logs-r-xr-xr-x 1 root root 4807 Aug 7 14:07 filter_mysqlbinlog-rwxr-xr-x 1 root root 166 Aug 9 17:18 manager.sh-r-xr-xr-x 1 root root 1995 Aug 7 17:28 masterha_check_repl-r-xr-xr-x 1 root root 1779 Aug 7 17:28 masterha_check_ssh-r-xr-xr-x 1 root root 1865 Aug 7 17:28 masterha_check_status-r-xr-xr-x 1 root root 3201 Aug 7 17:28 masterha_conf_host-r-xr-xr-x 1 root root 2517 Aug 7 17:28 masterha_manager-r-xr-xr-x 1 root root 2165 Aug 7 17:28 masterha_master_monitor-r-xr-xr-x 1 root root 2373 Aug 7 17:28 masterha_master_switch-r-xr-xr-x 1 root root 5171 Aug 7 17:28 masterha_secondary_check-r-xr-xr-x 1 root root 1739 Aug 7 17:28 masterha_stop-rwxr-xr-x 1 root root 2169 Aug 9 10:49 master_ip_failover-rwxr-xr-x 1 root root 3648 Aug 7 17:30 master_ip_failover.old-rwxr-xr-x 1 root root 10369 Aug 12 21:33 master_ip_online_change-rwxr-xr-x 1 root root 9870 Aug 7 17:30 master_ip_online_change.old
lrwxrwxrwx 1 root root 26 Aug 8 17:10 mysql -> /usr/local/mysql/bin/mysql
lrwxrwxrwx 1 root root 32 Aug 8 17:09 mysqlbinlog -> /usr/local/mysql/bin/mysqlbinlog-rw------- 1 root root 0 Aug 12 20:04 nohup.out-rwxr-xr-x 1 root root 11867 Aug 7 17:30 power_manager-r-xr-xr-x 1 root root 8261 Aug 7 14:07 purge_relay_logs-rwxr-xr-x 1 root root 314 Aug 8 16:20 purge_relay.sh-r-xr-xr-x 1 root root 7525 Aug 7 14:07 save_binary_logs-rwxr-xr-x 1 root root 1360 Aug 7 17:30 send_report
复制相关脚本到/usr/local/bin目录(软件包解压缩后就有了,不是必须,因为这些脚本不完整,需要自己修改,这是软件开发着留给我们自己发挥的,如果开启下面的任何一个脚本对应的参数,而对应这里的脚本又没有修改,则会抛错,自己被坑的很惨)
[root@MHA-S2 scripts]# ll
total 32
-rwxr-xr-x 1 root root 3443 Jan 8 2012 master_ip_failover #自动切换时vip管理的脚本,不是必须,如果我们使用keepalived的,我们可以自己编写脚本完成对vip的管理,比如监控mysql,如果mysql异常,我们停止keepalived就行,这样vip就会自动漂移
-rwxr-xr-x 1 root root 9186 Jan 8 2012 master_ip_online_change #在线切换时vip的管理,不是必须,同样可以可以自行编写简单的shell完成
-rwxr-xr-x 1 root root 11867 Jan 8 2012 power_manager #故障发生后关闭主机的脚本,不是必须
-rwxr-xr-x 1 root root 1360 Jan 8 2012 send_report #因故障切换后发送报警的脚本,不是必须,可自行编写简单的shell完成。
[root@MHA-S2 scripts]# cp * /usr/local/bin/
配置SSH登录无密码验证 ssh-keygenssh-copy-id root@xxx (XXX 请包括自己,要不然后面check-ssh那步要杯具的)
搭建主从复制环境 详解之前双主复制环境搭建文档 保证两台Slave都搭建成功 Slave_IO_Running: Yes
Slave_SQL_Running: Yes
两台slave服务器设置read_only(从库对外提供读服务,只所以没有写进配置文件,是因为随时slave会提升为master)
root@localhost:mysql3306.sock [(none)]>set global read_only=1
创建监控用户(在master上执行) grant all privileges on *.* to root@'%' identified by '123456';
flush privileges;
至此,复制搭建完毕,后面配置MHA MHA环境配置 (1) 创建MHA 工作目录 mkdir -p /etc/mha
修改app1.cnf配置文件,修改后的文件内容如下: 
[root@MHA-S2 ~]# /etc/mha/=/var/log/masterha/app1/=/var/log/masterha/=/data/mysql//=/usr/local/bin/=/usr/local/bin/===/===/usr/local/bin/=/usr/local/bin/masterha_secondary_check -s MHA-S1 -s MHA-===MHA-==//设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=//默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,
这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
=MHA-S1
port=
=MHA-=
(2)设置relay log的清除方式(在每个slave节点上): ? 1'set global relay_log_purge=0' 注意: MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式) MHA节点中包含了pure_relay_logs命令工具,它可以为中继日志创建硬链接,执行SET GLOBAL relay_log_purge=1,等待几秒钟以便SQL线程切换到新的中继日志,再执行SET GLOBAL relay_log_purge=0。 pure_relay_logs脚本参数如下所示: --user mysql 用户名--passWord mysql 密码--port 端口号--workdir 指定创建relay log的硬链接的位置,默认是/var/tmp,由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继日志文件被删除--disable_relay_log_purge 默认情况下,如果relay_log_purge=1,脚本会什么都不清理,自动退出,通过设定这个参数,当relay_log_purge=1的情况下会将relay_log_purge设置为0。清理relay log之后,最后将参数设置为OFF。
(3)设置定期清理relay脚本(例如每天一次,所有服务器)
[root@MHA-S2 bin]# purge_relay.!/bin/====== [ ! -
$log_dir ---user=$user --password=$ --disable_relay_log_purge --port=$port --workdir=$work_dir >> $log_dir/purge_relay_logs.log >&
添加到crontab
[root@MHA-S2 bin]# crontab -l0 4 * * * /bin/bash /root/purge_relay_log.sh
可以手工执行以下是否会报错 检查SSH配置
[root@MHA-S2 bin]# masterha_check_ssh --conf=/etc/mha/app1.cnf
Mon Aug 14 18:07:02 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon Aug 14 18:07:02 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Mon Aug 14 18:07:02 2017 - [info] Reading server configuration from /etc/mha/app1.cnf..
Mon Aug 14 18:07:02 2017 - [info] Starting SSH connection tests..
Mon Aug 14 18:07:03 2017 - [debug]
Mon Aug 14 18:07:02 2017 - [debug] Connecting via SSH from root@MHA-M1(10.180.2.163:22) to root@MHA-S1(10.180.2.164:22)..
Mon Aug 14 18:07:02 2017 - [debug] ok.
Mon Aug 14 18:07:02 2017 - [debug] Connecting via SSH from root@MHA-M1(10.180.2.163:22) to root@MHA-S2(10.180.2.165:22)..
Mon Aug 14 18:07:03 2017 - [debug] ok.
Mon Aug 14 18:07:03 2017 - [debug]
Mon Aug 14 18:07:03 2017 - [debug] Connecting via SSH from root@MHA-S1(10.180.2.164:22) to root@MHA-M1(10.180.2.163:22)..
Mon Aug 14 18:07:03 2017 - [debug] ok.
Mon Aug 14 18:07:03 2017 - [debug] Connecting via SSH from root@MHA-S1(10.180.2.164:22) to root@MHA-S2(10.180.2.165:22)..
Mon Aug 14 18:07:03 2017 - [debug] ok.
Mon Aug 14 18:07:04 2017 - [debug]
Mon Aug 14 18:07:03 2017 - [debug] Connecting via SSH from root@MHA-S2(10.180.2.165:22) to root@MHA-M1(10.180.2.163:22)..
Mon Aug 14 18:07:03 2017 - [debug] ok.
Mon Aug 14 18:07:04 2017 - [debug] Connecting via SSH from root@MHA-S2(10.180.2.165:22) to root@MHA-S1(10.180.2.164:22)..
Mon Aug 14 18:07:04 2017 - [debug] ok.
Mon Aug 14 18:07:04 2017 - [info] All SSH connection tests passed successfully.
检查整个复制环境状况 发现有报错,
Tue Aug 8 17:46:31 2017 - [info] Checking master_ip_failover_script status:
Tue Aug 8 17:46:31 2017 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=MHA-M1 --orig_master_ip=10.180.2.163 --orig_master_port=3306 Bareword "FIXME_xxx" not allowed while "strict subs" in use at /usr/local/bin/master_ip_failover line 93.
Execution of /usr/local/bin/master_ip_failover aborted due to compilation errors.
Tue Aug 8 17:46:31 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln229] Failed to get master_ip_failover_script status with return code 255:0.Tue Aug 8 17:46:31 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/local/bin/masterha_check_repl line 48Tue Aug 8 17:46:31 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
Tue Aug 8 17:46:31 2017 - [info] Got exit code 1 (Not master dead).
原来Failover两种方式:一种是虚拟IP地址,一种是全局配置文件。MHA并没有限定使用哪一种方式,而是让用户自己选择,虚拟IP地址的方式会牵扯到其它的软件,比如keepalive软件,而且还要修改脚本master_ip_failover。这里先把app1.cnf 里面 master_ip_failover_script= /usr/local/bin/master_ip_failover这个选项屏蔽才可以通过。 #master_ip_failover_script= /usr/local/bin/master_ip_failover
Tue Aug 8 17:49:40 2017 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
检查MHA Manager的状态 [root@MHA-S2 mha]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
手动启动 [root@MHA-S2 mha]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &[1] 16774[root@MHA-S2 mha]# ps -ef|grep masterha
root 16774 15297 4 17:52 pts/3 00:00:00 perl /usr/local/bin/masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
[root@MHA-S2 mha]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:16774) is running(0:PING_OK), master:MHA-M1
--remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。(如果发生异常切换之后修复了旧的master,要加进去新的MHA 的话,必须记得app1.cnf回补server1的信息) --manger_log 日志存放位置 --ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面我设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。 检查启动日志
[root@MHA-S2 app1]# vi manager.log
Tue Aug 8 17:52:37 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Aug 8 17:52:37 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Tue Aug 8 17:52:37 2017 - [info] Reading server configuration from /etc/mha/app1.cnf..
Tue Aug 8 17:52:37 2017 - [info] MHA::MasterMonitor version 0.57.
Tue Aug 8 17:52:38 2017 - [info] GTID failover mode = 1Tue Aug 8 17:52:38 2017 - [info] Dead Servers:
Tue Aug 8 17:52:38 2017 - [info] Alive Servers:
Tue Aug 8 17:52:38 2017 - [info] MHA-M1(10.180.2.163:3306)
Tue Aug 8 17:52:38 2017 - [info] MHA-S1(10.180.2.164:3306)
Tue Aug 8 17:52:38 2017 - [info] MHA-S2(10.180.2.165:3306)
Tue Aug 8 17:52:38 2017 - [info] Alive Slaves:
Tue Aug 8 17:52:38 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Tue Aug 8 17:52:38 2017 - [info] GTID ON
Tue Aug 8 17:52:38 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Tue Aug 8 17:52:38 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Aug 8 17:52:38 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Tue Aug 8 17:52:38 2017 - [info] GTID ON
Tue Aug 8 17:52:38 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Tue Aug 8 17:52:38 2017 - [info] Current Alive Master: MHA-M1(10.180.2.163:3306)
Tue Aug 8 17:52:38 2017 - [info] Checking slave configurations..
Tue Aug 8 17:52:38 2017 - [info] Checking replication filtering settings..
Tue Aug 8 17:52:38 2017 - [info] binlog_do_db= , binlog_ignore_db=Tue Aug 8 17:52:38 2017 - [info] Replication filtering check ok.
Tue Aug 8 17:52:38 2017 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Tue Aug 8 17:52:38 2017 - [info] Checking SSH publickey authentication settings on the current master..
Tue Aug 8 17:52:38 2017 - [info] HealthCheck: SSH to MHA-M1 is reachable.
Tue Aug 8 17:52:38 2017 - [info]
MHA-M1(10.180.2.163:3306) (current master) +--MHA-S1(10.180.2.164:3306) +--MHA-S2(10.180.2.165:3306)
Tue Aug 8 17:52:38 2017 - [warning] master_ip_failover_script is not defined.
Tue Aug 8 17:52:38 2017 - [warning] shutdown_script is not defined.
Tue Aug 8 17:52:38 2017 - [info] Set master ping interval 1 seconds.
Tue Aug 8 17:52:38 2017 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s MHA-S1 -s MHA-S2
Tue Aug 8 17:52:38 2017 - [info] Starting ping health check on MHA-M1(10.180.2.163:3306)..Tue Aug 8 17:52:38 2017 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
配置VIP vip配置可以采用两种方式,一种通过keepalived的方式管理虚拟ip的浮动;另外一种通过脚本方式启动虚拟ip的方式(即不需要keepalived或者heartbeat类似的软件)。 这里仅演示使用脚本管理VIP 的方式, 修改master_ip_failover 脚本,使用脚本管理VIP [root@MHA-M1 ~]# /sbin/ifconfig eth2:1 10.180.2.168/19
脚本:
[root@MHA-S2 bin]# cat master_ip_failover
#!/usr/bin/env perluse strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '10.180.2.168/19';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth2:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth2:$key down";
GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip();
$exit_code = 0;
}; if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip();
$exit_code = 0;
}; if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
} else { &usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;}
sub usage {
print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
在app1.cnf 文件中取消刚刚对master_ip_online_failover 的注释并测试:
再次检查MHA check
[root@MHA-S2 bin]# masterha_check_repl --conf=/etc/mha/app1.cnf
Wed Aug 9 10:49:42 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Wed Aug 9 10:49:42 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Wed Aug 9 10:49:42 2017 - [info] Reading server configuration from /etc/mha/app1.cnf..
Wed Aug 9 10:49:42 2017 - [info] MHA::MasterMonitor version 0.57.
Wed Aug 9 10:49:43 2017 - [info] GTID failover mode = 1Wed Aug 9 10:49:43 2017 - [info] Dead Servers:
Wed Aug 9 10:49:43 2017 - [info] Alive Servers:
Wed Aug 9 10:49:43 2017 - [info] MHA-M1(10.180.2.163:3306)
Wed Aug 9 10:49:43 2017 - [info] MHA-S1(10.180.2.164:3306)
Wed Aug 9 10:49:43 2017 - [info] MHA-S2(10.180.2.165:3306)
Wed Aug 9 10:49:43 2017 - [info] Alive Slaves:
Wed Aug 9 10:49:43 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 10:49:43 2017 - [info] GTID ON
Wed Aug 9 10:49:43 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 10:49:43 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Aug 9 10:49:43 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 10:49:43 2017 - [info] GTID ON
Wed Aug 9 10:49:43 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 10:49:43 2017 - [info] Current Alive Master: MHA-M1(10.180.2.163:3306)
Wed Aug 9 10:49:43 2017 - [info] Checking slave configurations..
Wed Aug 9 10:49:43 2017 - [info] Checking replication filtering settings..
Wed Aug 9 10:49:43 2017 - [info] binlog_do_db= , binlog_ignore_db= Wed Aug 9 10:49:43 2017 - [info] Replication filtering check ok.
Wed Aug 9 10:49:43 2017 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Wed Aug 9 10:49:43 2017 - [info] Checking SSH publickey authentication settings on the current master..
Wed Aug 9 10:49:43 2017 - [info] HealthCheck: SSH to MHA-M1 is reachable.
Wed Aug 9 10:49:43 2017 - [info]
MHA-M1(10.180.2.163:3306) (current master) +--MHA-S1(10.180.2.164:3306) +--MHA-S2(10.180.2.165:3306)
Wed Aug 9 10:49:43 2017 - [info] Checking replication health on MHA-S1..
Wed Aug 9 10:49:43 2017 - [info] ok.
Wed Aug 9 10:49:43 2017 - [info] Checking replication health on MHA-S2..
Wed Aug 9 10:49:43 2017 - [info] ok.
Wed Aug 9 10:49:43 2017 - [info] Checking master_ip_failover_script status:
Wed Aug 9 10:49:43 2017 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=MHA-M1 --orig_master_ip=10.180.2.163 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ifconfig eth2:1 down==/sbin/ifconfig eth2:1 10.180.2.168/19=== Checking the Status of the script.. OK
Wed Aug 9 10:49:43 2017 - [info] OK.
Wed Aug 9 10:49:43 2017 - [warning] shutdown_script is not defined.
Wed Aug 9 10:49:43 2017 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
以上就是MHA 安装配置的全过程,以下进行简单的测试。 (1)failover 测试 手动kill 了master 上面的mysqld 进程,查看切换状态
[root@MHA-S2 tmp]# more manager.log
Wed Aug 9 17:47:11 2017 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away)
Wed Aug 9 17:47:11 2017 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s MHA-S1 -s MHA-S2 --user=root --master_host=MHA-M1 --master_ip=10.180.2.163 --master_port=3306 --master_user=root --master_password=123456 --ping_type=SELECT
Wed Aug 9 17:47:11 2017 - [info] Executing SSH check script: exit 0Wed Aug 9 17:47:11 2017 - [info] HealthCheck: SSH to MHA-M1 is reachable.
Monitoring server MHA-S1 is reachable, Master is not reachable from MHA-S1. OK.
Monitoring server MHA-S2 is reachable, Master is not reachable from MHA-S2. OK.
Wed Aug 9 17:47:11 2017 - [info] Master is not reachable from all other monitoring servers. Failover should start.
Wed Aug 9 17:47:12 2017 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at 'reading initial communication packet', system error: 111)
Wed Aug 9 17:47:12 2017 - [warning] Connection failed 2 time(s)..
Wed Aug 9 17:47:13 2017 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at 'reading initial communication packet', system error: 111)
Wed Aug 9 17:47:13 2017 - [warning] Connection failed 3 time(s)..
Wed Aug 9 17:47:14 2017 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at 'reading initial communication packet', system error: 111)
Wed Aug 9 17:47:14 2017 - [warning] Connection failed 4 time(s)..
Wed Aug 9 17:47:14 2017 - [warning] Master is not reachable from health checker!Wed Aug 9 17:47:14 2017 - [warning] Master MHA-M1(10.180.2.163:3306) is not reachable!Wed Aug 9 17:47:14 2017 - [warning] SSH is reachable.
Wed Aug 9 17:47:14 2017 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/app1.cnf again, and tryin
g to connect to all servers to check server status..
Wed Aug 9 17:47:14 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Wed Aug 9 17:47:14 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Wed Aug 9 17:47:14 2017 - [info] Reading server configuration from /etc/mha/app1.cnf..
Wed Aug 9 17:47:14 2017 - [info] GTID failover mode = 1Wed Aug 9 17:47:14 2017 - [info] Dead Servers:
Wed Aug 9 17:47:14 2017 - [info] MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Alive Servers:
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306)
Wed Aug 9 17:47:14 2017 - [info] MHA-S2(10.180.2.165:3306)
Wed Aug 9 17:47:14 2017 - [info] Alive Slaves:
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Aug 9 17:47:14 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Checking slave configurations..
Wed Aug 9 17:47:14 2017 - [info] Checking replication filtering settings..
Wed Aug 9 17:47:14 2017 - [info] Replication filtering check ok.
Wed Aug 9 17:47:14 2017 - [info] Master is down!Wed Aug 9 17:47:14 2017 - [info] Terminating monitoring script.
Wed Aug 9 17:47:14 2017 - [info] Got exit code 20 (Master dead).
Wed Aug 9 17:47:14 2017 - [info] MHA::MasterFailover version 0.57.
Wed Aug 9 17:47:14 2017 - [info] Starting master failover.
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 1: Configuration Check Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] GTID failover mode = 1Wed Aug 9 17:47:14 2017 - [info] Dead Servers:
Wed Aug 9 17:47:14 2017 - [info] MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Checking master reachability via MySQL(double check)...
Wed Aug 9 17:47:14 2017 - [info] ok.
Wed Aug 9 17:47:14 2017 - [info] Alive Servers:
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306)
Wed Aug 9 17:47:14 2017 - [info] MHA-S2(10.180.2.165:3306)
Wed Aug 9 17:47:14 2017 - [info] Alive Slaves:
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Aug 9 17:47:14 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Starting GTID based failover.
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] ** Phase 1: Configuration Check Phase completed.
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 2: Dead Master Shutdown Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] Forcing shutdown so that applications never connect to the current master..
Wed Aug 9 17:47:14 2017 - [info] Executing master IP deactivation script:
Wed Aug 9 17:47:14 2017 - [info] /usr/local/bin/master_ip_failover --orig_master_host=MHA-M1 --orig_master_ip=10.180.2.163 --orig_master_port=3306 --command=stopssh --ssh_user=root
IN SCRIPT TEST====/sbin/ifconfig eth2:1 down==/sbin/ifconfig eth2:1 10.180.2.168/24===Disabling the VIP on old master: MHA-M1
SiocSIFFLAGS: Cannot assign requested address
Wed Aug 9 17:47:14 2017 - [info] done.
Wed Aug 9 17:47:14 2017 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Wed Aug 9 17:47:14 2017 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 3: Master Recovery Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] The latest binary log file/position on all slaves is 3306-binlog.000003:194Wed Aug 9 17:47:14 2017 - [info] Retrieved Gtid Set: a5757eae-7981-11e7-82c7-005056b662d3:6-32210Wed Aug 9 17:47:14 2017 - [info] Latest slaves (Slaves that received relay log files to the latest):
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Aug 9 17:47:14 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] The oldest binary log file/position on all slaves is 3306-binlog.000003:194Wed Aug 9 17:47:14 2017 - [info] Retrieved Gtid Set: a5757eae-7981-11e7-82c7-005056b662d3:6-32210Wed Aug 9 17:47:14 2017 - [info] Oldest slaves:
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Aug 9 17:47:14 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 3.3: Determining New Master Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] Searching new master from slaves..
Wed Aug 9 17:47:14 2017 - [info] Candidate masters from the configuration file:
Wed Aug 9 17:47:14 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Wed Aug 9 17:47:14 2017 - [info] GTID ON
Wed Aug 9 17:47:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306)
Wed Aug 9 17:47:14 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Aug 9 17:47:14 2017 - [info] Non-candidate masters:
Wed Aug 9 17:47:14 2017 - [info] Searching from candidate_master slaves which have received the latest relay log events..
Wed Aug 9 17:47:14 2017 - [info] New master is MHA-S1(10.180.2.164:3306)
Wed Aug 9 17:47:14 2017 - [info] Starting master failover..
Wed Aug 9 17:47:14 2017 - [info]
From:
MHA-M1(10.180.2.163:3306) (current master) +--MHA-S1(10.180.2.164:3306) +--MHA-S2(10.180.2.165:3306)
To:
MHA-S1(10.180.2.164:3306) (new master) +--MHA-S2(10.180.2.165:3306)
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 3.3: New Master Recovery Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] Waiting all logs to be applied..
Wed Aug 9 17:47:14 2017 - [info] done.
Wed Aug 9 17:47:14 2017 - [info] Getting new master's binlog name and position..Wed Aug 9 17:47:14 2017 - [info] 3306-binlog.000003:61944788Wed Aug 9 17:47:14 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='MHA-S1 or 10.180.2.164', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MAS
TER_USER='repl', MASTER_PASSWORD='xxx';
Wed Aug 9 17:47:14 2017 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: 3306-binlog.000003, 61944788, 1c2dc99f-7b57-11e7-a280-005056b665cb:1-2,
a5757eae-7981-11e7-82c7-005056b662d3:1-32210Wed Aug 9 17:47:14 2017 - [info] Executing master IP activate script:
Wed Aug 9 17:47:14 2017 - [info] /usr/local/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=MHA-M1 --orig_master_ip=10.180.2.163 --orig_master_port=3306 --new_master_host=MHA-S1 --new_master_ip=10.180.2.164 --new_master_port=3306 --new_master_user='root' --new_master_password=xxx
Unknown option: new_master_user
Unknown option: new_master_password
IN SCRIPT TEST====/sbin/ifconfig eth2:1 down==/sbin/ifconfig eth2:1 10.180.2.168/24===Enabling the VIP - 10.180.2.168/24 on the new master - MHA-S1
Wed Aug 9 17:47:14 2017 - [info] OK.
Wed Aug 9 17:47:14 2017 - [info] Setting read_only=0 on MHA-S1(10.180.2.164:3306)..
Wed Aug 9 17:47:14 2017 - [info] ok.
Wed Aug 9 17:47:14 2017 - [info] ** Finished master recovery successfully.
Wed Aug 9 17:47:14 2017 - [info] * Phase 3: Master Recovery Phase completed.
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 4: Slaves Recovery Phase..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] * Phase 4.1: Starting Slaves in parallel..
Wed Aug 9 17:47:14 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] -- Slave recovery on host MHA-S2(10.180.2.165:3306) started, pid: 18757. Check tmp log /var/log/masterha/app1/MHA-S2_3306_20170809174714.log if it takes time..
Wed Aug 9 17:47:15 2017 - [info]
Wed Aug 9 17:47:15 2017 - [info] Log messages from MHA-S2 ...
Wed Aug 9 17:47:15 2017 - [info]
Wed Aug 9 17:47:14 2017 - [info] Resetting slave MHA-S2(10.180.2.165:3306) and starting replication from the new master MHA-S1(10.180.2.164:3306)..
Wed Aug 9 17:47:14 2017 - [info] Executed CHANGE MASTER.
Wed Aug 9 17:47:15 2017 - [info] Slave started.
Wed Aug 9 17:47:15 2017 - [info] gtid_wait(1c2dc99f-7b57-11e7-a280-005056b665cb:1-2,
a5757eae-7981-11e7-82c7-005056b662d3:1-32210) completed on MHA-S2(10.180.2.165:3306). Executed 0 events.
Wed Aug 9 17:47:15 2017 - [info] End of log messages from MHA-S2.
Wed Aug 9 17:47:15 2017 - [info] -- Slave on host MHA-S2(10.180.2.165:3306) started.
Wed Aug 9 17:47:15 2017 - [info] All new slave servers recovered successfully.
Wed Aug 9 17:47:15 2017 - [info]
Wed Aug 9 17:47:15 2017 - [info] * Phase 5: New master cleanup phase..
Wed Aug 9 17:47:15 2017 - [info]
Wed Aug 9 17:47:15 2017 - [info] Resetting slave info on the new master..
Wed Aug 9 17:47:15 2017 - [info] MHA-S1: Resetting slave info succeeded.
Wed Aug 9 17:47:15 2017 - [info] Master failover to MHA-S1(10.180.2.164:3306) completed successfully.
Wed Aug 9 17:47:15 2017 - [info] Deleted server1 entry from /etc/mha/app1.cnf .
Wed Aug 9 17:47:15 2017 - [info]
----- Failover Report -----app1: MySQL Master failover MHA-M1(10.180.2.163:3306) to MHA-S1(10.180.2.164:3306) succeeded
Master MHA-M1(10.180.2.163:3306) is down!Check MHA Manager logs at MHA-S2:/var/log/masterha/app1/manager.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on MHA-M1(10.180.2.163:3306)
Selected MHA-S1(10.180.2.164:3306) as a new master.
MHA-S1(10.180.2.164:3306): OK: Applying all logs succeeded.
MHA-S1(10.180.2.164:3306): OK: Activated master IP address.
MHA-S2(10.180.2.165:3306): OK: Slave started, replicating from MHA-S1(10.180.2.164:3306)
MHA-S1(10.180.2.164:3306): Resetting slave info succeeded.
Master failover to MHA-S1(10.180.2.164:3306) completed successfully.
Wed Aug 9 17:47:15 2017 - [info] Sending mail..
Unknown option: conf
以上是切换的全日志过程,我们可以看到MHA 切换主要经历以下步骤: 1.配置文件检查阶段,这个阶段会检查整个集群配置文件配置 2.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作(这个我这里还没有实现,需要研究) 3.复制dead maste和最新slave相差的relay log,并保存到MHA Manger具体的目录下 4.识别含有最新更新的slave 5.应用从master保存的二进制日志事件(binlog events) 6.提升一个slave为新的master进行复制 7.使其他的slave连接新的master进行复制 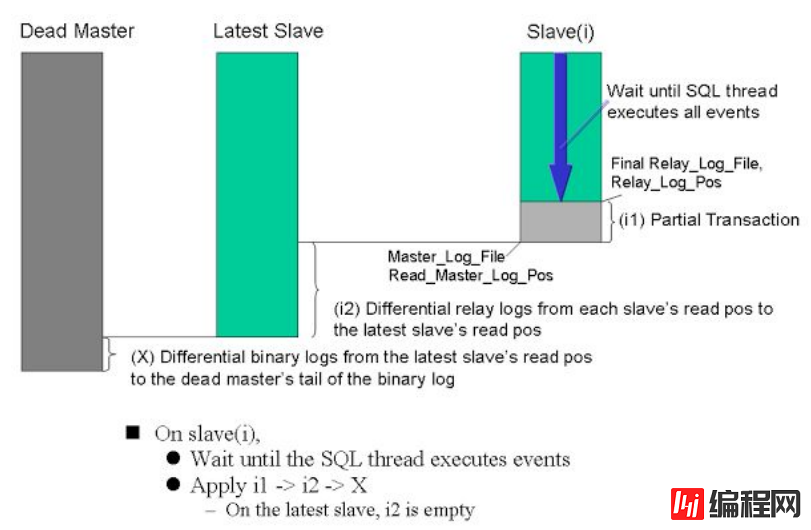
注意: 1. 切换完之后你会发现MHA Manager 监控程序会自动死掉,官网有如下解释和解决方式: Running MHA Manager from daemontoolsCurrently MHA Manager process does not run as a daemon. If failover completed successfully or the master process was killed by accident, the manager stops working. To run as a daemon, daemontool. or any external daemon program can be used. Here is an example to run from daemontools.
这里我们用shell 脚本的方式去执行就不会发生监控程序死掉的情况 [root@MHA-S2 bin]# more manager.sh #!/bin/shnohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
2. 当你修复完死掉的master想重新加入先有的两节点MHA 也是可以的 旧Master :
root@localhost:mysql3306.sock [tt]>show master status\G*************************** 1. row ***************************
File: 3306-binlog.000004
Position: 194
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: a5757eae-7981-11e7-82c7-005056b662d3:1-322101 row in set (0.00 sec)
现有master:
root@localhost:mysql3306.sock [tt]>show master status\G*************************** 1. row ***************************
File: 3306-binlog.000003
Position: 61945043
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 1c2dc99f-7b57-11e7-a280-005056b665cb:1-3,
a5757eae-7981-11e7-82c7-005056b662d3:1-322101 row in set (0.00 sec)
由于有GTID,我们可以直接就change master 切换过去,先对比一下数据: 旧master:
root@localhost:mysql3306.sock [tt]>select * from t1;+----+------+
| id | c1 |
+----+------+
| 1 | a1 |
| 2 | a2 |
| 3 | a3 |
| 4 | a4 |
+----+------+4 rows in set (0.02 sec)
新master:
root@localhost:mysql3306.sock [tt]>select * from t1;+----+------+
| id | c1 |
+----+------+
| 1 | a1 |
| 2 | a2 |
| 3 | a3 |
| 4 | a4 |
| 5 | a5 |+----+------+
旧master 直接change master to: change master to master_host='MHA-S1',master_user='repl',master_password='123456',master_port=3306,master_auto_position=1;
start slave 看输出:
root@localhost:mysql3306.sock [tt]>show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: MHA-S1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: 3306-binlog.000003
Read_Master_Log_Pos: 61945043
Relay_Log_File: MHA-M1-relay-bin.000004
Relay_Log_Pos: 715
Relay_Master_Log_File: 3306-binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
看是否会补全数据:
root@localhost:mysql3306.sock [tt]>select * from t1;+----+------+
| id | c1 |
+----+------+
| 1 | a1 |
| 2 | a2 |
| 3 | a3 |
| 4 | a4 |
| 5 | a5 |
+----+------+
发现数据补全了,加入复制没问题。 最后还得修改app1.cnf 把server1 补上 [server1]hostname=MHA-M1
port=3306
重启监控程序并查看MHA 状态
[root@MHA-S2 tmp]# masterha_check_repl --conf=/etc/mha/app1.cnf
Sat Aug 12 20:37:01 2017 - [info] Replication filtering check ok.
Sat Aug 12 20:37:01 2017 - [error][/usr/local/share/perl5/MHA/Server.pm, ln398] MHA-M1(10.180.2.163:3306): User repl does not exist or does not have REPLICATION SLAVE privilege! Other slaves can not start replication from this host.
Sat Aug 12 20:37:01 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/local/share/perl5/MHA/ServerManager.pm line 1403
Sat Aug 12 20:37:01 2017 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
Sat Aug 12 20:37:01 2017 - [info] Got exit code 1 (Not master dead).
发现权限有问题,赶紧修复一下: MHA-M1: set session sql_log_bin=OFF;
grant replication slave on *.* to repl@'%' identified by '123456';
set session sql_log_bin=ON;
再次执行MHA 状态检查:
masterha_check_repl --conf=/etc/mha/app1.cnf
Sat Aug 12 20:41:14 2017 - [info] Checking replication health on MHA-M1..
Sat Aug 12 20:41:14 2017 - [info] ok.
Sat Aug 12 20:41:14 2017 - [info] Checking replication health on MHA-S2..
Sat Aug 12 20:41:14 2017 - [info] ok.
Sat Aug 12 20:41:14 2017 - [info] Checking master_ip_failover_script status:
Sat Aug 12 20:41:14 2017 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=MHA-S1 --orig_master_ip=10.180.2.164 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth2:1 down==/sbin/ifconfig eth2:1 10.180.2.168/24===Checking the Status of the script.. OK
Sat Aug 12 20:41:15 2017 - [info] OK.
Sat Aug 12 20:41:15 2017 - [warning] shutdown_script is not defined.
Sat Aug 12 20:41:15 2017 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
最后启动监控程序 [root@MHA-S2 bin]# nohup monitor.sh &[root@MHA-S2 bin]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:32084) is running(0:PING_OK), master:MHA-S1
(2)手动在线切换测试 在许多情况下, 需要将现有的主服务器迁移到另外一台服务器上。 比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。 MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器 注意,在线切换的时候应用架构需要考虑以下两个问题: 1.自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。 2.负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题) 为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。 1.所有slave的IO线程都在运行 2.所有slave的SQL线程都在运行 3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。 4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。 在线切换步骤如下: 先停止监控程序 [root@MHA-S2 app1]# masterha_stop --conf=/etc/mha/app1.cnf
Stopped app1 successfully.
修改master_ip_online_change脚本如下:
[root@MHA-S2 bin]# more master_ip_online_change
#!/usr/bin/env perl# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can Redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofday tv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_host, $orig_master_ip,
$orig_master_port, $orig_master_user,
$new_master_host, $new_master_ip, $new_master_port,
$new_master_user,
);
my $vip = '10.180.2.168/19'; # Virtual IP
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth2:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth2:$key down";
my $ssh_user = "root";
my $new_master_password='123456';
my $orig_master_password='123456';
GetOptions( 'command=s' => \$command,
#'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'orig_master_user=s' => \$orig_master_user,
#'orig_master_password=s' => \$orig_master_password, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user,
#'new_master_password=s' => \$new_master_password,
);
exit &main();
sub current_time_us {
my ( $sec, $microsec ) = gettimeofday();
my $curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec );
}
sub sleep_until {
my $elapsed = tv_interval($_tstart); if ( $_running_interval > $elapsed ) { sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my $dbh = shift;
my $my_connection_id = shift;
my $running_time_threshold = shift;
my $type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless ($type);
my @threads;
my $sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute(); while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command = $ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time < $running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next if ( defined($command) && $command eq "Sleep"
&& defined($query_time) && $query_time >= 1 ); if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect" );
} if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main { if ( $command eq "stop" ) {
## Gracefully killing connections on the current master
# 1. Set read_only= 1 on the new master
# 2. DROP USER so that no app user can establish new connections
# 3. Set read_only= 1 on the current master
# 4. Kill current queries
# * Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master.. ";
$new_master_handler->enable_read_only(); if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
} else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
#$orig_master_handler->disable_log_bin_local();
#print current_time_us() . " Drpping app user on the orig master..\n";
#FIXME_xxx_drop_app_user($orig_master_handler);
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} ); while ( $time_until_read_only > 0 && $#threads >= 0 ) { if ( $time_until_read_only % 5 == 0 ) {
printf"%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100; if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(except SUPER) can write
print current_time_us() . " Set read_only=1 on the orig master.. ";
$orig_master_handler->enable_read_only(); if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
} else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries can complete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} ); while ( $time_until_kill_threads > 0 && $#threads >= 0 ) { if ( $time_until_kill_threads % 5 == 0 ) {
printf"%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100; if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip();
## Terminating all threads
print current_time_us() . " Killing all application threads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
print current_time_us() . " done.\n";
#$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
$exit_code = 0;
}; if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
# 1. Create app user with write privileges
# 2. Moving backup script if needed
# 3. ReGISter new master's ip to the catalog database# We don't return error even though activating updatable accounts/ip failed so that we don't interrupt slaves' recovery.# If exit code is 0 or 10, MHA does not abort
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
#$new_master_handler->disable_log_bin_local();
print current_time_us() . " Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
#print current_time_us() . " Creating app user on the new master..\n";
#FIXME_xxx_create_app_user($new_master_handler);
#$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip();
$exit_code = 0;
}; if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
exit 0;
} else { &usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;}
sub usage {
print"Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
die;
}
执行切换 [root@MHA-S2 tmp]# masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=MHA-M1 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
其中参数的意思: --orig_master_is_new_slave 切换时加上此参数是将原 master 变为 slave 节点,如果不加此参数,原来的 master 将不启动 --running_updates_limit=10000,故障切换时,候选master 如果有延迟的话, mha 切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover 时relay 日志的大小决定 查看切换后各机器的状态: S2:
root@localhost:mysql3306.sock [tt]>show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: MHA-M1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: 3306-binlog.000004
Read_Master_Log_Pos: 748
Relay_Log_File: MHA-S2-relay-bin.000002
Relay_Log_Pos: 420
Relay_Master_Log_File: 3306-binlog.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
S1:
root@localhost:mysql3306.sock [tt]>show slave status\G*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: MHA-M1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: 3306-binlog.000004
Read_Master_Log_Pos: 748
Relay_Log_File: MHA-S1-relay-bin.000002
Relay_Log_Pos: 420
Relay_Master_Log_File: 3306-binlog.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
M1: root@localhost:mysql3306.sock [tt]>show slave status\G
Empty set (0.00 sec)
在线切换的日志:
[root@MHA-S2 tmp]# more sw.log
[root@MHA-S2 bin]# masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=MHA-M1 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000Sat Aug 12 21:34:54 2017 - [info] MHA::MasterRotate version 0.57.
Sat Aug 12 21:34:54 2017 - [info] Starting online master switch..
Sat Aug 12 21:34:54 2017 - [info]
Sat Aug 12 21:34:54 2017 - [info] * Phase 1: Configuration Check Phase..
Sat Aug 12 21:34:54 2017 - [info]
Sat Aug 12 21:34:54 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 12 21:34:54 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Sat Aug 12 21:34:54 2017 - [info] Reading server configuration from /etc/mha/app1.cnf..
Sat Aug 12 21:34:54 2017 - [info] GTID failover mode = 1Sat Aug 12 21:34:54 2017 - [info] Current Alive Master: MHA-S1(10.180.2.164:3306)
Sat Aug 12 21:34:54 2017 - [info] Alive Slaves:
Sat Aug 12 21:34:54 2017 - [info] MHA-M1(10.180.2.163:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Sat Aug 12 21:34:54 2017 - [info] GTID ON
Sat Aug 12 21:34:54 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306)
Sat Aug 12 21:34:54 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled
Sat Aug 12 21:34:54 2017 - [info] GTID ON
Sat Aug 12 21:34:54 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306)
It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on MHA-S1(10.180.2.164:3306)? (YES/no): yes
Sat Aug 12 21:35:07 2017 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..
Sat Aug 12 21:35:07 2017 - [info] ok.
Sat Aug 12 21:35:07 2017 - [info] Checking MHA is not monitoring or doing failover..
Sat Aug 12 21:35:07 2017 - [info] Checking replication health on MHA-M1..
Sat Aug 12 21:35:07 2017 - [info] ok.
Sat Aug 12 21:35:07 2017 - [info] Checking replication health on MHA-S2..
Sat Aug 12 21:35:07 2017 - [info] ok.
Sat Aug 12 21:35:07 2017 - [info] MHA-M1 can be new master.
Sat Aug 12 21:35:07 2017 - [info]
From:
MHA-S1(10.180.2.164:3306) (current master) +--MHA-M1(10.180.2.163:3306) +--MHA-S2(10.180.2.165:3306)
To:
MHA-M1(10.180.2.163:3306) (new master) +--MHA-S2(10.180.2.165:3306) +--MHA-S1(10.180.2.164:3306)
Starting master switch from MHA-S1(10.180.2.164:3306) to MHA-M1(10.180.2.163:3306)? (yes/NO): yes
Sat Aug 12 21:35:15 2017 - [info] Checking whether MHA-M1(10.180.2.163:3306) is ok for the new master..
Sat Aug 12 21:35:15 2017 - [info] ok.
Sat Aug 12 21:35:15 2017 - [info] MHA-S1(10.180.2.164:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host.
Sat Aug 12 21:35:15 2017 - [info] MHA-S1(10.180.2.164:3306): Resetting slave pointing to the dummy host.
Sat Aug 12 21:35:15 2017 - [info] ** Phase 1: Configuration Check Phase completed.
Sat Aug 12 21:35:15 2017 - [info]
Sat Aug 12 21:35:15 2017 - [info] * Phase 2: Rejecting updates Phase..
Sat Aug 12 21:35:15 2017 - [info]
Sat Aug 12 21:35:15 2017 - [info] Executing master ip online change script to disable write on the current master:
Sat Aug 12 21:35:15 2017 - [info] /usr/local/bin/master_ip_online_change --command=stop --orig_master_host=MHA-S1 --orig_master_ip=10.180.2.164 --orig_master_port=3306 --orig_master_user='root' --new_master_
host=MHA-M1 --new_master_ip=10.180.2.163 --new_master_port=3306 --new_master_user='root' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_mas
ter_password=xxx
Unknown option: orig_master_ssh_user
Unknown option: new_master_ssh_user
Unknown option: orig_master_is_new_slave
Unknown option: orig_master_password
Unknown option: new_master_password
Sat Aug 12 21:35:15 2017 568580 Set read_only on the new master.. ok.
Sat Aug 12 21:35:15 2017 573508 Waiting all running 2 threads are disconnected.. (max 1500 milliseconds)
{'Time' => '272878','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '40','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-S2:46970'}{'Time' => '3738','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '55','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-M1:51506'}
Sat Aug 12 21:35:16 2017 075020 Waiting all running 2 threads are disconnected.. (max 1000 milliseconds)
{'Time' => '272879','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '40','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-S2:46970'}{'Time' => '3739','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '55','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-M1:51506'}
Sat Aug 12 21:35:16 2017 576059 Waiting all running 2 threads are disconnected.. (max 500 milliseconds)
{'Time' => '272879','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '40','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-S2:46970'}{'Time' => '3739','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '55','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-M1:51506'}
Sat Aug 12 21:35:17 2017 076940 Set read_only=1 on the orig master.. ok.
Sat Aug 12 21:35:17 2017 079645 Waiting all running 2 queries are disconnected.. (max 500 milliseconds)
{'Time' => '272880','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '40','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-S2:46970'}{'Time' => '3740','Command' => 'Binlog Dump GTID','db' => undef,'Id' => '55','Info' => undef,'User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Host' => 'MHA-M1:51506'}
Disabling the VIP on old master: MHA-S1
Sat Aug 12 21:35:17 2017 683769 Killing all application threads..
Sat Aug 12 21:35:17 2017 686090 done.
Sat Aug 12 21:35:17 2017 - [info] ok.
Sat Aug 12 21:35:17 2017 - [info] Locking all tables on the orig master to reject updates from everybody (including root):
Sat Aug 12 21:35:17 2017 - [info] Executing FLUSH TABLES WITH READ LOCK..
Sat Aug 12 21:35:17 2017 - [info] ok.
Sat Aug 12 21:35:17 2017 - [info] Orig master binlog:pos is 3306-binlog.000003:61945043.
Sat Aug 12 21:35:17 2017 - [info] Waiting to execute all relay logs on MHA-M1(10.180.2.163:3306)..
Sat Aug 12 21:35:17 2017 - [info] master_pos_wait(3306-binlog.000003:61945043) completed on MHA-M1(10.180.2.163:3306). Executed 0 events.
Sat Aug 12 21:35:17 2017 - [info] done.
Sat Aug 12 21:35:17 2017 - [info] Getting new master's binlog name and position..Sat Aug 12 21:35:17 2017 - [info] 3306-binlog.000004:748Sat Aug 12 21:35:17 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='MHA-M1 or 10.180.2.163', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MAS
TER_USER='repl', MASTER_PASSWORD='xxx';
Sat Aug 12 21:35:17 2017 - [info] Executing master ip online change script to allow write on the new master:
Sat Aug 12 21:35:17 2017 - [info] /usr/local/bin/master_ip_online_change --command=start --orig_master_host=MHA-S1 --orig_master_ip=10.180.2.164 --orig_master_port=3306 --orig_master_user='root' --new_master
_host=MHA-M1 --new_master_ip=10.180.2.163 --new_master_port=3306 --new_master_user='root' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_ma
ster_password=xxx
Unknown option: orig_master_ssh_user
Unknown option: new_master_ssh_user
Unknown option: orig_master_is_new_slave
Unknown option: orig_master_password
Unknown option: new_master_password
Sat Aug 12 21:35:17 2017 865209 Set read_only=0 on the new master.
Enabling the VIP - 10.180.2.168/19 on the new master - MHA-M1
Sat Aug 12 21:35:17 2017 - [info] ok.
Sat Aug 12 21:35:17 2017 - [info]
Sat Aug 12 21:35:17 2017 - [info] * Switching slaves in parallel..
Sat Aug 12 21:35:17 2017 - [info]
Sat Aug 12 21:35:17 2017 - [info] -- Slave switch on host MHA-S2(10.180.2.165:3306) started, pid: 2327Sat Aug 12 21:35:17 2017 - [info]
Sat Aug 12 21:35:18 2017 - [info] Log messages from MHA-S2 ...
Sat Aug 12 21:35:18 2017 - [info]
Sat Aug 12 21:35:18 2017 - [info] Waiting to execute all relay logs on MHA-S2(10.180.2.165:3306)..
Sat Aug 12 21:35:18 2017 - [info] master_pos_wait(3306-binlog.000003:61945043) completed on MHA-S2(10.180.2.165:3306). Executed 0 events.
Sat Aug 12 21:35:18 2017 - [info] done.
Sat Aug 12 21:35:18 2017 - [info] Resetting slave MHA-S2(10.180.2.165:3306) and starting replication from the new master MHA-M1(10.180.2.163:3306)..
Sat Aug 12 21:35:18 2017 - [info] Executed CHANGE MASTER.
Sat Aug 12 21:35:18 2017 - [info] Slave started.
Sat Aug 12 21:35:18 2017 - [info] End of log messages from MHA-S2 ...
Sat Aug 12 21:35:18 2017 - [info]
Sat Aug 12 21:35:18 2017 - [info] -- Slave switch on host MHA-S2(10.180.2.165:3306) succeeded.
Sat Aug 12 21:35:18 2017 - [info] Unlocking all tables on the orig master:
Sat Aug 12 21:35:18 2017 - [info] Executing UNLOCK TABLES..
Sat Aug 12 21:35:18 2017 - [info] ok.
Sat Aug 12 21:35:18 2017 - [info] Starting orig master as a new slave..
Sat Aug 12 21:35:18 2017 - [info] Resetting slave MHA-S1(10.180.2.164:3306) and starting replication from the new master MHA-M1(10.180.2.163:3306)..
Sat Aug 12 21:35:18 2017 - [info] Executed CHANGE MASTER.
Sat Aug 12 21:35:19 2017 - [info] Slave started.
Sat Aug 12 21:35:19 2017 - [info] All new slave servers switched successfully.
Sat Aug 12 21:35:19 2017 - [info]
Sat Aug 12 21:35:19 2017 - [info] * Phase 5: New master cleanup phase..
Sat Aug 12 21:35:19 2017 - [info]
Sat Aug 12 21:35:19 2017 - [info] MHA-M1: Resetting slave info succeeded.
Sat Aug 12 21:35:19 2017 - [info] Switching master to MHA-M1(10.180.2.163:3306) completed successfully.
| 




0