这篇文章主要讲解了“分析postgresql中的数据结构HTAB”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“分析Postgresql中的数据结构HTAB”
这篇文章主要讲解了“分析postgresql中的数据结构HTAB”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“分析Postgresql中的数据结构HTAB”吧!
struct HTAB
{
//指向共享的控制信息
HASHHDR *hctl;
//段目录
HASHSEGMENT *dir;
//哈希函数
HashValueFunc hash;
//哈希键比较函数
HashCompareFunc match;
//哈希键拷贝函数
HashCopyFunc keycopy;
//内存分配器
HashAllocFunc alloc;
//内存上下文
MemoryContext hcxt;
//表名(用于错误信息)
char *tabname;
//如在共享内存中,则为T
bool isshared;
//如为T,则固定大小不能扩展
bool isfixed;
//不允许冻结共享表,因此这里会保存相关状态
bool frozen;
//保存这些固定值的本地拷贝,以减少冲突
//哈希键长度(以字节为单位)
Size keysize;
//段大小,必须为2的幂
long ssize;
//段偏移,ssize的对数
int sshift;
};
struct HASHHDR
{
//#define NUM_FREELISTS 32
FreeListData freeList[NUM_FREELISTS];
//这些域字段可以改变,但不适用于分区表
//同时,就算是非分区表,共享表的dsize也不能改变
//目录大小
long dsize;
//已分配的段大小(<= dsize)
long nsegs;
//正在使用的最大桶ID
uint32 max_bucket;
//进入整个哈希表的模掩码
uint32 high_mask;
//进入低位哈希表的模掩码
uint32 low_mask;
//下面这些字段在哈希表创建时已固定
//哈希键大小(以字节为单位)
Size keysize;
//所有用户元素大小(以字节为单位)
Size entrysize;
//分区个数(2的幂),或者为0
long num_partitions;
//目标的填充因子
long ffactor;
//如目录是固定大小,则该值为dsize的上限值
long max_dsize;
//段大小,必须是2的幂
long ssize;
//段偏移,ssize的对数
int sshift;
//一次性分配的条目个数
int nelem_alloc;
#ifdef HASH_STATISTICS
long accesses;
long collisions;
#endif
};
typedef struct
{
//该空闲链表的自旋锁
slock_t mutex;
//相关桶中的条目个数
long nentries;
//空闲元素链
HASHELEMENT *freeList;
} FreeListData;
typedef struct HASHELEMENT
{
//链接到相同桶中的下一个条目
struct HASHELEMENT *link;
//该条目的哈希函数结果
uint32 hashvalue;
} HASHELEMENT;
//哈希表头部结构,非透明类型,用于dynahash.c
typedef struct HASHHDR HASHHDR;
//哈希表控制结构,非透明类型,用于dynahash.c
typedef struct HTAB HTAB;
//hash_create使用的参数数据结构
//根据hash_flags标记设置相应的字段
typedef struct HASHCTL
{
//分区个数(必须是2的幂)
long num_partitions;
//段大小
long ssize;
//初始化目录大小
long dsize;
//dsize上限
long max_dsize;
//填充因子
long ffactor;
//哈希键大小(字节为单位)
Size keysize;
//参见上述数据结构注释
Size entrysize;
//
HashValueFunc hash;
HashCompareFunc match;
HashCopyFunc keycopy;
HashAllocFunc alloc;
MemoryContext hcxt;
//共享内存中的哈希头部结构地址
HASHHDR *hctl;
} HASHCTL;
//哈希桶是HASHELEMENTs链表
typedef HASHELEMENT *HASHBUCKET;
//hash segment是桶数组
typedef HASHBUCKET *HASHSEGMENT;
typedef uint32 (*HashValueFunc) (const void *key, Size keysize);
typedef int (*HashCompareFunc) (const void *key1, const void *key2,
Size keysize);
typedef void *(*HashCopyFunc) (void *dest, const void *src, Size keysize);
typedef void *(*HashAllocFunc) (Size request);其结构如下图所示: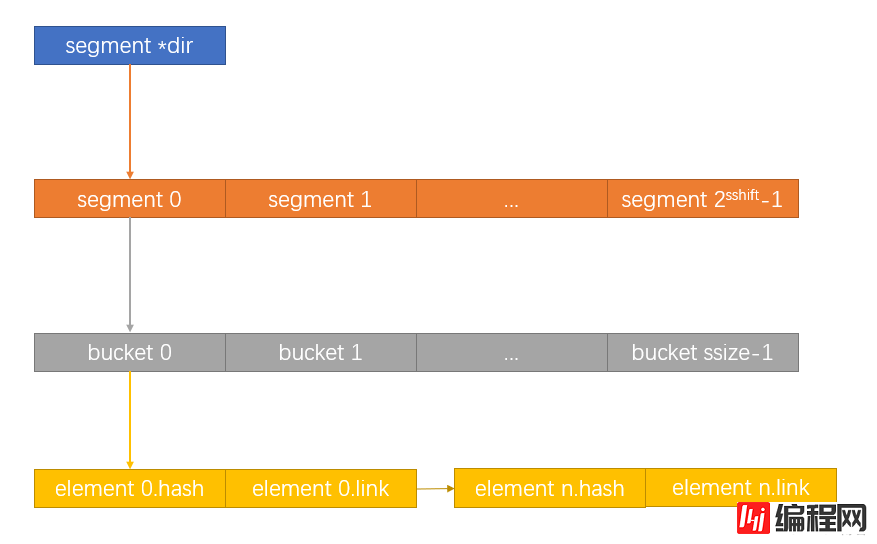
测试脚本
\pset footer off
\pset tuples_only on
\o /tmp/drop.sql
SELECT 'drop table if exists tbl' || id || ' ;' as "--"
FROM generate_series(1, 20000) AS id;
\i /tmp/drop.sql
\pset footer off
\pset tuples_only on
\o /tmp/create.sql
SELECT 'CREATE TABLE tbl' || id || ' (id int);' as "--"
FROM generate_series(1, 10000) AS id;
begin;
\o /tmp/ret.txt
\i /tmp/create.sql跟踪分析
...
HASHSEGMENT *dir --> HASHELEMENT ***dir;
dir --> HASHELEMENT ***
(gdb) p *hctl
$1 = {freeList = {{mutex = 0 '\000', nentries = 312, freeList = 0x7fd906ab84c0}, {mutex = 0 '\000',
nentries = 298, freeList = 0x7fd907097c40}, {mutex = 0 '\000', nentries = 292,
freeList = 0x7fd906ac2520}, {mutex = 0 '\000', nentries = 321, freeList = 0x7fd906ac8120}, {
mutex = 0 '\000', nentries = 341, freeList = 0x7fd907229980}, {mutex = 0 '\000', nentries = 334,
freeList = 0x7fd906ad3f08}, {mutex = 0 '\000', nentries = 316, freeList = 0x7fd906ad6fb8}, {
mutex = 0 '\000', nentries = 299, freeList = 0x7fd906ade550}, {mutex = 0 '\000', nentries = 328,
freeList = 0x7fd906ae1600}, {mutex = 0 '\000', nentries = 328, freeList = 0x7fd906ae62e8}, {
mutex = 0 '\000', nentries = 308, freeList = 0x7fd906aeb660}, {mutex = 0 '\000', nentries = 327,
freeList = 0x7fd90706f338}, {mutex = 0 '\000', nentries = 346, freeList = 0x7fd906af6bc0}, {
mutex = 0 '\000', nentries = 323, freeList = 0x7fd907237bc0}, {mutex = 0 '\000', nentries = 304,
freeList = 0x7fd9071ddb40}, {mutex = 0 '\000', nentries = 311, freeList = 0x7fd906b06238}, {
mutex = 0 '\000', nentries = 292, freeList = 0x7fd90707b620}, {mutex = 0 '\000', nentries = 303,
freeList = 0x7fd90723Dd20}, {mutex = 0 '\000', nentries = 302, freeList = 0x7fd906b137e0}, {
mutex = 0 '\000', nentries = 307, freeList = 0x7fd9070873c8}, {mutex = 0 '\000', nentries = 314,
freeList = 0x7fd90723bb68}, {mutex = 0 '\000', nentries = 279, freeList = 0x7fd906b22678}, {
mutex = 0 '\000', nentries = 297, freeList = 0x7fd907073e08}, {mutex = 0 '\000', nentries = 309,
freeList = 0x7fd90721f888}, {mutex = 0 '\000', nentries = 317, freeList = 0x7fd906b33880}, {
mutex = 0 '\000', nentries = 283, freeList = 0x7fd907086168}, {mutex = 0 '\000', nentries = 331,
freeList = 0x7fd906b3d838}, {mutex = 0 '\000', nentries = 330, freeList = 0x7fd906b41f38}, {
mutex = 0 '\000', nentries = 313, freeList = 0x7fd906b46440}, {mutex = 0 '\000', nentries = 304,
freeList = 0x7fd906b4b5c0}, {mutex = 0 '\000', nentries = 310, freeList = 0x7fd90720ed80}, {
mutex = 0 '\000', nentries = 323, freeList = 0x7fd906b575a0}}, dsize = 256, nsegs = 16,
max_bucket = 4095, high_mask = 8191, low_mask = 4095, keysize = 16, entrysize = 152, num_partitions = 16,
ffactor = 1, max_dsize = 256, ssize = 256, sshift = 8, nelem_alloc = 48}
(gdb) p *hashp
$2 = {hctl = 0x7fd906aae980, dir = 0x7fd906aaecd8, hash = 0xa79ac6 <tag_hash>, match = 0x47cb70 <memcmp@plt>,
keycopy = 0x47d0a0 <memcpy@plt>, alloc = 0x8c3419 <ShmemAllocNoError>, hcxt = 0x0,
tabname = 0x160f1d0 "LOCK hash", isshared = true, isfixed = false, frozen = false, keysize = 16,
ssize = 256, sshift = 8}
(gdb) p *hashp->dir
$3 = (HASHSEGMENT) 0x7fd906aaf500
(gdb) p hashp->dir
$4 = (HASHSEGMENT *) 0x7fd906aaecd8
(gdb) p **hashp->dir
$5 = (HASHBUCKET) 0x7fd907212dd0
(gdb) p ***hashp->dir
$6 = {link = 0x7fd9071a7b90, hashvalue = 1748602880}
(gdb) n
949 if (action == HASH_ENTER || action == HASH_ENTER_NULL)
(gdb)
956 if (!IS_PARTITIONED(hctl) && !hashp->frozen &&
(gdb)
965 bucket = calc_bucket(hctl, hashvalue); --> hash桶
(gdb)
967 segment_num = bucket >> hashp->sshift; --> 桶号右移8位得到段号
(gdb)
968 segment_ndx = MOD(bucket, hashp->ssize); --> 桶号取模得到段内偏移
(gdb)
970 segp = hashp->dir[segment_num]; --> 获取段(HASHELEMENT **)
(gdb)
972 if (segp == NULL)
(gdb) p bucket
$7 = 2072
(gdb) p segment_num
$8 = 8
(gdb) p segment_ndx
$9 = 24
(gdb) p segp -->
$10 = (HASHSEGMENT) 0x7fd906ab3500
(gdb)
(gdb) n
975 prevBucketPtr = &segp[segment_ndx]; --> HASHELEMENT **
(gdb)
976 currBucket = *prevBucketPtr; --> HASHELEMENT *
(gdb)
981 match = hashp->match;
(gdb) p prevBucketPtr
$12 = (HASHBUCKET *) 0x7fd906ab35c0
(gdb) p currBucket
$13 = (HASHBUCKET) 0x7fd90714da68
(gdb)感谢各位的阅读,以上就是“分析PostgreSQL中的数据结构HTAB”的内容了,经过本文的学习后,相信大家对分析PostgreSQL中的数据结构HTAB这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: 分析PostgreSQL中的数据结构HTAB
本文链接: https://lsjlt.com/news/63047.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0